
Dong Han, Joachim Denzler, Yong Li:
Realistic Face Reconstruction from Facial Embeddings via Diffusion Models.
AAAI Conference on Artificial Intelligence (AAAI).
2026.
[bibtex]
[web]
[doi]
[abstract]
With the advancement of face recognition (FR) systems, privacy-preserving face recognition (PPFR) systems have gained popularity for their accurate recognition, enhanced facial privacy protection, and robustness to various attacks. However, there are limited studies to further verify privacy risks by reconstructing realistic high-resolution face images from embeddings of these systems, especially for PPFR. In this work, we propose the face embedding mapping (FEM), a general framework that explores Kolmogorov-Arnold Network (KAN) for conducting the embedding-to-face attack by leveraging pre-trained Identity-Preserving diffusion model against state-of-the-art (SOTA) FR and PPFR systems. Based on extensive experiments, we verify that reconstructed faces can be used for accessing other real-word FR systems. Besides, the proposed method shows the robustness in reconstructing faces from the partial and protected face embeddings. Moreover, FEM can be utilized as a tool for evaluating safety of FR and PPFR systems in terms of privacy leakage. All images used in this work are from public datasets.
Felix Schneider, Joachim Denzler:
FreeStylo: An Easy-to-use Stylistic Device Detection Tool for Stylometry.
Journal of Open Source Software.
11 (117) :
pp. 7596.
2026.
[bibtex]
[pdf]
[doi]
[code]
[abstract]
An easy-to-use package for detecting stylistic devices in text. This package is designed to be used in stylometry, the study of linguistic style. For those proficient in python, this package provides a collection of approaches to detect stylistic devices in text. For those less proficient in python, this package provides a simple interface to detect stylistic devices in text with simple commands and user-friendly configuration.
Felix Schneider, Maria Gogolev, Sven Sickert, Joachim Denzler:
Beyond Subtokens: A Rich Character Embedding for Low-resource and Morphologically Complex Languages.
arXiv preprint arXiv:2602.21377.
2026.
[bibtex]
[doi]
[abstract]
Tokenization and sub-tokenization based models like word2vec, BERT and the GPTs are the state-of-the-art in natural language processing. Typically, these approaches have limitations with respect to their input representation. They fail to fully capture orthographic similarities and morphological variations, especially in highly inflected and under-resource languages. To mitigate this problem, we propose to computes word vectors directly from character strings, integrating both semantic and syntactic information. We denote this transformer-based approach Rich Character Embeddings (RCE). Furthermore, we propose a hybrid model that combines transformer and convolutional mechanisms. Both vector representations can be used as a drop-in replacement for dictionary- and subtoken-based word embeddings in existing model architectures. It has the potential to improve performance for both large context-based language models like BERT and small models like word2vec for under-resourced and morphologically rich languages. We evaluate our approach on various tasks like the SWAG, declension prediction for inflected languages, metaphor and chiasmus detection for various languages. Our experiments show that it outperforms traditional token-based approaches on limited data using OddOneOut and TopK metrics.

Gideon Stein, Niklas Penzel, Tristan Piater, Joachim Denzler:
TCD-Arena: Assessing Robustness of Time Series Causal Discovery Methods Against Assumption Violations.
International Conference on Learning Representations (ICLR).
2026.
(accepted)
[bibtex]
[web]
[abstract]
Causal Discovery (CD) is a powerful framework for scientific inquiry. Yet, its practical adoption is hindered by a reliance on strong, often unverifiable assumptions and a lack of robust performance assessment. To address these limitations and advance empirical CD evaluation, we present TCD-Arena, a modularized and extendable testing kit to assess the robustness of time series CD algorithms against stepwise more severe assumption violations. For demonstration, we conduct an extensive empirical study comprising arround 30 million individual CD attempts and reveal nuanced robustness profiles for 33 distinct assumption violations. Further, we investigate CD ensembles and find that they can boost general robustness, which has implications for real-world applications. With this, we strive to ultimately facilitate the development of CD methods that are reliable for a diverse range of synthetic and potentially real-world data conditions.
Laura Schieder, Nathalie Demme, Maha Shadaydeh, Claus Doerfel, Stella Jähkel, Joachim Denzler, Knut Holthoff, Hans Proquitté, Jürgen Graf:
Impact of Clinical Covariates on the Performance of an Automatic Sleep Stage Classification in Preterm Infants.
Somnologie.
2026.
[bibtex]
[doi]
[code]
[abstract]
Frequent sleep disruption in preterm infants in neonatal intensive care units (NICU) is suspected to be associated with adverse neurodevelopmental outcomes. A continuous, noninvasive sleep monitoring solution could optimise care by aligning interventions with natural sleep–wake cycles. The algorithm for automatic sleep stage classification by Demme et al. [5] offers a promising approach, with an accuracy of 92.2+-0.01\% compared to sleep stages measured in the sleep laboratory.
Ming Wei, Sven Sickert, Tim Büchner, Yaoyuan Zhang, Zhiqiang Xu, Joachim Denzler:
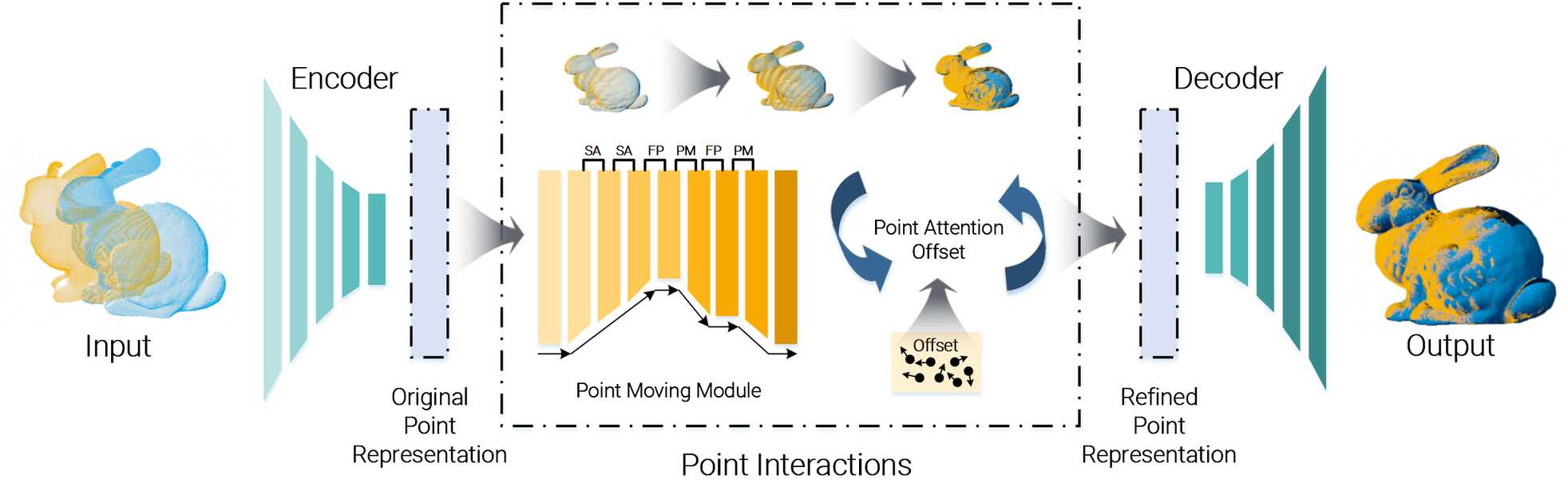
Learning Improved Representations in Encoder-Decoder Networks for Point Cloud Registration via Point Interaction Modules.
Scientific Reports.
2026.
(accepted)
[bibtex]
[doi]
[abstract]
Point cloud registration focuses on exploring and exploiting feature similarities to match multiple point clouds of a scene from different viewpoints. However, in many real-world scenarios, points are missing (e.g., multiple LiDAR scans), or there is a substantial variation of points in different viewpoints (e.g., from 3D reconstruction), making registration more difficult. In this paper, we argue that the quality of point clouds should be improved to ease the matching process. Using point cloud completion techniques, we aim to enhance the learned low-dimensional point representations in state-of-the-art encoder-decoder architectures. We propose two modules with easy drop-in integration to support the registration: a point moving and point attention offset module. The point moving module refines the positions of irregular point clouds to strengthen the alignment, whereas the point attention offset module improves the likelihood of point matches. Both modules promote interactions among the implicit point representations to improve matching accuracy. To demonstrate the validity of our idea, we modified those representations in two popular encoder-decoder networks. In our evaluation, we use the datasets 3DMatch, 3DLoMatch, and ModelNet40. When incorporating our proposed modules, we achieve 90.6\% RR, 72.4\% IR with 5000 samples on 3DMatch and 69.3\% RR, 43.5\% IR with 5000 samples on 3DLoMatch as a new state-of-the-art. Our findings suggest that improving the point cloud quality via learned point representation benefits point cloud registration.
Niklas Penzel, Daniel Scheliga, Hannes Oppermann, Patrick Mäder, Jens Haueisen, Joachim Denzler, Marco Seeland:
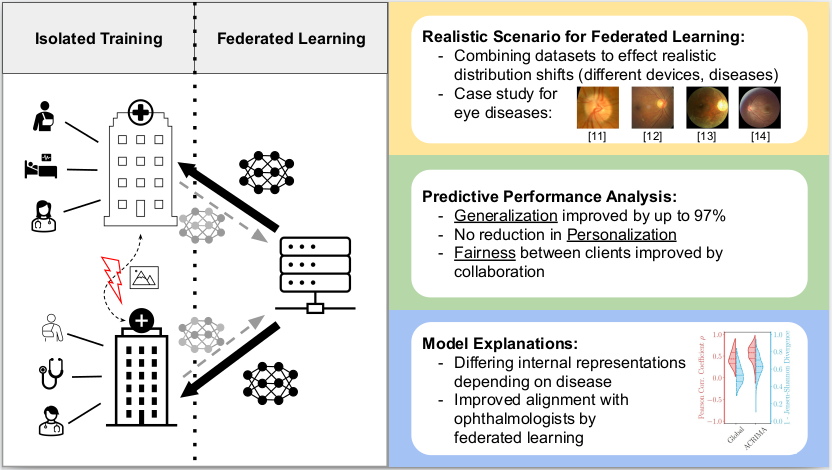
Model utility and explainability in federated learning - A case study in healthcare using fundus oculi datasets.
Journal of Biomedical Informatics.
177 :
pp. 105010.
2026.
[bibtex]
[web]
[doi]
[abstract]
Objective: Introduce a case study for Federated Learning (FL) in healthcare, addressing challenges posed by patient privacy and limited large-scale datasets. Our goal is to assess the features learned by FL methods in a simulated, diverse setting that emphasizes realistic data heterogeneity, and to analyze the learned representations for their medical relevance using both local and global explainability techniques. Methods: Six fundus oculi datasets were combined to simulate a diverse federated learning environment, representing heterogeneous data conditions. We evaluated three established FL methods against centrally trained models, assessing both predictive performance and the learned representations. Specifically, explainability techniques were employed to examine the features learned by the models, and local explanations were evaluated against attention maps annotated by ophthalmologists. Robustness against common biases in fundus datasets was also assessed. Results: Our study found improvements in model utility (up to 9.97%) with FL methods compared to isolated training. Analysis of learned representations revealed that federated models predominantly learn the vertical cup-to-disc ratio, a crucial feature for glaucoma diagnosis, and demonstrated robustness against common biases. High agreement was observed between local explanations and ophthalmologist-annotated attention maps. Conclusion: This study demonstrates the benefits of FL systems in a healthcare scenario, providing a case study for evaluating federated systems beyond idealized benchmarks. Our findings highlight the potential of FL to not only improve model utility in privacy-sensitive medical domains but also to learn medically relevant features instead of spurious correlations.
Niklas Penzel, Gideon Stein, Joachim Denzler:
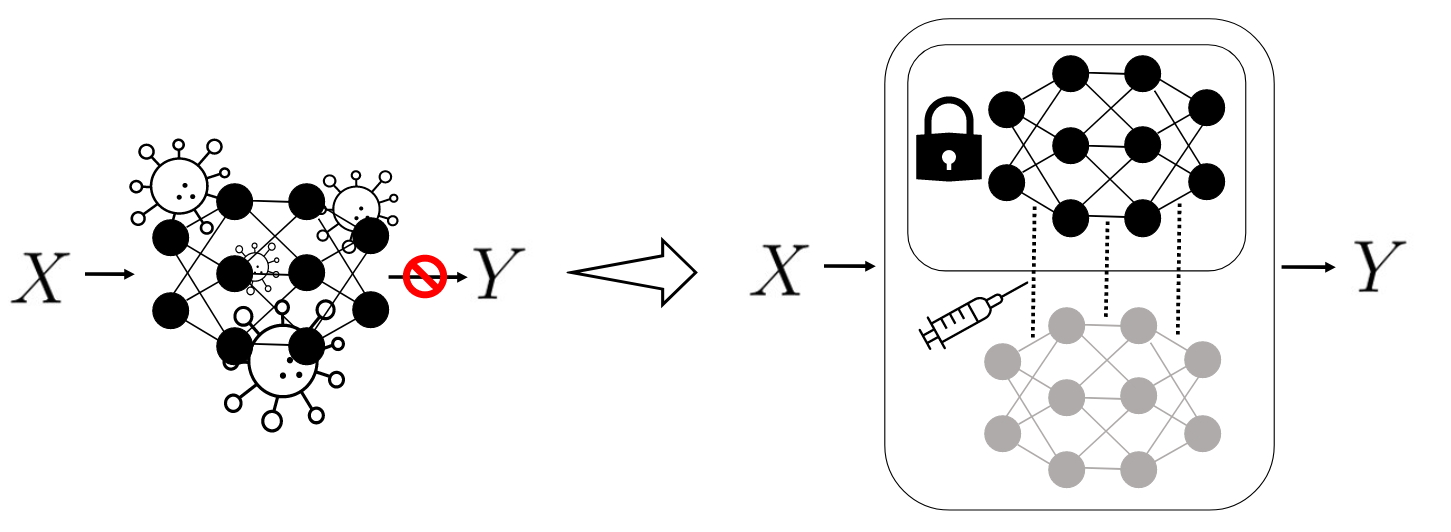
Change Penalized Tuning to Reduce Pre-trained Biases.
Computer Vision, Imaging and Computer Graphics Theory and Applications.
Pages 223-238.
2026.
[bibtex]
[web]
[doi]
[abstract]
Due to the data-centric approach of modern machine learning, biases present in the training data are frequently learned by deep models. It is often necessary to collect new data and retrain the models from scratch to remedy these issues, which can be expensive in critical areas such as medicine. We investigate whether it is possible to fix pre-trained model behavior using very few unbiased examples. We show that we can improve performance by tuning the models while penalizing parameter changes. Hence, we are keeping pre-trained knowledge while simultaneously correcting the harmful behavior. Toward this goal, we tune a zero-initialized copy of the frozen pre-trained network using strong parameter norms. Secondly, we introduce an early stopping scheme to modify baselines and reduce overfitting. Our approaches lead to improvements in four datasets common in the debiasing and domain shift literature. We especially see benefits in an iterative setting, where new samples are added continuously. Hence, we demonstrate the effectiveness of tuning while penalizing change to fix pre-trained models without retraining from scratch.
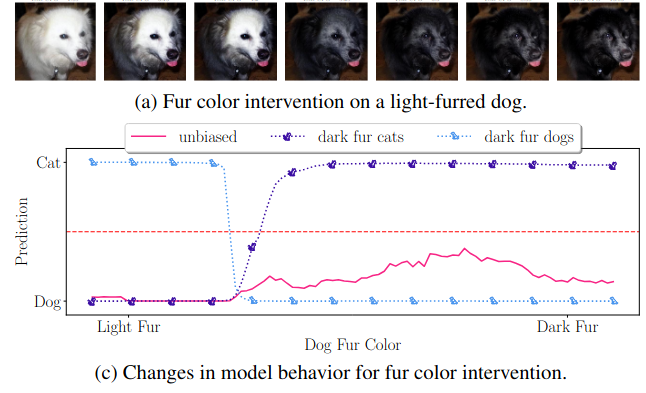
Niklas Penzel, Joachim Denzler:
Locally Explaining Prediction Behavior via Gradual Interventions and Measuring Property Gradients.
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV).
Pages 7398-7408.
2026.
[bibtex]
[web]
[doi]
[abstract]
Deep learning models achieve high predictive performance but lack intrinsic interpretability, hindering our understanding of the learned prediction behavior. Existing local explainability methods focus on associations, neglecting the causal drivers of model predictions. Other approaches adopt a causal perspective but primarily provide more general global explanations. However, for specific inputs, it's unclear whether globally identified factors apply locally. To address this limitation, we introduce a novel framework for local interventional explanations by leveraging recent advances in image-to-image editing models. Our approach performs gradual interventions on semantic properties to quantify the corresponding impact on a model's predictions using a novel score, the expected property gradient magnitude. We demonstrate the effectiveness of our approach through an extensive empirical evaluation on a wide range of architectures and tasks. First, we validate it in a synthetic scenario and demonstrate its ability to locally identify biases. Afterward, we apply our approach to analyze network training dynamics, investigate medical skin lesion classifiers, and study a pre-trained CLIP model with real-life interventional data. Our results highlight the potential of interventional explanations on the property level to reveal new insights into the behavior of deep models.

Sai Karthikeya Vemuri, Adithya Ashok Chalain Valapil, Tim Büchner, Joachim Denzler:
RamPINN: Recovering Raman Spectra From Coherent Anti-Stokes Spectra Using Embedded Physics.
International Conference on Artificial Intelligence and Statistics (AISTATS).
2026.
(accepted)
[bibtex]
[pdf]
[doi]
[abstract]
Transferring the recent advancements in deep learning into scientific disciplines is hindered by the lack of the required large-scale datasets for training. We argue that in these knowledge-rich domains, the established body of scientific theory provides reliable inductive biases in the form of governing physical laws. We address the ill-posed inverse problem of recovering Raman spectra from noisy Coherent Anti-Stokes Raman Scattering (CARS) measurements, as the true Raman signal here is suppressed by a dominating non-resonant background. We propose RamPINN, a model that learns to recover Raman spectra from given CARS spectra. Our core methodological contribution is a physics-informed neural network that utilizes a dual-decoder architecture to disentangle resonant and non-resonant signals. This is done by enforcing the Kramers-Kronig causality relations via a differentiable Hilbert transform loss on the resonant and a smoothness prior on the non-resonant part of the signal. Trained entirely on synthetic data, RamPINN demonstrates strong zero-shot generalization to real-world experimental data, explicitly closing this gap and significantly outperforming existing baselines. Furthermore, we show that training with these physics-based losses alone, without access to any ground-truth Raman spectra, still yields competitive results. This work highlights a broader concept: formal scientific rules can act as a potent inductive bias, enabling robust, self-supervised learning in data-limited scientific domains.
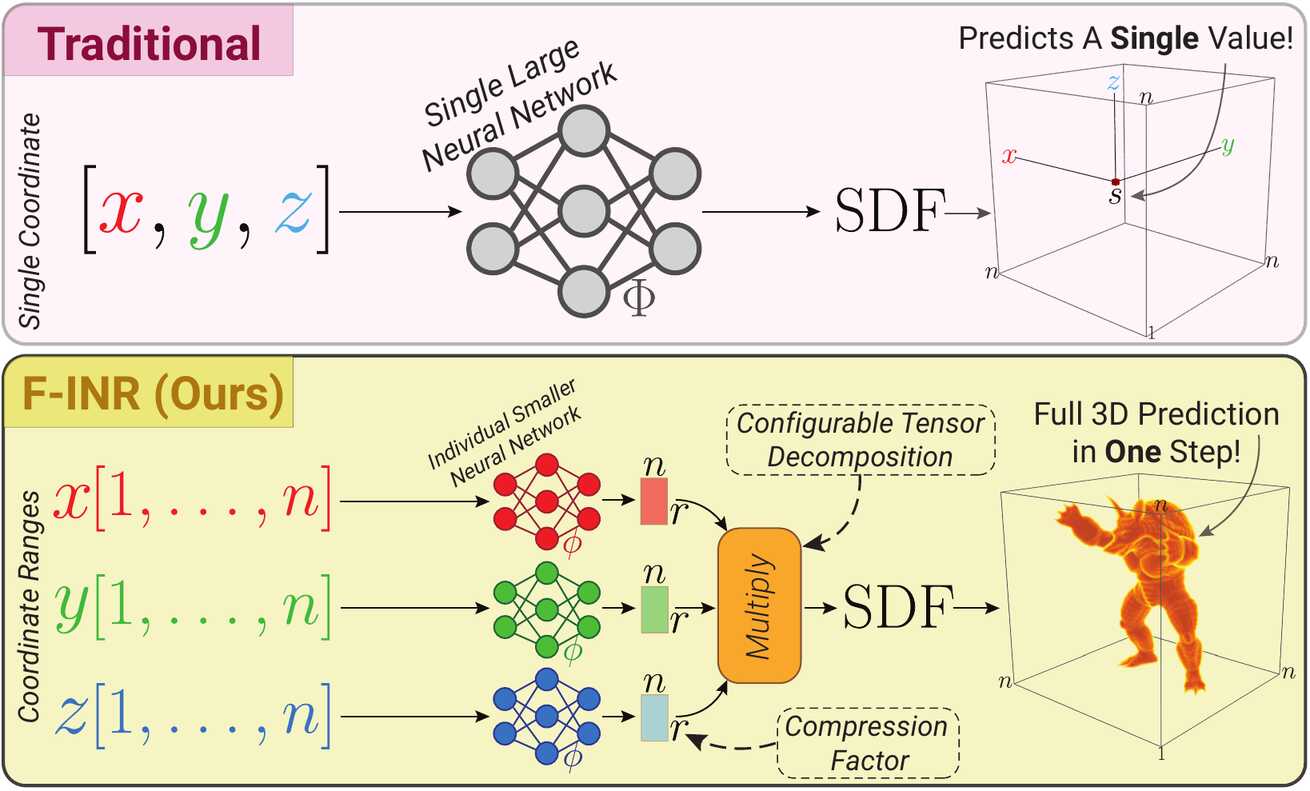
Sai Karthikeya Vemuri, Tim Büchner, Joachim Denzler:
F-INR: Functional Tensor Decomposition for Implicit Neural Representations.
Winter Conference on Applications of Computer Vision (WACV).
2026.
(accepted)
[bibtex]
[web]
[doi]
[abstract]
Implicit Neural Representations (INRs) model signals as continuous, differentiable functions. However, monolithic INRs scale poorly with data dimensionality, leading to excessive training costs. We propose F-INR, a framework that addresses this limitation by factorizing a high-dimensional INR into a set of compact, axis-specific sub-networks based on functional tensor decomposition. These sub-networks learn low-dimensional functional components that are then combined via tensor operations. This factorization reduces computational complexity while additionally improving representational capacity. F-INR is both architecture- and decomposition-agnostic. It integrates with various existing INR backbones (e.g., SIREN, WIRE, FINER, Factor Fields) and tensor formats (e.g., CP, TT, Tucker), offering fine-grained control over the speed-accuracy trade-off via the tensor rank and mode. Our experiments show F-INR accelerates training by up to and improves fidelity by over 6.0 dB PSNR compared to state-of-the-art INRs. We validate these gains on diverse tasks, including image representation, 3D geometry reconstruction, and neural radiance fields. We further show F-INR's applicability to scientific computing by modeling complex physics simulations. Thus, F-INR provides a scalable, flexible, and efficient framework for high-dimensional signal modeling.
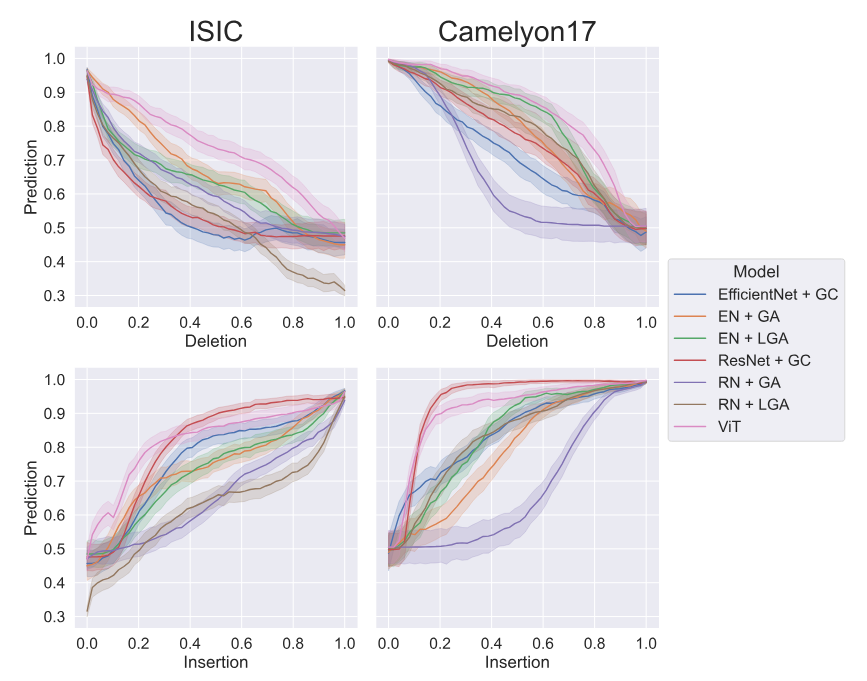
Tristan Piater, Niklas Penzel, Gideon Stein, Joachim Denzler:
Self-Attention for Medical Imaging - On the need for evaluations beyond mere benchmarking.
Computer Vision, Imaging and Computer Graphics Theory and Applications.
Pages 259-275.
2026.
[bibtex]
[web]
[doi]
[abstract]
A considerable amount of research has been dedicated to creating systems that aid medical professionals in labor-intensive early screening tasks, which, to this date, often leverage convolutional deep-learning architectures. Recently, several studies have explored the application of self-attention mechanisms in the field of computer vision. These studies frequently demonstrate empirical improvements over traditional, fully convolutional approaches across a range of datasets and tasks. To assess this trend for medical imaging, we enhance two commonly used convolutional architectures with various self-attention mechanisms and evaluate them on two distinct medical datasets. We compare these enhanced architectures with similarly sized convolutional and attention-based baselines and rigorously assess performance gains through statistical evaluation. Furthermore, we investigate how the inclusion of self-attention influences the features learned by these models by assessing global and local explanations of model behavior. Contrary to our expectations, after performing an appropriate hyperparameter search, self-attention-enhanced architectures show no significant improvements in balanced accuracy compared to the evaluated baselines. Further, we find that relevant global features like dermoscopic structures in skin lesion images are not properly learned by any architecture. Finally, by assessing local explanations, we find that the inherent interpretability of self-attention mechanisms does not provide additional insights. Out-of-the-box model-agnostic approaches can provide explanations that are similar or even more faithful to the actual model behavior. We conclude that simply integrating attention mechanisms is unlikely to lead to a consistent increase in performance compared to fully convolutional methods in medical imaging applications.
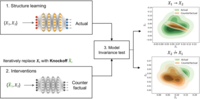
Wasim Ahmad, Joachim Denzler, Maha Shadaydeh:
Group Interventions on Deep Networks for Causal Discovery in Subsystems.
arXiv preprint arXiv:2510.23906.
2026.
[bibtex]
[doi]
[abstract]
Causal discovery uncovers complex relationships between variables, enhancing predictions, decision-making, and insights into real-world systems, especially in nonlinear multivariate time series. However, most existing methods primarily focus on pairwise cause-effect relationships, overlooking interactions among groups of variables, i.e., subsystems and their collective causal influence. In this study, we introduce gCDMI, a novel multi-group causal discovery method that leverages group-level interventions on trained deep neural networks and employs model invariance testing to infer causal relationships. Our approach involves three key steps. First, we use deep learning to jointly model the structural relationships among groups of all time series. Second, we apply group-wise interventions to the trained model. Finally, we conduct model invariance testing to determine the presence of causal links among variable groups. We evaluate our method on simulated datasets, demonstrating its superior performance in identifying group-level causal relationships compared to existing methods. Additionally, we validate our approach on real-world datasets, including brain networks and climate ecosystems. Our results highlight that applying group-level interventions to deep learning models, combined with invariance testing, can effectively reveal complex causal structures, offering valuable insights for domains such as neuroscience and climate science.

Adithya Ashok Chalain Valapil, Carl Messerschmidt, Maha Shadaydeh, Michael Schmitt, Jürgen Popp, Joachim Denzler:
Deep Learning-Assisted Dynamic Mode Decomposition for Non-resonant Background Removal in CARS Spectroscopy.
DAGM German Conference on Pattern Recognition (DAGM-GCPR).
Pages 41-56.
2025.
[bibtex]
[pdf]
[doi]
[abstract]
Coherent Anti-Stokes Raman Spectroscopy (CARS) provides non-invasive, label-free chemical analysis at high spatial resolution, making it a powerful tool for biomedical and material imaging. However, their effectiveness is hindered by a dominant and unpredictable non-resonant background (NRB) that distorts meaningful spectral features. Existing NRB removal methods often require additional measurements or computationally intensive post-processing. In this work, we present a physics-informed framework that leverages the broadband, low-rank structure of the NRB using Dynamic Mode Decomposition (DMD) for unsupervised separation of resonant Raman modes from non-resonant contributions in the spectral domain. We further introduce DA-DMD - a Deep Learning-Assisted DMD approach, that uses an attention mechanism to adaptively weight DMD modes and a CNN with skip connection to enhance Raman signal reconstruction. Trained entirely on synthetic data, DA-DMD eliminates the need for experimental labels or calibration. We validate our methods on synthetic and real CARS measurements, demonstrating superior background suppression, fidelity preservation, and generalization compared to existing approaches. DA-DMD offers fast inference and improves robustness, positioning it as a practical tool for scalable chemical imaging in complex environments.
Aishwarya Venkataramanan, Joachim Denzler:
Distance-informed Neural Processes.
Annual Conference on Neural Information Processing Systems (NeurIPS).
2025.
[bibtex]
[web]
[doi]
[code]
[abstract]
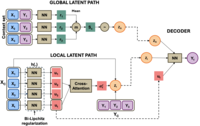
We propose the Distance-informed Neural Process (DNP), a novel variant of Neural Processes that improves uncertainty estimation by combining global and distance-aware local latent structures. Standard Neural Processes (NPs) often rely on a global latent variable and struggle with uncertainty calibration and capturing local data dependencies. DNP addresses these limitations by introducing a global latent variable to model task-level variations and a local latent variable to capture input similarity within a distance-preserving latent space. This is achieved through bi-Lipschitz regularization, which bounds distortions in input relationships and encourages the preservation of relative distances in the latent space. This modeling approach allows DNP to produce better-calibrated uncertainty estimates and more effectively distinguish in- from out-of-distribution data. Empirical results demonstrate that DNP achieves strong predictive performance and improved uncertainty calibration across regression and classification tasks.

Aishwarya Venkataramanan, Paul Bodesheim, Joachim Denzler:
Probabilistic Embeddings for Frozen Vision-Language Models: Uncertainty Quantification with Gaussian Process Latent Variable Models.
International Conference on Uncertainty in Artificial Intelligence (UAI).
Pages 4309-4328.
2025.
[bibtex]
[web]
[doi]
[code]
[abstract]
Vision-Language Models (VLMs) learn joint representations by mapping images and text into a shared latent space. However, recent research highlights that deterministic embeddings from standard VLMs often struggle to capture the uncertainties arising from the ambiguities in visual and textual descriptions and the multiple possible correspondences between images and texts. Existing approaches tackle this by learning probabilistic embeddings during VLM training, which demands large datasets and does not leverage the powerful representations already learned by large-scale VLMs like CLIP. In this paper, we propose GroVE, a post-hoc approach to obtaining probabilistic embeddings from frozen VLMs. GroVE builds on Gaussian Process Latent Variable Model (GPLVM) to learn a shared low-dimensional latent space where image and text inputs are mapped to a unified representation, optimized through single-modal embedding reconstruction and cross-modal alignment objectives. Once trained, the Gaussian Process model generates uncertainty-aware probabilistic embeddings. Evaluation shows that GroVE achieves state-of-the-art uncertainty calibration across multiple downstream tasks, including cross-modal retrieval, visual question answering, and active learning.
Aishwarya Venkataramanan, Sai Karthikeya Vemuri, Adithya Ashok Chalain Valapil, Joachim Denzler:
Uncertainty-aware Physics-informed Neural Networks for Robust CARS-to-Raman Signal Reconstruction.
EurIPS Workshop on Differentiable Systems and Scientific Machine Learning (EurIPS-WS).
2025.
[bibtex]
[abstract]
Coherent anti-Stokes Raman scattering (CARS) spectroscopy is a powerful and rapid technique widely used in medicine, material science, and chemical analyses. However, its effectiveness is hindered by the presence of a non-resonant background that interferes with and distorts the true Raman signal. Deep learning methods have been employed to reconstruct the true Raman spectrum from measured CARS data using labeled datasets. A more recent development integrates the domain knowledge of Kramers-Kronig relationships and smoothness constraints in the form of physics-informed loss functions. However, these deterministic models lack the ability to quantify uncertainty, an essential feature for reliable deployment in high-stakes scientific and biomedical applications. In this work, we evaluate and compare various uncertainty quantification (UQ) techniques within the context of CARS-to-Raman signal reconstruction. Furthermore, we demonstrate that incorporating physics-informed constraints into these models improves their calibration, offering a promising path toward more trustworthy CARS data analysis.

Ana E. Bonato Asato, Claudia Guimaraes-Steinicke, Gideon Stein, Berit Schreck, Teja Kattenborn, Anne Ebeling, Stefan Posch, Joachim Denzler, Tim Büchner, Maha Shadaydeh, Christian Wirth, Nico Eisenhauer, Jes Hines:
Seasonal Shifts in Plant Diversity Effects on Above-Ground-Below-Ground Phenological Synchrony.
Journal of Ecology.
113 (2) :
pp. 472-484.
2025.
[bibtex]
[pdf]
[web]
[doi]
[abstract]
The significance of biological diversity as a mechanism that optimizes niche breadth for resource acquisition and enhancing ecosystem functionality is well-established. However, a significant gap remains in exploring temporal niche breadth, particularly in the context of phenological aspects of community dynamics. This study takes a unique approach by examining plant phenology, which has traditionally been focused on above-ground assessments, and delving into the relatively unexplored realm of below-ground processes. As a result, the influence of biological diversity on the synchronization of above-ground and below-ground dynamics is brought to the forefront, providing a novel perspective on this complex relationship. In this study, community traits (including plant height and greenness) and soil processes (such as root growth and detritivore feeding activity) were meticulously monitored at 2-week intervals over a year within an experimental grassland exhibiting a spectrum of plant diversity, ranging from monocultures to 60-species mixtures. Our findings revealed that plant diversity increased yearly plant height, root growth and detritivore feeding activity, while enhancing the synchrony between above-ground traits and soil dynamics. Soil microclimate also played a role in shaping the phenology of these traits and processes. However, plant diversity and soil microclimate on above-ground traits and soil dynamics effects varied considerably in strength and direction across seasons, indicating a nuanced relationship between biodiversity, climate and ecosystem processes. Notably, observations during the growing season unveiled a sequential pattern wherein peak plant community height preceded the onset of greenness. Meanwhile, root production commenced immediately after leaf senescence and persisted throughout winter. Although consistent throughout the year, detritivore activity exhibited pronounced peaks in the summer and late fall, albeit with notable variability. Synthesis. The study underscores the dynamic interplay between plant diversity, above-ground–below-ground phenological patterns and ecosystem functioning. It suggests that plant diversity modulates above-ground–below-ground interdependence through intricate phenological dynamics, with the degree of synchrony fluctuating in response to the varying combination of processes and seasonal changes. Thus, by providing comprehensive within-year data, the research elucidates the fundamental disparities in phenological patterns across shoots, roots and soil fauna activities, thereby emphasizing the pivotal role of plant diversity in shaping ecosystem processes.
Christian Ickler, Aishwarya Venkataramanan, Joachim Denzler:
Text-Assisted Zero-Shot Classification of Fine-Grained Animal Species.
International Workshop Series on Camera Traps, AI, \& Ecology (CamTrapAI).
2025.
[bibtex]
[abstract]
Fine-grained visual classification of animals is vital for automatic ecological monitoring. Its inherent challenges, including low inter-class and high intra-class variations, are often compounded by data scarcity for rare species. These difficulties are particularly pronounced in zero-shot classification, where models must identify classes without training examples, necessitating auxiliary information like high-quality textual descriptions to accurately discriminate the species. However, text-assisted zero-shot fine-grained classification of animal species remains largely unexplored. In this work, we evaluate a set of CLIP-based methods by appending class descriptions to their text prompts. We then propose a two-stage framework that relies on a large vision language model (LVLM) to compare image features to descriptions. Our approach extends the two-stage framework of CascadeVLM, which uses CLIP in the first stage to select a set of candidate species and refines the predictions in the second stage with an LVLM, by also integrating descriptive texts into the LVLM's prompt, leveraging its in-context learning ability. We evaluate on two benchmark datasets: CUB-200-2011 and EU-Moths, containing fine-grained bird and moth images, respectively. Our results indicate that while producing competitive predictions, our approach still struggles when applying general-purpose foundation models in highly specialised animal domains. Unbalanced performance across stages and LVLM hallucinations highlight the need for more robust zero-shot classification approaches leveraging detailed text descriptions.

Dimitri Korsch, Maha Shadaydeh, Joachim Denzler:
Simplified Concrete Dropout - Improving the Generation of Attribution Masks for Fine-grained Classification.
International Journal of Computer Vision.
133 (8) :
pp. 5857-5871.
2025.
[bibtex]
[web]
[doi]
[abstract]
In fine-grained classification, which is classifying images into subcategories within a common broader category, it is crucial to have precise visual explanations of the classification model's decision. While commonly used attention- or gradient-based methods deliver either too coarse or too noisy explanations unsuitable for highlighting subtle visual differences reliably, perturbation-based methods can precisely locate pixels causally responsible for the predicted category. The fill-in of the dropout (FIDO) algorithm is one of those methods, which utilizes concrete dropout (CD) to sample a set of attribution masks and updates the sampling parameters based on the output of the classification model. In this paper, we present a solution against the high variance in the gradient estimates, a known problem of the FIDO algorithm that has been mitigated until now by large mini-batch updates of the sampling parameters. First, our solution allows for estimating the parameters with smaller mini-batch sizes without losing the quality of the estimates but with a reduced computational effort. Next, our method produces finer and more coherent attribution masks. Finally, we use the resulting attribution masks to improve the classification performance on three fine-grained datasets without additional fine-tuning steps and achieve results that are otherwise only achieved if ground truth bounding boxes are used.

Dong Han, Salaheldin Mohamed, Yong Li, Joachim Denzler:
Diffusion-based Identity-Preserving Facial Privacy Protection.
IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP).
Pages 1-5.
2025.
[bibtex]
[doi]
[abstract]
The efficacy of facial recognition systems that utilize deep learning techniques has led to significant concerns over privacy, since they possess the capability to facilitate unauthorized monitoring of individuals in the digital realm. Current techniques for improving privacy are ineffective in producing "naturalistic" photographs that can safeguard facial features and fail to ensure privacy while maintaining an optimal user experience. We present an innovative text-agnostic method for protecting facial privacy. Our method depends on manipulating the sampling process of a pretrained diffusion model utilizing the guidance from a target image face together with the original image and face guidance in an adversarial manner to produce a protected face image. We preserve the original visual information from the input face image for identity preservation while extracting general embedding information from the target face image for soft facial attribute transfer. The output protected face image from our method has imperceptible facial changes with enhanced privacy protection against state-of-the-art (SOTA) face recognition (FR) systems. Our extensive studies have shown that the faces generated using our method have a higher level of black-box adaptability, resulting in an absolute improvement of 6.4\% on CelebA-HQ compared to the current most effective SOTA facial privacy protection technique in the face verification task while maintaining high image fidelity.

Ferdinand Rewicki, Joachim Denzler, Julia Niebling:
Anomalous Agreement: How to find the Ideal Number of Anomaly Classes in Correlated, Multivariate Time Series Data.
AAAI Workshop on AI for Time-series Analysis (AAAI-WS).
2025.
[bibtex]
[pdf]
[doi]
[abstract]
Detecting and classifying abnormal system states is critical for condition monitoring, but supervised methods often fall short due to the rarity of anomalies and the lack of labeled data. Therefore, clustering is often used to group similar abnormal behavior. However, evaluating cluster quality without ground truth is challenging, as existing measures such as the Silhouette Score (SSC) only evaluate the cohesion and separation of clusters and ignore possible prior knowledge about the data. To address this challenge, we introduce the Synchronized Anomaly Agreement Index (SAAI), which exploits the synchronicity of anomalies across multivariate time series to assess cluster quality. We demonstrate the effectiveness of SAAI by showing that maximizing SAAI improves accuracy on the task of finding the true number of anomaly classes K in correlated time series by 0.23 compared to SSC and by 0.32 compared to X-Means. We also show that clusters obtained by maximizing SAAI are easier to interpret compared to SSC.

Gideon Stein, Maha Shadaydeh, Jan Blunk, Niklas Penzel, Joachim Denzler:
CausalRivers - Scaling Up Benchmarking of Causal Discovery for Real-world Time-series.
International Conference on Learning Representations (ICLR).
2025.
[bibtex]
[pdf]
[web]
[doi]
[abstract]
Causal discovery, or identifying causal relationships from observational data, is a notoriously challenging task, with numerous methods proposed to tackle it. Despite this, in-the-wild evaluation of these methods is still lacking, as works frequently rely on synthetic data evaluation and sparse real-world examples under critical theoretical assumptions. Real-world causal structures, however, are often complex, evolving over time, non-linear, and influenced by unobserved factors, making it hard to decide on a proper causal discovery strategy. To bridge this gap, we introduce CausalRivers, the largest in-the-wild causal discovery benchmarking kit for time-series data to date. CausalRivers features an extensive dataset on river discharge that covers the eastern German territory (666 measurement stations) and the state of Bavaria (494 measurement stations). It spans the years 2019 to 2023 with a 15-minute temporal resolution. Further, we provide additional data from a flood around the Elbe River, as an event with a pronounced distributional shift. Leveraging multiple sources of information and time-series meta-data, we constructed two distinct causal ground truth graphs (Bavaria and eastern Germany). These graphs can be sampled to generate thousands of subgraphs to benchmark causal discovery across diverse and challenging settings. To demonstrate the utility of CausalRivers, we evaluate several causal discovery approaches through a set of experiments to identify areas for improvement. CausalRivers has the potential to facilitate robust evaluations and comparisons of causal discovery methods. Besides this primary purpose, we also expect that this dataset will be relevant for connected areas of research, such as time-series forecasting and anomaly detection. Based on this, we hope to push benchmark-driven method development that fosters advanced techniques for causal discovery, as is the case for many other areas of machine learning.
Hui Yu, Joachim Denzler, Dennis Böttger, Gunnar Brehm, Paul Bodesheim:
Exploiting Unlabeled Images via Pseudo-Labelling and Paste-In Augmentation for Insect Localisation in Automated Monitoring.
International Workshop Series on Camera Traps, AI, \& Ecology (CamTrapAI).
2025.
[bibtex]
[pdf]
[abstract]
Insect monitoring using an automated deep learning pipeline has become increasingly important in understanding the crisis of insect decline. Advanced model architectures trained with high-resolution images are essential to ensure the quality of insect localisation and species identification. Recent methods struggle with limited annotated data, which requires time-consuming manual labelling for bounding boxes and domain expert-level knowledge for insect categorisation. In this paper, we present a comprehensive benchmark of object detection models for this task, evaluating YOLOv9 and SSD architectures across three distinct datasets: EU-Moths, NID-Moths, and AMI-Traps. Our experiments reveal that high-resolution inputs are a dominant factor for accurate insect localisation, with performance improving substantially with larger image sizes. In addition, we perform cross-dataset validation to verify the generalisation capabilities of YOLOv9 on these datasets, justifying the choice of the AMI-Traps dataset as our pre-training dataset for obtaining a robust detector. Finally, to leverage large amounts of unlabeled data, we investigate a pseudo-labelling and paste-in data augmentation strategy. While this technique provides only modest improvements in overall detection metrics, qualitative analysis demonstrates that it enhances model robustness, enabling the detection of insects in challenging, low-contrast conditions where a strong baseline model would otherwise fail. In our experiments, YOLOv9 outperforms SSD on the one-class NID-Moths and AMI-Traps datasets with average precisions of 0.951 and 0.742, respectively. On the binary-class AMI-Traps dataset, a larger YOLOv9 model with a 1280x1280 input resolution achieves an average precision of 0.972 for the moth category. These results indicate the importance of data-centric approaches and high-resolution imagery for building effective automated insect monitoring systems.

Ihab Asaad, Maha Shadaydeh, Joachim Denzler:
Gradient Extrapolation for Debiased Representation Learning.
International Conference on Computer Vision (ICCV).
Pages 3819-3829.
2025.
[bibtex]
[pdf]
[web]
[doi]
[presentation]
[abstract]
Machine learning classification models trained with empirical risk minimization (ERM) often inadvertently rely on spurious correlations. When absent in the test data, these unintended associations between non-target attributes and target labels lead to poor generalization. This paper addresses this problem from a model optimization perspective and proposes a novel method, Gradient Extrapolation for Debiased Representation Learning (GERNE), designed to learn debiased representations in both known and unknown attribute training cases. GERNE uses two distinct batches with different amounts of spurious correlations to define the target gradient as the linear extrapolation of two gradients computed from each batch's loss. It is demonstrated that the extrapolated gradient, if directed toward the gradient of the batch with fewer amount of spurious correlation, can guide the training process toward learning a debiased model. GERNE can serve as a general framework for debiasing with methods, such as ERM, reweighting, and resampling, being shown as special cases. The theoretical upper and lower bounds of the extrapolation factor are derived to ensure convergence. By adjusting this factor, GERNE can be adapted to maximize the Group-Balanced Accuracy (GBA) or the Worst-Group Accuracy. The proposed approach is validated on five vision and one NLP benchmarks, demonstrating competitive and often superior performance compared to state-of-the-art baseline methods.

Ihab Asaad, Maha Shadaydeh, Joachim Denzler:
Mitigating Spurious Correlations in Patch-wise Tumor Classification on High-Resolution Multimodal Images.
EurIPS Workshop on Unifying Perspectives on Learning Biases (EurIPS-WS).
2025.
[bibtex]
[pdf]
[web]
[abstract]
Patch-wise multi-label classification provides an efficient alternative to full pixel-wise segmentation on high-resolution images, particularly when the objective is to determine the presence or absence of target objects within a patch rather than their precise spatial extent. This formulation substantially reduces annotation cost, simplifies training, and allows flexible patch sizing aligned with the desired level of decision granularity. In this work, we focus on a special case, patch-wise binary classification, applied to the detection of a single class of interest (tumor) on high-resolution multimodal nonlinear microscopy images. We show that, although this simplified formulation enables efficient model development, it can introduce spurious correlations between patch composition and labels: tumor patches tend to contain larger tissue regions, whereas non-tumor patches often consist mostly of background with small tissue areas. We further quantify the bias in model predictions caused by this spurious correlation, and propose to use a debiasing strategy to mitigate its effect. Specifically, we apply GERNE, a debiasing method that can be adapted to maximize worst-group accuracy (WGA). Our results show an improvement in WGA by approximately 7\% compared to ERM for two different thresholds used to binarize the spurious feature. This enhancement boosts model performance on critical minority cases, such as tumor patches with small tissues and non-tumor patches with large tissues, and underscores the importance of spurious correlation-aware learning in patch-wise classification problems.

Jan Blunk, Paul Bodesheim, Joachim Denzler:
Adaptive Model Selection for Expanded Post Hoc Debiasing and Mitigating Varying Degrees of Spurious Correlations.
International Conference in Computer Analysis of Images and Patterns (CAIP).
Pages 101-111.
2025.
[bibtex]
[web]
[doi]
[abstract]
Deep neural networks are prone to shortcut bias,where models rely on features that are statistically associated with the target label but lack causal relevance, leading to poor generalization under distribution shifts. To add ress this, debiasing methods aim to improve robustness by reducing reliance on these spurious features. Unfortunately, existing approaches typically assume unbiased test distributions, an idealized scenario that rarely holds in practice. As a result, they often underperform on the original biased distribution when compared with standard empirical risk minimization (ERM) models. We propose a novel Adaptive Model SELection approach for expanding post hoc debiasing called AMSEL, which maintains strong performance across test distributions with varying strength of spurious correlation. Using the fixed feature extractor of the biased model, AMSEL trains a family of lightweight classifier heads on simulated distributions ranging from the original biased data to a fully balanced version. At test time, it estimates the degree of spurious correlation in the test data and selects the most suitable classifier. We validate AMSEL on CelebA and ChestX-ray14, demonstrating that it matches the performance of debiased models under unbiased conditions while preserving the accuracy of the original biased model when spurious correlations are prevalent. AMSEL thus offers an adaptive solution to mitigate the impact of spurious correlations when their strength is either unknown or varies across application environments. Code and models are publicly available at https://github.com/debiasing/AMSEL.
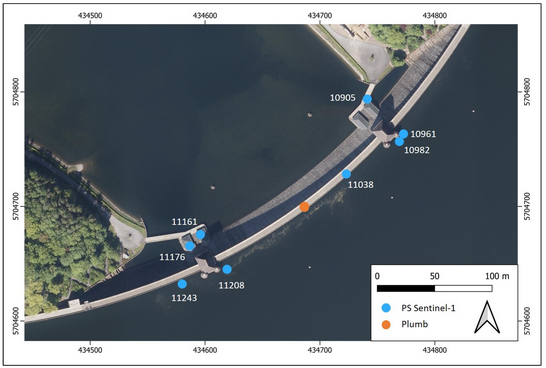
Jonas Ziemer, Gideon Stein, Carolin Wicker, Jannik Jänichen, Daniel Klöpper, Katja Last, Joachim Denzler, Christiane Schmullius, Maha Shadaydeh, Clémence Dubois:
Enhancing the Prediction of Dam Deformations: A Novel Data-Driven Approach.
Remote Sensing.
17 (6) :
2025.
[bibtex]
[pdf]
[doi]
[abstract]
Deformation monitoring is a critical task for dam operators to guarantee safe operation. Given an increasing number of extreme weather events caused by climate change, the precise prediction of dam deformations has become increasingly important. Traditionally, multiple linear regression models have been employed, utilizing in situ data from pendulum systems or trigonometric measurements. These methods sometimes suffer from sparse data, which typically represent deformations only at specific points on the dam, if such data are available at all. Technical advances in multi-temporal synthetic aperture radar interferometry (MT-InSAR), particularly Persistent Scatterer Interferometry (PSI), address these limitations by enabling monitoring in high spatial and temporal resolution, capturing dam deformations with millimeter precision, and providing extensive spatial coverage. This study advances traditional methods of dam monitoring by employing data-driven techniques and integrating Sentinel-1 C-band Persistent Scatterer (PS) time series alongside in situ data. Through a comprehensive evaluation of advanced data-driven approaches, we demonstrated considerable improvements in predicting dam deformations and evaluating their drivers. The analysis provided evidence for the following insights: First, the accuracy of current modeling approaches can be greatly improved by utilizing advanced feature engineering and data-driven model selection. The prediction performance of the pendulum data was improved by utilizing data-driven algorithms, reducing the mean absolute error from 0.51 mm in the baseline model (R2 = 0.92) to as low as 0.05 mm using the full model search space (R2 = 0.99). Although the model accuracy for the PS datasets (MAEmax: 0.81 mm) was about one order of magnitude lower than that for pendulum data, the mean absolute errors could be reduced by up to 0.25 mm. Second, by incorporating freely available PS time series into deformation prediction, dams can be monitored in higher spatial resolution, making PSI a valuable tool for dam operators. This requires adequate dataset filtering to eliminate noisy PS points. Third, extended representations of water level and temperature, including interaction effects, can improve model accuracy and reduce prediction errors. With these insights, we recommend incorporating the proposed methodology into the monitoring program of gravity dams to enhance the accuracy in predicting their expected deformations.

Jonas Ziemer, Jannik Jänichen, Gideon Stein, Natascha Liedel, Carolin Wicker, Katja Last, Joachim Denzler, Christiane Schmullius, Maha Shadaydeh, Clémence Dubois:
Identifying Deformation Drivers in Dam Segments Using Combined X- and C-Band PS Time Series.
Remote Sensing.
17 (15) :
2025.
[bibtex]
[doi]
[abstract]
Dams play a vital role in securing water and electricity supplies for households and industry, and they contribute significantly to flood protection. Regular monitoring of dam deformations holds fundamental socio-economic and ecological importance. Traditionally, this has relied on time-consuming in situ techniques that offer either high spatial or temporal resolution. Persistent Scatterer Interferometry (PSI) addresses these limitations, enabling high-resolution monitoring in both domains. Sensors such as TerraSAR-X (TSX) and Sentinel-1 (S-1) have proven effective for deformation analysis with millimeter accuracy. Combining TSX and S-1 datasets enhances monitoring capabilities by leveraging the high spatial resolution of TSX with the broad coverage of S-1. This improves monitoring by increasing PS point density, reducing revisit intervals, and facilitating the detection of environmental deformation drivers. This study aims to investigate two objectives: first, we evaluate the benefits of a spatially and temporally densified PS time series derived from TSX and S-1 data for detecting radial deformations in individual dam segments. To support this, we developed the TSX2StaMPS toolbox, integrated into the updated snap2stamps workflow for generating single-master interferogram stacks using TSX data. Second, we identify deformation drivers using water level and temperature as exogenous variables. The five-year study period (2017–2022) was conducted on a gravity dam in North Rhine-Westphalia, Germany, which was divided into logically connected segments. The results were compared to in situ data obtained from pendulum measurements. Linear models demonstrated a fair agreement between the combined time series and the pendulum data (𝑅2 = 0.5; MAE = 2.3 mm). Temperature was identified as the primary long-term driver of periodic deformations of the gravity dam. Following the filling of the reservoir, the variance in the PS data increased from 0.9 mm to 3.9 mm in RMSE, suggesting that water level changes are more responsible for short-term variations in the SAR signal. Upon full impoundment, the mean deformation amplitude decreased by approximately 1.7 mm toward the downstream side of the dam, which was attributed to the higher water pressure. The last five meters of water level rise resulted in higher feature importance due to interaction effects with temperature. The study concludes that integrating multiple PS datasets for dam monitoring is beneficial particularly for dams where few PS points can be identified using one sensor or where pendulum systems are not installed. Identifying the drivers of deformation is feasible and can be incorporated into existing monitoring frameworks.

Laines Schmalwasser, Niklas Penzel, Joachim Denzler, Julia Niebling:
FastCAV: Efficient Computation of Concept Activation Vectors for Explaining Deep Neural Networks.
International Conference on Machine Learning (ICML).
2025.
[bibtex]
[web]
[abstract]
Concepts such as objects, patterns, and shapes are how humans understand the world. Building on this intuition, concept-based explainability methods aim to study representations learned by deep neural networks in relation to human-understandable concepts. Here, Concept Activation Vectors (CAVs) are an important tool and can identify whether a model learned a concept or not. However, the computational cost and time requirements of existing CAV computation pose a significant challenge, particularly in large-scale, high-dimensional architectures. To address this limitation, we introduce \methodname, a novel approach that accelerates the extraction of CAVs by up to \maxspeedup (on average \avgspeedup). \%times. We provide a theoretical foundation for our approach and give concrete assumptions under which it is equivalent to established SVM-based methods. Our empirical results demonstrate that CAVs calculated with \methodname maintain similar performance while being more efficient and stable. In downstream applications, i.e., concept-based explanation methods, we show that \methodname can act as a replacement leading to equivalent insights. Hence, our approach enables previously infeasible investigations of deep models, which we demonstrate by tracking the evolution of concepts during model training.

Maha Shadaydeh, Vanessa Nöring, Marcel Franz, Tara Chand, Ilona Croy, Joachim Denzler:
Directionality of Interpersonal Neural Influence in functional Near-Infrared Spectroscopy Hyperscanning: Feasibility of Information-Theoretic Causality Analysis in Motor Tasks..
European Journal of Neuroscience.
2025.
[bibtex]
[pdf]
[doi]
[abstract]
Hyperscanning approaches represent a shift from single- to two-person neuroscience, enabling a more profound understanding of the neural mechanisms underlying interpersonal synchronization. In this context, fNIRS has emerged as a valuable tool for measuring brain activity in a natural, unconstrained environment. While interpersonal synchrony using fNIRS hyperscanning has been well studied using statistical association analysis, establishing causal relationships that elucidate the direction of influence remains challenging. This study aimed to investigate the feasibility of testing the direction of influence in dyadic interactions. Since the ground truth of such direction is not available in a natural setting, we validated our approach in an experimental setup in which we controlled the direction of influence between two subjects by assigning them the roles of 'Model' and 'Imitator' of specified motor tasks. A total of 22 participants, hence 11 dyads, completed the task in a within-subject design. We adapted concepts from spectral causal-effect decomposition theories to formulate a new measure of the direction and intensity of influence. The results of this study demonstrate that the direction of influence in the fNIRs data of motor tasks can be detected with an Accuracy in the range of 69-88\%. Furthermore, the proposed spectral causality measure was shown to significantly reduce spurious causal relationships due to the confounding effects of physiological processes and measurement artifacts compared to time-domain causal analysis.

Markus Reichstein, Vitus Benson, Jan Blunk, Gustau Camps-Valls, Felix Creutzig, Carina J. Fearnley, Boran Han, Kai Kornhuber, Nasim Rahaman, Bernhard Schölkopf, José María Tárraga, Ricardo Vinuesa, Karen Dall, Joachim Denzler, Dorothea Frank, Giulia Martini, Naomi Nganga, Danielle C. Maddix, Kommy Weldemariam:
Early Warning of Complex Climate Risk with Integrated Artificial Intelligence.
Nature Communications.
16 (1) :
2025.
[bibtex]
[pdf]
[web]
[doi]
[abstract]
As climate change accelerates, human societies face growing exposure to disasters and stress, highlighting the urgent need for effective early warning systems (EWS). These systems monitor, assess, and communicate risks to support resilience and sustainable development, but challenges remain in hazard forecasting, risk communication, and decision-making. This perspective explores the transformative potential of integrated Artificial Intelligence (AI) modeling. We highlight the role of AI in developing multi-hazard EWSs that integrate Meteorological and Geospatial foundation models (FMs) for impact prediction. A user-centric approach with intuitive interfaces and community feedback is emphasized to improve crisis management. To address climate risk complexity, we advocate for causal AI models to avoid spurious predictions and stress the need for responsible AI practices. We highlight the FATES (Fairness, Accountability, Transparency, Ethics, and Sustainability) principles as essential for equitable and trustworthy AI-based Early Warning Systems for all. We further advocate for decadal EWSs, leveraging climate ensembles and generative methods to enable long-term, spatially resolved forecasts for proactive climate adaptation.
Matthias Körschens, Solveig Franziska Bucher, Paul Bodesheim, Joachim Denzler, Christine Römermann:
PlantCAPNet: A Deep Learning System For Image-based Plant Cover and Phenology Analysis.
Ecological Informatics.
91 :
pp. 103413.
2025.
[bibtex]
[pdf]
[web]
[doi]
[abstract]
Plant community data, like the species composition of the community and the phenology of the occurring species, are paramount for environmental research. Such data can be used to detect species responses to environmental changes, but the collection is very laborious, slow, and prone to human error. These detriments can be counteracted with automatic camera systems in combination with machine learning approaches that are able to extract the vegetation data from collected images in a consistent and fast manner. We introduce PlantCAPNet, an application to automate the analysis of herbaceous plant communities from images by extracting plant cover and phenology, addressing the tedious and biased nature of manual field collection. The system has an easy-to-use web interface with a single image prediction tool, a batch prediction function for image series, and a training interface for users to build novel models. We offer PlantCAPNet with two operational modes: a 'cover-trained' mode for predicting cover and phenology using user-provided labeled data, and a 'zero-shot' mode capable of predicting cover using only web-sourced data, thus lowering the barrier for entry. Our evaluations show that PlantCAPNet performs comparably or better than independent human experts in estimating plant cover. The zero-shot method reflects the reference estimates with a correlation of 0.625, and the cover-trained method with one of 0.790 compared to a correlation of 0.620 from independent experts. Moreover, we show that our system performs reliably for dataset with few species, and the cover prediction is also reliable for the most abundant species in datasets with many species, while the phenology prediction is dependent on the amount of training data. In total, our system offers higher consistency than human experts, and enables the extraction of high-temporal-resolution ecological data, facilitating novel environmental research.
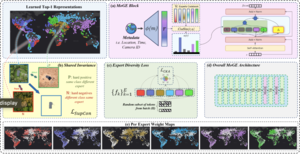
Moien Rangzan, Gregory Duveiller, Maha Shadaydeh, Markus Reichstein, Joachim Denzler:
Mixture of Geographical Experts: Disentangling Earth.
EurIPS Workshop on Advances in Representation Learning for Earth Observation (EurIPS-WS).
2025.
[bibtex]
[web]
[abstract]
Most domain generalization techniques assume there exists a stable predictive relationship from input features to labels across domains, an assumption that breaks in many Earth observation tasks, where stable signals are weak or geographically confined. We introduce a sparse, geo-routed Mixture of Geographical Experts (MoGE) that explicitly disentangles global invariance from spatial variation. A shared invariant expert captures features that hold everywhere, while metadata-driven routing activates a subset of geo-specialized experts forced to learn region-specific cues. This separation lets experts self-organize into continuous, concept-consistent regions, discovering domains rather than handcrafting them, while the invariant path remains robust across space. MoGE's factorization yields strong performance on generalization benchmarks.

Nathalie Demme, Maha Shadaydeh, Laura Schieder, Claus Doerfel, Stella Jähkel, Knut Holthoff, Hans Proquitté, Joachim Denzler, Jürgen Graf:
Towards unobtrusive sleep stage classification in preterm infants using machine learning.
Biomedical Signal Processing and Control.
108 :
pp. 107904.
2025.
[bibtex]
[pdf]
[web]
[doi]
[code]
[supplementary]
[abstract]
In the neonatal intensive care unit (NICU), preterm infants are usually unable to fulfil their sleep demands due to frequent disruptions. Real-time sleep monitoring could be an essential tool not only to shift elective care to their wake periods but also to track their developmental sleep profile as an indicator of healthy brain maturation. The current gold standard for sleep measurement, polysomnography, is invasive and labour-intensive, limiting its applicability for continuous monitoring. We propose an automatic sleep stage classification method using only the routinely available electrocardiogram (ECG) and patient movement data recorded with a piezo mat. For this study we recorded data from 28 preterm infants (13 females and 15 males) at 35.7 \pm 0.5 weeks postmentrual age. We employed a support vector machine (SVM) to classify sleep stages into wakefulness (W), active sleep (AS), and quiet sleep (QS). The combined piezo + ECG model demonstrated superior accuracy (92 \%) and strong agreement with expert annotations (Cohen's kappa = 0.83) compared to ECG-only or piezo-only models. This approach offers a reliable, unobtrusive solution for continuous sleep monitoring in NICUs, facilitating individualised, sleep-based medical care for preterm infants.
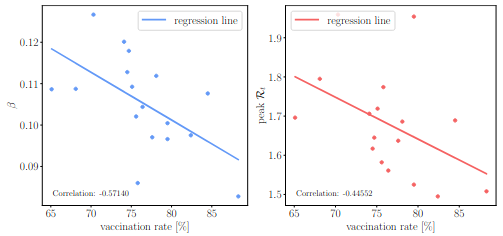
Phillip Rothenbeck, Sai Karthikeya Vemuri, Niklas Penzel, Joachim Denzler:
Modeling COVID-19 Dynamics in German States Using Physics-Informed Neural Networks.
EurIPS Workshop on Differentiable Systems and Scientific Machine Learning (EurIPS-WS).
2025.
[bibtex]
[pdf]
[doi]
[abstract]
The COVID-19 pandemic has highlighted the need for quantitative modeling and analysis to understand real-world disease dynamics. In particular, post hoc analyses using compartmental models offer valuable insights into the effectiveness of public health interventions, such as vaccination strategies and containment policies. However, such compartmental models like SIR (Susceptible-Infectious-Recovered) often face limitations in directly incorporating noisy observational data. In this work, we employ Physics-Informed Neural Networks (PINNs) to solve the inverse problem of the SIR model using infection data from the Robert Koch Institute (RKI). Our main contribution is a fine-grained, spatio-temporal analysis of COVID-19 dynamics across all German federal states over a three-year period. We estimate state-specific transmission and recovery parameters and time-varying reproduction number (R\_t) to track the pandemic progression. The results highlight strong variations in transmission behavior across regions, revealing correlations with vaccination uptake and temporal patterns associated with major pandemic phases. Our findings demonstrate the utility of PINNs in localized, long-term epidemiological modeling.

Sven Sickert, Maria Gogolev, Niklas Penzel, Tim Büchner, Joachim Denzler:
Modifying Generative Distributions in Latent Diffusion Models to Improve Alignment with Desired Properties.
International Conference on Machine Vision and Applications (MVA).
Pages 1-6.
2025.
[bibtex]
[doi]
[presentation]
[abstract]
Models like DALL-E and Stable Diffusion substantially improved image generation. While visually convincing, they still exhibit distinct differences compared to real-world images and desired image distributions. Previous studies already identified issues at a spectral level. We also find discrepancies in terms of style authenticity and aesthetics. Based on these insights we investigate three distinct strategies to modify such models and enhance their alignment for selected image distributions of artworks. First, prompt optimization can be done without updating the model, but has limited efficacy. Fine-tuning the U-Net component can enhance denoising capabilities, leading to improved image quality. Finally, modifying the image decoder can help correct spectral misalignments. Our experiments on the ArtEmis dataset using three complementary measures show that high-frequency artifacts remain challenging, but alignment can usually be improved by at least 10\%.

Tim Büchner, Christoph Anders, Orlando Guntinas-Lichius, Joachim Denzler:
Electromyography-Informed Facial Expression Reconstruction for Physiological-Based Synthesis and Analysis.
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).
2025.
Highlight Paper
[bibtex]
[pdf]
[web]
[doi]
[presentation]
[supplementary]
[abstract]
The relationship between muscle activity and resulting facial expressions is crucial for various fields, including psychology, medicine, and entertainment. The synchronous recording of facial mimicry and muscular activity via surface electromyography (sEMG) provides a unique window into these complex dynamics. Unfortunately, existing methods for facial analysis cannot handle electrode occlusion, rendering them ineffective. Even with occlusion-free reference images of the same person, variations in expression intensity and execution are unmatchable. Our electromyography-informed facial expression reconstruction (EIFER) approach is a novel method to restore faces under sEMG occlusion faithfully in an adversarial manner. We decouple facial geometry and visual appearance (e.g., skin texture, lighting, electrodes) by combining a 3D Morphable Model (3DMM) with neural unpaired image-to-image translation via reference recordings. Then, EIFER learns a bidirectional mapping between 3DMM expression parameters and muscle activity, establishing correspondence between the two domains. We validate the effectiveness of our approach through experiments on a dataset of synchronized sEMG recordings and facial mimicry, demonstrating faithful geometry and appearance reconstruction. Further, we synthesize expressions based on muscle activity and how observed expressions can predict dynamic muscle activity. Consequently, EIFER introduces a new paradigm for facial electromyography, which could be extended to other forms of multi-modal face recordings.

Tim Büchner, Sven Sickert, Gerd F. Volk, Orlando Guntinas-Lichius, Joachim Denzler:
Assessing 3D Volumetric Asymmetry in Facial Palsy Patients via Advanced Multi-view Landmarks and Radial Curves.
Machine Vision and Applications.
36 (1) :
2025.
[bibtex]
[pdf]
[doi]
[abstract]
The research on facial palsy, a unilateral palsy of the facial nerve, is a complex field with many different causes and symptoms. Even modern approaches to evaluate the facial palsy state rely mainly on stills and 2D videos of the face and rarely on dynamic 3D information. Many of these analysis and visualization methods require manual intervention, which is time-consuming and error-prone. Moreover, they often depend on alignment algorithms or Euclidean measurements and consider only static facial expressions. Volumetric changes by muscle movement are essential for facial palsy analysis but require manual extraction. We propose to extract an estimated unilateral volumetric description for dynamic expressions from 3D scans. Accurate landmark positioning is required for processing the unstructured facial scans. In our case, it is attained via a multi-view method compatible with any existing 2D predictors. We analyze prediction stability and robustness against head rotation during video sequences. Further, we investigate volume changes in static and dynamic facial expressions for 34 patients with unilateral facial palsy and visualize volumetric disparities on the face surface. In a case study, we observe a decrease in the volumetric difference between the face sides during happy expressions at the beginning (13.8 +- 10.0 mm3) and end (12.8 +- 10.3 mm3) of a ten-day biofeedback therapy. The neutral face kept a consistent volume range of 11.8-12.1 mm3. The reduced volumetric difference after therapy indicates less facial asymmetry during movement, which can be used to monitor and guide treatment decisions. Our approach minimizes human intervention, simplifying the clinical routine and interaction with 3D scans to provide a more comprehensive analysis of facial palsy.

Dong Han, Yong Li, Joachim Denzler:
Privacy-Preserving Face Recognition in Hybrid Frequency-Color Domain.
International Conference on Computer Vision Theory and Applications (VISAPP).
Pages 536-546.
2024.
[bibtex]
[web]
[doi]
[abstract]
Face recognition technology has been deployed in various real-life applications. The most sophisticated deep learning-based face recognition systems rely on training millions of face images through complex deep neural networks to achieve high accuracy. It is quite common for clients to upload face images to the service provider in order to access the model inference. However, the face image is a type of sensitive biometric attribute tied to the identity information of each user. Directly exposing the raw face image to the service provider poses a threat to the user's privacy. Current privacy-preserving approaches to face recognition focus on either concealing visual information on model input or protecting model output face embedding. The noticeable drop in recognition accuracy is a pitfall for most methods. This paper proposes a hybrid frequency-color fusion approach to reduce the input dimensionality of face recognition in the frequency domain. Moreover, sparse color information is also introduced to alleviate significant accuracy degradation after adding differential privacy noise. Besides, an identity-specific embedding mapping scheme is applied to protect original face embedding by enlarging the distance among identities. Lastly, secure multiparty computation is implemented for safely computing the embedding distance during model inference. The proposed method performs well on multiple widely used verification datasets. Moreover, it has around 2.6\% to 4.2\% higher accuracy than the state-of-the-art in the 1:N verification scenario.

Dong Han, Yufan Jiang, Yong Li, Ricardo Mendes, Joachim Denzler:
Robust Skin Color Driven Privacy-Preserving Face Recognition via Function Secret Sharing.
International Conference on Image Processing (ICIP).
Pages 3965-3971.
2024.
[bibtex]
[web]
[doi]
[abstract]
In this work, we leverage the pure skin color patch from the face image as the additional information to train an auxiliary skin color feature extractor and face recognition model in parallel to improve performance of state-of-the-art (SOTA) privacy-preserving face recognition (PPFR) systems. Our solution is robust against black-box attacking and well-established generative adversarial network (GAN) based image restoration. We analyze the potential risk in previous work, where the proposed cosine similarity computation might directly leak the protected precomputed embedding stored on the server side. We propose a Function Secret Sharing (FSS) based face embedding comparison protocol without any intermediate result leakage. In addition, we show in experiments that the proposed protocol is more efficient compared to the Secret Sharing (SS) based protocol.

Ferdinand Rewicki, Jakob Gawlikowski, Julia Niebling, Joachim Denzler:
Unraveling Anomalies in Time: Unsupervised Discovery and Isolation of Anomalous Behavior in Bio-regenerative Life Support System Telemetry.
European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML PKDD).
Pages 207-222.
2024.
[bibtex]
[web]
[doi]
[abstract]
The detection of abnormal or critical system states is essential in condition monitoring. While much attention is given to promptly identifying anomalies, a retrospective analysis of these anomalies can significantly enhance our comprehension of the underlying causes of observed undesired behavior. This aspect becomes particularly critical when the monitored system is deployed in a vital environment. In this study, we delve into anomalies within the domain of Bio-Regenerative Life Support Systems (BLSS) for space exploration and analyze anomalies found in telemetry data stemming from the EDEN ISS space greenhouse in Antarctica. We employ time series clustering on anomaly detection results to categorize various types of anomalies in both uni- and multivariate settings. We then assess the effectiveness of these methods in identifying systematic anomalous behavior. Additionally, we illustrate that the anomaly detection methods MDI and DAMP produce complementary results, as previously indicated by research.

Gideon Stein, Jonas Ziemer, Carolin Wicker, Jannik Jaenichen, Gabriele Demisch, Daniel Kloepper, Katja Last, Joachim Denzler, Christiane Schmullius, Maha Shadaydeh, Clémence Dubois:
Data-driven Prediction of Large Infrastructure Movements Through Persistent Scatterer Time Series Modeling.
IEEE International Geoscience and Remote Sensing Symposium (IGARSS).
pp. 8669-8673.
2024.
[bibtex]
[pdf]
[doi]
[abstract]
Deformation monitoring is a crucial task for dam operators, particularly given the rise in extreme weather events associated with climate change. Further, quantifying the expected deformations of a dam is a central part of this endeavor. Current methods rely on in situ data (i.e., water level and temperature) to predict the expected deformations of a dam (typically represented by plumb or trigonometric measurements). However, not all dams are equipped with extensive measurement techniques, resulting in infrequent monitoring. Persistent Scatterer Interferometry (PSI) can overcome this limitation, enabling an alternative monitoring scheme for such infrastructures. This study introduces a novel monitoring approach to quantify expected deformations of gravity dams in Germany by integrating the PSI technique with in situ data. Further, it proposes a methodology to find proper statistical representations in a data-driven manner, which extends established statistical approaches. The approach demonstrates plausible deformation patterns as well as accurate predictions for validation data (mean absolute error=1.81 mm), confirming the benefits of the proposed method.

Gideon Stein, Maha Shadaydeh, Joachim Denzler:
Embracing the Black Box: Heading Towards Foundation Models for Causal Discovery from Time Series Data.
AAAI Workshop on AI for Time-series (AAAI-WS).
2024.
[bibtex]
[pdf]
[web]
[abstract]
Causal discovery from time series data encompasses many existing solutions, including those based on deep learning techniques. However, these methods typically do not endorse one of the most prevalent paradigms in deep learning: End-to-end learning. To address this gap, we explore what we call Causal Pretraining. A methodology that aims to learn a direct mapping from multivariate time series to the underlying causal graphs in a supervised manner. Our empirical findings suggest that causal discovery in a supervised manner is possible, assuming that the training and test time series samples share most of their dynamics. More importantly, we found evidence that the performance of Causal Pretraining can increase with data and model size, even if the additional data do not share the same dynamics. Further, we provide examples where causal discovery for real-world data with causally pretrained neural networks is possible within limits. We argue that this hints at the possibility of a foundation model for causal discovery.

Gideon Stein, Sai Karthikeya Vemuri, Yuanyuan Huang, Anne Ebeling, Nico Eisenhauer, Maha Shadaydeh, Joachim Denzler:
Investigating the Effects of Plant Diversity on Soil Thermal Diffusivity Using Physics- Informed Neural Networks.
ICLR Workshop on AI4DifferentialEquations In Science (ICLR-WS).
2024.
[bibtex]
[pdf]
[web]
[abstract]
The influence of plant diversity on the stability of ecosystems is well-reported in the literature. However, the exact mechanisms responsible for this effect are still a topic of debate. Recently, soil temperature stability was proposed as one possible candidate for such a mechanism. To further evaluate this hypothesis, we investigate the relationship between plant diversity and the thermal diffusivity of the soil during the very dry and hot summer of 2018 in Central Europe. By leveraging Physics-Informed Neural Networks and a 30-minute resolution soil temperature dataset from the Jena Experiment, we find an inverse relationship between plant diversity and the thermal diffusivity of the associated soil. With this, we provide support for the idea of plant diversity as a natural protection against climate-related ecosystem change.

Laines Schmalwasser, Jakob Gawlikowski, Joachim Denzler, Julia Niebling:
Exploiting Text-Image Latent Spaces for the Description of Visual Concepts.
International Conference on Pattern Recognition (ICPR).
Pages 109-125.
2024.
[bibtex]
[doi]
[abstract]
Concept Activation Vectors (CAVs) offer insights into neural network decision-making by linking human friendly concepts to the model's internal feature extraction process. However, when a new set of CAVs is discovered, they must still be translated into a human understandable description. For image-based neural networks, this is typically done by visualizing the most relevant images of a CAV, while the determination of the concept is left to humans. In this work, we introduce an approach to aid the interpretation of newly discovered concept sets by suggesting textual descriptions for each CAV. This is done by mapping the most relevant images representing a CAV into a text-image embedding where a joint description of these relevant images can be computed. We propose utilizing the most relevant receptive fields instead of full images encoded. We demonstrate the capabilities of this approach in multiple experiments with and without given CAV labels, showing that the proposed approach provides accurate descriptions for the CAVs and reduces the challenge of concept interpretation.

Lukas Schuhmann, Tim Büchner, Martin Heinrich, Gerd Fabian Volk, Joachim Denzler, Orlando Guntinas-Lichius:
Automated Analysis of Spontaneous Eye Blinking in Patients with Acute Facial Palsy or Facial Synkinesis.
Scientific Reports.
14 (1) :
pp. 17726.
2024.
[bibtex]
[pdf]
[web]
[doi]
[abstract]
Although patients with facial palsy often complain of disturbed eye blinking which may lead to visual impairment, a blinking analysis is not part of routine grading of facial palsy. Twenty minutes of spontaneous eye blinking at rest of 30 patients with facial palsy (6 with acute palsy; 24 patients with facial synkinesis; median age: 58~years, 67\% female), and 30 matched healthy probands (median age: 57~years; 67\% female) was smart phone video recorded. A custom computer program automatically extracted eye measures and determined the eye closure rate (eye aspect ratio [EAR]), blink frequency, and blink duration. Facial Clinimetric Evaluation (FaCE), Facial Disability Index (FDI) were assessed as patient-reported outcome measures. The minimal EAR, i.e., minimal visible eye surface during blinking, was significantly higher on the paretic side in patients with acute facial palsy than in patients with synkinesis or in healthy controls. The blinking frequency on the affected side was significantly lower in both patient groups compared to healthy controls. Vice versa, blink duration was longer in both patient groups. There was no clear correlation between the blinking values and FaCE and FDI. Blinking parameters are easy to estimate automatically and add a functionally important parameter to facial grading.

Maha Shadaydeh, Joachim Denzler, Mirco Migliavacca:
Physics Informed Modeling of Ecosystem Respiration via Dynamic Mode Decomposition with Control Input.
ICLR Workshop on Machine Learning for Remote Sensing (ICLR-WS).
2024.
[bibtex]
[web]
[abstract]
Ecosystem respiration (Reco) represents a significant component of the global carbon cycle, and accurate characterization of its dynamics is essential for a comprehensive understanding of ecosystem-climate interactions and the impacts of climate extremes on the ecosystem. In this paper, we present a novel data-driven and physics-aware method for estimating Reco dynamics using the dynamic mode decomposition with control input (DMDc), an emerging tool for analyzing nonlinear dynamical systems. The proposed model represents Reco as a state space model with an autonomous component and an exogenous control input. The control input can be any ecosystem driver(s), such as air temperature, soil temperature, or soil water content. This unique modeling approach allows controlled intervention to study the effects of different inputs on the system. We further discuss using time delay embedding of both components to characterize Reco dynamics. Experimental results using Fluxnet2015 data show that the prediction accuracy of Reco dynamics achieved with DMDc is comparable to state-of-the-art methods, making it a promising tool for analyzing the dynamic behavior of different vegetation ecosystems on multi-temporal scales in response to different climatic drivers.

Matthias Körschens, Solveig Franziska Bucher, Paul Bodesheim, Josephine Ulrich, Joachim Denzler, Christine Römermann:
Determining the Community Composition of Herbaceous Species from Images using Convolutional Neural Networks.
Ecological Informatics.
80 :
pp. 102516.
2024.
[bibtex]
[pdf]
[web]
[doi]
[abstract]
Global change has a detrimental impact on the environment and changes biodiversity patterns, which can be observed, among others, via analyzing changes in the composition of plant communities. Typically, vegetation relevées are done manually, which is time-consuming, laborious, and subjective. Applying an automatic system for such an analysis that can also identify co-occurring species would be beneficial as it is fast, effortless to use, and consistent. Here, we introduce such a system based on Convolutional Neural Networks for automatically predicting the species-wise plant cover. The system is trained on freely available image data of herbaceous plant species from web sources and plant cover estimates done by experts. With a novel extension of our original approach, the system can even be applied directly to vegetation images without requiring such cover estimates. Our extended approach, not utilizing dedicated training data, performs similarly to humans concerning the relative species abundances in the vegetation relevées. When trained on dedicated training annotations, it reflects the original estimates more closely than (independent) human experts, who manually analyzed the same sites. Our method is, with little adaptation, usable in novel domains and could be used to analyze plant community dynamics and responses of different plant species to environmental changes.

Nico Eisenhauer, Karin Frank, Alexandra Weigelt, Bartosz Bartkowski, Rémy Beugnon, Katja Liebal, Miguel Mahecha, Martin Quaas, Djamil Al-Halbouni, Ana Bastos, Friedrich J. Bohn, Mariana Madruga de Brito, Joachim Denzler, Hannes Feilhauer, Rico Fischer, Immo Fritsche, Claudia Guimaraes-Steinicke, Martin Hänsel, Daniel B. M. Haun, Hartmut Herrmann, Andreas Huth, Heike Kalesse-Los, Michael Koetter, Nina Kolleck, Melanie Krause, Marlene Kretschmer, Pedro J. Leitão, Torsten Masson, Karin Mora, Birgit Müller, Jian Peng, Mira L. Pöhlker, Leonie Ratzke, Markus Reichstein, Solveig Richter, Nadja Rüger, Beatriz Sánchez-Parra, Maha Shadaydeh, Sebastian Sippel, Ina Tegen, Daniela Thrän, Josefine Umlauft, Manfred Wendisch, Kevin Wolf, Christian Wirth, Hannes Zacher, Sönke Zaehle, Johannes Quaas:
A Belowground Perspective on the Nexus Between Biodiversity Change, Climate Change, and Human Well-being.
Journal of Sustainable Agriculture and Environment.
3 (2) :
pp. e212108.
2024.
[bibtex]
[web]
[doi]
[abstract]
Abstract Soil is central to the complex interplay among biodiversity, climate, and society. This paper examines the interconnectedness of soil biodiversity, climate change, and societal impacts, emphasizing the urgent need for integrated solutions. Human-induced biodiversity loss and climate change intensify environmental degradation, threatening human well-being. Soils, rich in biodiversity and vital for ecosystem function regulation, are highly vulnerable to these pressures, affecting nutrient cycling, soil fertility, and resilience. Soil also crucially regulates climate, influencing energy, water cycles, and carbon storage. Yet, climate change poses significant challenges to soil health and carbon dynamics, amplifying global warming. Integrated approaches are essential, including sustainable land management, policy interventions, technological innovations, and societal engagement. Practices like agroforestry and organic farming improve soil health and mitigate climate impacts. Effective policies and governance are crucial for promoting sustainable practices and soil conservation. Recent technologies aid in monitoring soil biodiversity and implementing sustainable land management. Societal engagement, through education and collective action, is vital for environmental stewardship. By prioritizing interdisciplinary research and addressing key frontiers, scientists can advance understanding of the soil biodiversity–climate change–society nexus, informing strategies for environmental sustainability and social equity.

Niklas Penzel, Gideon Stein, Joachim Denzler:
Reducing Bias in Pre-trained Models by Tuning while Penalizing Change.
International Conference on Computer Vision Theory and Applications (VISAPP).
Pages 90-101.
2024.
[bibtex]
[web]
[doi]
[abstract]
Deep models trained on large amounts of data often incorporate implicit biases present during training time. If later such a bias is discovered during inference or deployment, it is often necessary to acquire new data and retrain the model. This behavior is especially problematic in critical areas such as autonomous driving or medical decision-making. In these scenarios, new data is often expensive and hard to come by. In this work, we present a method based on change penalization that takes a pre-trained model and adapts the weights to mitigate a previously detected bias. We achieve this by tuning a zero-initialized copy of a frozen pre-trained network. Our method needs very few, in extreme cases only a single, examples that contradict the bias to increase performance. Additionally, we propose an early stopping criterion to modify baselines and reduce overfitting. We evaluate our approach on a well-known bias in skin lesion classification and three other datasets from the domain shift literature. We find that our approach works especially well with very few images. Simple fine-tuning combined with our early stopping also leads to performance benefits for a larger number of tuning samples.

Sai Karthikeya Vemuri, Tim Büchner, Joachim Denzler:
Estimating Soil Hydraulic Parameters for Unsaturated Flow using Physics-Informed Neural Networks.
International Conference on Computational Science (ICCS).
Pages 338-351.
2024.
[bibtex]
[pdf]
[doi]
[abstract]
Water movement in soil is essential for weather monitoring, prediction of natural disasters, and agricultural water management. Richardson-Richards' equation (RRE) is the characteristic partial differential equation for studying soil water movement. RRE is a non-linear PDE involving water potential, hydraulic conductivity, and volumetric water content. This equation has underlying non-linear parametric relationships called water retention curves (WRCs) and hydraulic conductivity functions (HCFs). This two-level non-linearity makes the problem of unsaturated water flow of soils challenging to solve. Physics-Informed Neural Networks (PINNs) offer a powerful paradigm to combine physics in data-driven techniques. From noisy or sparse observations of one variable (water potential), we use PINNs to learn the complete system, estimate the parameters of the underlying model, and further facilitate the prediction of infiltration and discharge. We employ training on RRE, WRC, HCF, and measured values to resolve two-level non-linearity directly instead of explicitly deriving water potential or volumetric water content-based formulations. The parameters to be estimated are made trainable with initialized values. We take water potential data from simulations and use this data to solve the inverse problem with PINN and compare estimated parameters, volumetric water content, and hydraulic conductivity with actual values. We chose different types of parametric relationships and wetting conditions to show the approach's effectiveness.

Sai Karthikeya Vemuri, Tim Büchner, Julia Niebling, Joachim Denzler:
Functional Tensor Decompositions for Physics-Informed Neural Networks.
International Conference on Pattern Recognition (ICPR).
Pages 32-46.
2024.
Best Paper Award
[bibtex]
[pdf]
[web]
[doi]
[code]
[abstract]
Physics-Informed Neural Networks (PINNs) have shown continuous promise in approximating partial differential equations (PDEs), although they remain constrained by the curse of dimensionality. In this paper, we propose a generalized PINN version of the classical variable separable method. To do this, we first show that, using the universal approximation theorem, a multivariate function can be approximated by the outer product of neural networks, whose inputs are separated variables. We leverage tensor decomposition forms to separate the variables in a PINN setting. By employing Canonic Polyadic (CP), Tensor-Train (TT), and Tucker decomposition forms within the PINN framework, we create robust architectures for learning multivariate functions from separate neural networks connected by outer products. Our methodology significantly enhances the performance of PINNs, as evidenced by improved results on complex high-dimensional PDEs, including the 3d Helmholtz and 5d Poisson equations, among others. This research underscores the potential of tensor decomposition-based variably separated PINNs to surpass the state-of-the-art, offering a compelling solution to the dimensionality challenge in PDE approximation.

Shijie Jiang, Lily-belle Sweet, Georgios Blougouras, Alexander Brenning, Wantong Li, Markus Reichstein, Joachim Denzler, Wei Shangguan, Guo Yu, Feini Huang, Jakob Zscheischler:
How Interpretable Machine Learning Can Benefit Process Understanding in the Geosciences.
Earth's Future.
12 (7) :
pp. e2024EF004540.
2024.
[bibtex]
[web]
[doi]
[abstract]
Abstract Interpretable Machine Learning (IML) has rapidly advanced in recent years, offering new opportunities to improve our understanding of the complex Earth system. IML goes beyond conventional machine learning by not only making predictions but also seeking to elucidate the reasoning behind those predictions. The combination of predictive power and enhanced transparency makes IML a promising approach for uncovering relationships in data that may be overlooked by traditional analysis. Despite its potential, the broader implications for the field have yet to be fully appreciated. Meanwhile, the rapid proliferation of IML, still in its early stages, has been accompanied by instances of careless application. In response to these challenges, this paper focuses on how IML can effectively and appropriately aid geoscientists in advancing process understanding--areas that are often underexplored in more technical discussions of IML. Specifically, we identify pragmatic application scenarios for IML in typical geoscientific studies, such as quantifying relationships in specific contexts, generating hypotheses about potential mechanisms, and evaluating process-based models. Moreover, we present a general and practical workflow for using IML to address specific research questions. In particular, we identify several critical and common pitfalls in the use of IML that can lead to misleading conclusions, and propose corresponding good practices. Our goal is to facilitate a broader, yet more careful and thoughtful integration of IML into Earth science research, positioning it as a valuable data science tool capable of enhancing our current understanding of the Earth system.

Tim Büchner, Niklas Penzel, Orlando Guntinas-Lichius, Joachim Denzler:
Facing Asymmetry - Uncovering the Causal Link between Facial Symmetry and Expression Classifiers using Synthetic Interventions.
Asian Conference on Computer Vision (ACCV).
2024.
[bibtex]
[pdf]
[web]
[doi]
[abstract]
Understanding expressions is vital for deciphering human behavior, and nowadays, end-to-end trained black box models achieve high performance. Due to the black-box nature of these models, it is unclear how they behave when applied out-of-distribution. Specifically, these models show decreased performance for unilateral facial palsy patients. We hypothesize that one crucial factor guiding the internal decision rules is facial symmetry. In this work, we use insights from causal reasoning to investigate the hypothesis. After deriving a structural causal model, we develop a synthetic interventional framework. This approach allows us to analyze how facial symmetry impacts a network's output behavior while keeping other factors fixed. All 17 investigated expression classifiers significantly lower their output activations for reduced symmetry. This result is congruent with observed behavior on real-world data from healthy subjects and facial palsy patients. As such, our investigation serves as a case study for identifying causal factors that influence the behavior of black-box models.

Tim Büchner, Niklas Penzel, Orlando Guntinas-Lichius, Joachim Denzler:
The Power of Properties: Uncovering the Influential Factors in Emotion Classification.
International Conference on Pattern Recognition and Artificial Intelligence (ICPRAI).
2024.
[bibtex]
[pdf]
[web]
[doi]
[abstract]
Facial expression-based human emotion recognition is a critical research area in psychology and medicine. State-of-the-art classification performance is only reached by end-to-end trained neural networks. Nevertheless, such black-box models lack transparency in their decisionmaking processes, prompting efforts to ascertain the rules that underlie classifiers' decisions. Analyzing single inputs alone fails to expose systematic learned biases. These biases can be characterized as facial properties summarizing abstract information like age or medical conditions. Therefore, understanding a model's prediction behaviorrequires an analysis rooted in causality along such selected properties. We demonstrate that up to 91.25\% of classifier output behavior changes are statistically significant concerning basic properties. Among those are age, gender, and facial symmetry. Furthermore, the medical usage of surface electromyography significantly influences emotion prediction. We introduce a workflow to evaluate explicit properties and their impact. These insights might help medical professionals select and apply classifiers regarding their specialized data and properties.

Tim Büchner, Oliver Mothes, Orlando Guntinas-Lichius, Joachim Denzler:
JeFaPaTo - A Joint Toolbox for Blinking Analysis and Facial Features Extraction.
Journal of Open Source Software.
9 (97) :
pp. 6425.
2024.
[bibtex]
[pdf]
[doi]
[code]
[abstract]
Welcome to JeFaPaTo, the Jena Facial Palsy Tool! This powerful tool is designed to assist in various medical and psychological applications by providing accurate facial feature extraction and analysis. It combines the requirements of a medical environment with the possibilities of modern computer vision and machine learning. Our goal is to allow medical professionals to use state-of-the-art technology without needing to write custom algorithms. We provide the libraries and an interface to the commonly used mediapipe library of Google, a powerful tool for facial landmark extraction, and now even offers the distinction into facial movements. Additionally, our software can be extended to include new methods and algorithms. We are interested in human blinking behavior and scrutinize it with high temporal videos using the EAR-Score (Eye-Aspect-Ratio) to detect blinking and eye closure. This feature is used to analyze patients with facial palsy blinking behavior.

Tim Büchner, Sven Sickert, Gerd F. Volk, Christoph Anders, Joachim Denzler, Orlando Guntinas-Lichius:
Reducing the Gap Between Mimics and Muscles by Enabling Facial Feature Analysis during sEMG Recordings [Abstract].
Congress of the Confederation of European ORL-HNS.
2024.
[bibtex]
[pdf]
[web]
[abstract]
Introduction: Surface electromyography (sEMG) is an effective technique for studying facial muscles. However, although it would be valuable, the simultaneous acquisition of 2D facial movement videos creates incompatibilities with analysis methodologies because the sEMG electrodes and wires obstruct part of the face. The present study overcame these limitations using machine learning mechanisms to make the sEMG electrodes disappear artificially (artificial videos with removed electrodes). Material \& Methods: We recorded 36 probands (18-67 years, 17 male, 19 female) and measured their muscular activity using two sEMG schematics [1], [2], totaling 60 electrodes attached to the face [3]. Each proband mimicked the six basic emotions four times randomly, guided by an instructional video. Minimal Change CycleGANs were used to make reconstruction videos without sEMG electrodes [4], [5]. Finally, the emotions expressed by the probands were classified with ResMaskNet [6]. Results: We quantitatively compared the sEMG data and reconstructed videos with reference recordings. The artificial videos achieved a Fréchet Inception Distance [10] score of 0.50 \pm 0.74, while sEMG videos scored 10.46 \pm 2.10, indicating high visual quality. With electrodes attached, we yield an emotion classification accuracy of 34 \pm 10\% (equivalent to two-category random guessing). Our approach obtained up to 83\% accuracy for the removed electrodes. Conclusions: Our techniques and studies enable simultaneous analysis of muscle activity and facial movements. We reconstruct facial regions obstructed by electrodes and wires, preserving the underlying expression. Our data-driven and label-free approach enables established methods without further modifications. Supported by DFG DE-735/15-1 and DFG GU-463/12-1

Tim Büchner, Sven Sickert, Gerd F. Volk, Joachim Denzler, Orlando Guntinas-Lichius:
An Automatic, Objective Method to Measure and Visualize Volumetric Changes in Patients with Facial Palsy during 3D Video Recordings [Abstract].
95th Annual Meeting German Society of Oto-Rhino-Laryngology, Head and Neck Surgery e. V., Bonn.
2024.
[bibtex]
[web]
[doi]
[abstract]
Introduction: Using grading systems, the severity of facial palsy is typically classified through static 2D images. These approaches fail to capture crucial facial attributes, such as the depth of the nasolabial fold. We present a novel technique that uses 3D video recordings to overcome this limitation. Our method automatically characterizes the facial structure, calculates volumetric dispari8es between the affected and contralateral side, and includes an intuitive visualization. Material: 35 patients (mean age 51 years, min. 25, max. 72; 7 \male, 28 \venus) with unilateral chronic synkinetic facial palsy were enrolled. We utilized the 3dMD face system (3dMD LCC, Georgia, USA) to record their facial movements while they mimicked happy facial expressions four times. Each recording lasted 6.5 seconds, with a total of 140 videos. Results: We found a difference in volume between the neutral and happy expressions: 11.7 \pm 9.1 mm3 and 13.73 \pm 10.0 mm3 , respectively. This suggests that there is a higher level of asymmetry during movements. Our process is fully automa8c without human intervention, highlights the impacted areas, and emphasizes the differences between the affected and contralateral side. Discussion: Our data-driven method allows healthcare professionals to track and visualize patients' volumetric changes automatically, facilitating personalized treatments. It mitigates the risk of human biases in therapeutic evaluations and effectively transitions from static 2D images to dynamic 4D assessments of facial palsy state. Supported by DFG DE-735/15-1 and DFG GU-463/12-1

Tim Büchner, Sven Sickert, Gerd F. Volk, Martin Heinrich, Joachim Denzler, Orlando Guntinas-Lichius:
Measuring and Visualizing Volumetric Changes Before and After 10-Day Biofeedback Therapy in Patients with Synkinetic Facial Palsy Using 3D Video Recordings [Abstract].
Congress of the Confederation of European ORL-HNS.
2024.
[bibtex]
[pdf]
[web]
[abstract]
Introduction: The severity of facial palsy is typically assessed using grading systems based on 2D image analysis [1]. Thus,the full range of facial features, especially depth information, is neglected. The present study employed 3D video-based methods to measure volume disparities during dynamic facial movements [2], [3], overcoming prior limitations. In addition, impacted areas were highlighted on the scan for an intuitive visualization. Material \& Methods: 35 patients (25-72 years; 28 female) with unilateral chronic synkinetic facial palsy were recorded with the 3dMD face system (3dMD LCC, Georgia, USA) at the beginning and end of 10-day biofeedback therapy focused on more symmetric facial expressions. The patients mimicked a happy facial expression four times, each recording lasting 6.5 seconds, totaling 280 videos. We used the Curvature of Radial Curves (CORC) [2] as a dense face descriptor and followed our previous method [3] to estimate the volume changes. Results: We found a reduced volume difference between contralateral and paretic side during the happy expression at therapy beginning (13.73 \pm 10.0 mm3) and end (12.79 \pm 10.3 mm 3). The neutral face remained unchanged in the ranges of 11.77-12.07 mm 3. This indicated a lower asymmetry during movements after therapy and could be used as an objective measurement during training for a successful therapy. Conclusions: Our data-driven method enables tracking and visualizing volume disparities between the paretic and contralateral sides. We reduce human bias during evaluation, personalize treatment, and shift 2D image assessments of facial palsy to dynamic 4D evaluations. Supported by DFG DE-735/15-1 and DFG GU-463/12-1

Tristan Piater, Niklas Penzel, Gideon Stein, Joachim Denzler:
When Medical Imaging Met Self-Attention: A Love Story That Didn't Quite Work Out.
International Conference on Computer Vision Theory and Applications (VISAPP).
Pages 149-158.
2024.
[bibtex]
[web]
[doi]
[abstract]
A substantial body of research has focused on developing systems that assist medical professionals during labor-intensive early screening processes, many based on convolutional deep-learning architectures. Recently, multiple studies explored the application of so-called self-attention mechanisms in the vision domain. These studies often report empirical improvements over fully convolutional approaches on various datasets and tasks. To evaluate this trend for medical imaging, we extend two widely adopted convolutional architectures with different self-attention variants on two different medical datasets. With this, we aim to specifically evaluate the possible advantages of additional self-attention. We compare our models with similarly sized convolutional and attention-based baselines and evaluate performance gains statistically. Additionally, we investigate how including such layers changes the features learned by these models during the training. Following a hyperparameter search, and contrary to our expectations, we observe no significant improvement in balanced accuracy over fully convolutional models. We also find that important features, such as dermoscopic structures in skin lesion images, are still not learned by employing self-attention. Finally, analyzing local explanations, we confirm biased feature usage. We conclude that merely incorporating attention is insufficient to surpass the performance of existing fully convolutional methods.

Wasim Ahmad, Maha Shadaydeh, Joachim Denzler:
Deep Learning-based Group Causal Inference in Multivariate Time-series.
AAAI Workshop on AI for Time-series (AAAI-WS).
2024.
[bibtex]
[pdf]
[web]
[abstract]
Causal inference in a nonlinear system of multivariate time series is instrumental in disentangling the intricate web of relationships among variables, enabling us to make more accurate predictions and gain deeper insights into real-world complex systems. Causality methods typically identify the causal structure of a multivariate system by considering the cause-effect relationship of each pair of variables while ignoring the collective effect of a group of variables or interactions involving more than two-time series variables. In this work, we test model invariance by group-level interventions on the trained deep networks to infer causal direction in groups of variables, such as climate and ecosystem, brain networks, etc. Extensive testing with synthetic and real-world time series data shows a significant improvement of our method over other applied group causality methods and provides us insights into real-world time series. The code for our method can be found at: https://github.com/wasimahmadpk/gCause.

Wasim Ahmad, Maha Shadaydeh, Joachim Denzler:
Regime Identification for Improving Causal Analysis in Non-stationary Timeseries.
arXiv preprint arXiv:2405.02315.
2024.
[bibtex]
[pdf]
[web]
[abstract]
Time series data from real-world systems often display non-stationary behavior, indicating varying statistical characteristics over time. This inherent variability poses significant challenges in deciphering the underlying structural relationships within the data, particularly in correlation and causality analyses, model stability, etc. Recognizing distinct segments or regimes within multivariate time series data, characterized by relatively stable behavior and consistent statistical properties over extended periods, becomes crucial. In this study, we apply the regime identification (RegID) technique to multivariate time series, fundamentally designed to unveil locally stationary segments within data. The distinguishing features between regimes are identified using covariance matrices in a Riemannian space. We aim to highlight how regime identification contributes to improving the discovery of causal structures from multivariate non-stationary time series data. Our experiments, encompassing both synthetic and real-world datasets, highlight the effectiveness of regime-wise time series causal analysis. We validate our approach by first demonstrating improved causal structure discovery using synthetic data where the ground truth causal relationships are known. Subsequently, we apply this methodology to climate-ecosystem dataset, showcasing its applicability in real-world scenarios.

Wasim Ahmad, Valentin Kasburg, Nina Kukowski, Maha Shadaydeh, Joachim Denzler:
Deep-Learning Based Causal Inference: A Feasibility Study Based on Three Years of Tectonic-Climate Data From Moxa Geodynamic Observatory.
Earth and Space Science.
11 (10) :
pp. e2023EA003430.
2024.
[bibtex]
[web]
[doi]
[abstract]
Highly sensitive laser strainmeters at Moxa Geodynamic Observatory (MGO) measure motions of the upper Earth's crust. Since the mountain overburden of the laser strainmeters installed in the gallery of the observatory is relatively low, the recorded time series are strongly influenced by local meteorological phenomena. To estimate the nonlinear effect of the meteorological variables on strain measurements in a non-stationary environment, advanced methods capable of learning the nonlinearity and discovering causal relationships in the non-stationary multivariate tectonic-climate time series are needed. Methods for causal inference generally perform well in identifying linear causal relationships but often struggle to retrieve complex nonlinear causal structures prevalent in real-world systems. This work presents a novel model invariance-based causal discovery (CDMI) method that utilizes deep networks to model nonlinearity in a multivariate time series system. We propose to use the theoretically well-established Knockoffs framework to generate in-distribution, uncorrelated copies of the original data as interventional variables and test the model invariance for causal discovery. To deal with the non-stationary behavior of the tectonic-climate time series recorded at the MGO, we propose a regime identification approach that we apply before causal analysis to generate segments of time series that possess locally consistent statistical properties. First, we evaluate our method on synthetically generated time series by comparing it to other causal analysis methods. We then investigate the hypothesized effect of meteorological variables on strain measurements. Our approach outperforms other causality methods and provides meaningful insights into tectonic-climate causal interactions.

Dimitri Korsch, Maha Shadaydeh, Joachim Denzler:
Simplified Concrete Dropout - Improving the Generation of Attribution Masks for Fine-grained Classification.
DAGM German Conference on Pattern Recognition (DAGM-GCPR).
2023.
[bibtex]
[pdf]
[code]
[supplementary]
[abstract]
Fine-grained classification is a particular case of a classification problem, aiming to classify objects that share the visual appearance and can only be distinguished by subtle differences. Fine-grained classification models are often deployed to determine animal species or individuals in automated animal monitoring systems. Precise visual explanations of the model's decision are crucial to analyze systematic errors. Attention- or gradient-based methods are commonly used to identify regions in the image that contribute the most to the classification decision. These methods deliver either too coarse or too noisy explanations, unsuitable for identifying subtle visual differences reliably. However, perturbation-based methods can precisely identify pixels causally responsible for the classification result. Fill-in of the dropout (FIDO) algorithm is one of those methods. It utilizes the concrete dropout (CD) to sample a set of attribution masks and updates the sampling parameters based on the output of the classification model. A known problem of the algorithm is a high variance in the gradient estimates, which the authors have mitigated until now by mini-batch updates of the sampling parameters. This paper presents a solution to circumvent these computational instabilities by simplifying the CD sampling and reducing reliance on large mini-batch sizes. First, it allows estimating the parameters with smaller mini-batch sizes without losing the quality of the estimates but with a reduced computational effort. Furthermore, our solution produces finer and more coherent attribution masks. Finally, we use the resulting attribution masks to improve the classification performance of a trained model without additional fine-tuning of the model.
Felix Schneider, Sven Sickert, Phillip Brandes, Sophie Marshall, Joachim Denzler:
Hard is the Task, the Samples are Few: A German Chiasmus Dataset.
Language Technology Conference: Human Language Technologies as a Challenge for Computer Science and Linguistics (LTC).
Pages 255-260.
2023.
[bibtex]
[pdf]
[doi]
[code]
[abstract]
In this work we present a novel German language dataset for the detection of the stylistic device called chiasmus collected from German dramas. The dataset includes phrases labeled as chiasmi, antimetaboles, semantically unrelated inversions, and various edge cases. The dataset was created by collecting examples from the GerDraCor dataset. We test different approaches for chiasmus detection on the samples and report an average precision of 0.74 for the best method. Additionally, we give an overview about related approaches and the current state of the research on chiasmus detection.
Ferdinand Rewicki, Joachim Denzler, Julia Niebling:
Is It Worth It? Comparing Six Deep and Classical Methods for Unsupervised Anomaly Detection in Time Series.
Applied Sciences.
13 (3) :
2023.
[bibtex]
[web]
[doi]
[abstract]
Detecting anomalies in time series data is important in a variety of fields, including system monitoring, healthcare and cybersecurity. While the abundance of available methods makes it difficult to choose the most appropriate method for a given application, each method has its strengths in detecting certain types of anomalies. In this study, we compare six unsupervised anomaly detection methods of varying complexity to determine whether more complex methods generally perform better and if certain methods are better suited to certain types of anomalies. We evaluated the methods using the UCR anomaly archive, a recent benchmark dataset for anomaly detection. We analyzed the results on a dataset and anomaly-type level after adjusting the necessary hyperparameters for each method. Additionally, we assessed the ability of each method to incorporate prior knowledge about anomalies and examined the differences between point-wise and sequence-wise features. Our experiments show that classical machine learning methods generally outperform deep learning methods across a range of anomaly types.

Jan Blunk, Niklas Penzel, Paul Bodesheim, Joachim Denzler:
Beyond Debiasing: Actively Steering Feature Selection via Loss Regularization.
DAGM German Conference on Pattern Recognition (DAGM-GCPR).
Pages 394-408.
2023.
[bibtex]
[pdf]
[doi]
[abstract]
It is common for domain experts like physicians in medical studies to examine features for their reliability with respect to a specific domain task. When introducing machine learning, a common expectation is that machine learning models use the same features as human experts to solve a task but that is not always the case. Moreover, datasets often contain features that are known from domain knowledge to generalize badly to the real world, referred to as biases. Current debiasing methods only remove such influences. To additionally integrate the domain knowledge about well-established features into the training of a model, their relevance should be increased. We present a method that permits the manipulation of the relevance of features by actively steering the model's feature selection during the training process. That is, it allows both the discouragement of biases and encouragement of well-established features to incorporate domain knowledge about the feature reliability. We model our objectives for actively steering the feature selection process as a constrained optimization problem, which we implement via a loss regularization that is based on batch-wise feature attributions. We evaluate our approach on a novel synthetic regression dataset and a computer vision dataset. We observe that it successfully steers the features a model selects during the training process. This is a strong indicator that our method can be used to integrate domain knowledge about well-established features into a model.

Lena Mers, Oliver Mothes, Joachim Denzler, Orlando Guntinas-Lichius, Christian Dobel:
Der zeitliche Verlauf des emotionalen menschlichen Gesichtsausdruckes - die Entwicklung eines künstliche Intelligenz basierten Paradigmas zur Quantifizierung.
94. Jahresversammlung der Deutschen Gesellschaft für Hals-Nasen-Ohren-Heilkunde, Kopf- und Hals-Chirurgie e.V., Bonn.
2023.
[bibtex]
[web]
[doi]
[abstract]
Einleitung: Der emotionale Gesichtsausdruck (EG) ist essentiell für soziale Interaktionen und die Kommunikation. Dessen Dynamik ist interdisziplinär für die Evaluation von Erkrankungen vielversprechend, die Studienlage jedoch limitiert. Ziel war die Entwicklung eines Paradigmas zur Quantifizierung der Dynamik des EG und deren Mediation durch den Emotional-Contagion (EC)-Effekt. Methode: EGs von 5 Basisemotionen reaktiv auf explizite motorische Zielvorgaben wurden mit einem 3-D-Kamerasystem aufgezeichnet (N = 31) und durch maschinelles Lernen analysiert. Reaktionsbeginn (onset timestamp), maximale Intensität und deren Zeitpunkt (apex value, apex timestamp) wurden analysiert. Zur Exploration von EC wurden verschiedene Stimuli (Abbildungen von EGs und emotionalen Adjektiven) präsentiert: Die Hypothese war, dass die Imitation von EGs EC induzieren, die Prozesse sich mutuell verstärken würden und dies durch einen früheren onset- und apex timestamp sowie höheren apex value repräsentiert würde. Ergebnisse: Die Hypothese wurde für alle Parameter für Freude und Angst und den apex timestamp für überraschung bestätigt, bei dem apex value für Wut widerlegt. Dies deutet an, dass EC potentiell die Dynamik moduliert, dessen Induktion jedoch (sozio)kognitiven Kontrollprozessen unterliegt. Respektive scheinen die Verarbeitung von EGs durch semantisch-konzeptuelle verbale Informationen moduliert und linguistische und emotionale Reize potentiell interagierend prozessiert zu werden. Weitere Analysen zeigten im Widerspruch zu der Universalitätshypothese des EG inter- und intraindividuelle Varianzen der Mimik. Schlussfolgerung: Die Methodik bietet große Chancen in der Diagnostik und Therapie von Fazialisparesen verschiedener ätiologie und der postoperativen Nachsorge von Fazialisrekonstruktionen. Deutsche Forschungsgemeinschaft (GU-463/12-1)

Matthias Körschens, Solveig Franziska Bucher, Christine Römermann, Joachim Denzler:
Improving Data Efficiency for Plant Cover Prediction with Label Interpolation and Monte-Carlo Cropping.
DAGM German Conference on Pattern Recognition (DAGM-GCPR).
2023.
[bibtex]
[pdf]
[web]
[supplementary]
[abstract]
The plant community composition is an essential indicator of environmental changes and is, for this reason, usually analyzed in ecological field studies in terms of the so-called plant cover. The manual acquisition of this kind of data is time-consuming, laborious, and prone to human error. Automated camera systems can collect high-resolution images of the surveyed vegetation plots at a high frequency. In combination with subsequent algorithmic analysis, it is possible to objectively extract information on plant community composition quickly and with little human effort. An automated camera system can easily collect the large amounts of image data necessary to train a Deep Learning system for automatic analysis. However, due to the amount of work required to annotate vegetation images with plant cover data, only few labeled samples are available. As automated camera systems can collect many pictures without labels, we introduce an approach to interpolate the sparse labels in the collected vegetation plot time series down to the intermediate dense and unlabeled images to artificially increase our training dataset to seven times its original size. Moreover, we introduce a new method we call Monte-Carlo Cropping. This approach trains on a collection of cropped parts of the training images to deal with high-resolution images efficiently, implicitly augment the training images, and speed up training. We evaluate both approaches on a plant cover dataset containing images of herbaceous plant communities and find that our methods lead to improvements in the species, community, and segmentation metrics investigated.

Matthias Körschens, Solveig Franziska Bucher, Christine Römermann, Joachim Denzler:
Unified Automatic Plant Cover and Phenology Prediction.
ICCV Workshop on Computer Vision in Plant Phenotyping and Agriculture (CVPPA).
2023.
[bibtex]
[pdf]
[abstract]
The composition and phenology of plant communities are paramount indicators for environmental changes, especially climate change, and are, due to this, subject to many ecological studies. While species composition and phenology are usually monitored by ecologists directly in the field, this process is slow, laborious, and prone to human error. In contrast, automated camera systems with intelligent image analysis methods can provide fast analyses with a high temporal resolution and therefore are highly advantageous for ecological research. Nowadays, methods already exist that can analyze the plant community composition from images, and others that investigate the phenology of plants. However, there are no automatic approaches that analyze the plant community composition together with the phenology of the same community, which is why we aim to close this gap by combining an existing plant cover prediction method based on convolutional neural networks with a novel phenology prediction module. The module builds on the species- and pixel-wise occurrence probabilities generated during the plant cover prediction process, and by that, significantly improves the quality of phenology predictions compared to isolated training of plant cover and phenology. We evaluate our approach by comparing the time trends of the observed and predicted phenology values on the InsectArmageddon dataset comprising cover and phenology data of eight herbaceous plant species. We find that our method significantly outperforms two dataset-statistics-based prediction baselines as well as a naive baseline that does not integrate any information from the plant cover prediction module.

Niklas Penzel, Jana Kierdorf, Ribana Roscher, Joachim Denzler:
Analyzing the Behavior of Cauliflower Harvest-Readiness Models by Investigating Feature Relevances.
ICCV Workshop on Computer Vision in Plant Phenotyping and Agriculture (CVPPA).
Pages 572-581.
2023.
[bibtex]
[pdf]
[abstract]
The performance of a machine learning model is characterized by its ability to accurately represent the input-output relationship and its behavior on unseen data. A prerequisite for high performance is that causal relationships of features with the model outcome are correctly represented. This work analyses the causal relationships by investigating the relevance of features in machine learning models using conditional independence tests. For this, an attribution method based on Pearl's causality framework is employed.Our presented approach analyzes two data-driven models designed for the harvest-readiness prediction of cauliflower plants: one base model and one model where the decision process is adjusted based on local explanations. Additionally, we propose a visualization technique inspired by Partial Dependence Plots to gain further insights into the model behavior. The experiments presented in this paper find that both models learn task-relevant features during fine-tuning when compared to the ImageNet pre-trained weights. However, both models differ in their feature relevance, specifically in whether they utilize the image recording date. The experiments further show that our approach is able to reveal that the adjusted model is able to reduce the trends for the observed biases. Furthermore, the adjusted model maintains the desired behavior for the semantically meaningful feature of cauliflower head diameter, predicting higher harvest-readiness scores for higher feature realizations, which is consistent with existing domain knowledge. The proposed investigation approach can be applied to other domain-specific tasks to aid practitioners in evaluating model choices.

Niklas Penzel, Joachim Denzler:
Interpreting Art by Leveraging Pre-Trained Models.
International Conference on Machine Vision and Applications (MVA).
Pages 1-6.
2023.
[bibtex]
[doi]
[abstract]
In many domains, so-called foundation models were recently proposed. These models are trained on immense amounts of data resulting in impressive performances on various downstream tasks and benchmarks. Later works focus on leveraging this pre-trained knowledge by combining these models. To reduce data and compute requirements, we utilize and combine foundation models in two ways. First, we use language and vision models to extract and generate a challenging language vision task in the form of artwork interpretation pairs. Second, we combine and fine-tune CLIP as well as GPT-2 to reduce compute requirements for training interpretation models. We perform a qualitative and quantitative analysis of our data and conclude that generating artwork leads to improvements in visual-text alignment and, therefore, to more proficient interpretation models. Our approach addresses how to leverage and combine pre-trained models to tackle tasks where existing data is scarce or difficult to obtain.
Sai Karthikeya Vemuri, Joachim Denzler:
Gradient Statistics-Based Multi-Objective Optimization in Physics-Informed Neural Networks.
Sensors.
23 (21) :
2023.
[bibtex]
[pdf]
[web]
[doi]
[abstract]
Modeling and simulation of complex non-linear systems are essential in physics, engineering, and signal processing. Neural networks are widely regarded for such tasks due to their ability to learn complex representations from data. Training deep neural networks traditionally requires large amounts of data, which may not always be readily available for such systems. Contrarily, there is a large amount of domain knowledge in the form of mathematical models for the physics/behavior of such systems. A new class of neural networks called Physics-Informed Neural Networks (PINNs) has gained much attention recently as a paradigm for combining physics into neural networks. They have become a powerful tool for solving forward and inverse problems involving differential equations. A general framework of a PINN consists of a multi-layer perceptron that learns the solution of the partial differential equation (PDE) along with its boundary/initial conditions by minimizing a multi-objective loss function. This is formed by the sum of individual loss terms that penalize the output at different collocation points based on the differential equation and initial and boundary conditions. However, multiple loss terms arising from PDE residual and boundary conditions in PINNs pose a challenge in optimizing the overall loss function. This often leads to training failures and inaccurate results. We propose advanced gradient statistics-based weighting schemes for PINNs to address this challenge. These schemes utilize backpropagated gradient statistics of individual loss terms to appropriately scale and assign weights to each term, ensuring balanced training and meaningful solutions. In addition to the existing gradient statistics-based weighting schemes, we introduce kurtosis–standard deviation-based and combined mean and standard deviation-based schemes for approximating solutions of PDEs using PINNs. We provide a qualitative and quantitative comparison of these weighting schemes on 2D Poisson’s and Klein–Gordon’s equations, highlighting their effectiveness in improving PINN performance.

Sai Karthikeya Vemuri, Joachim Denzler:
Physics Informed Neural Networks for Aeroacoustic Source Estimation.
IACM Mechanistic Machine Learning and Digital Engineering for Computational Science Engineering and Technology.
2023.
[bibtex]
[web]
[doi]
[abstract]
Computational Aeroacoustics (CAA) is a critical domain within computational fluid dynamics (CFD) that focuses on understanding and predicting sound generation in aerodynamic systems. Accurate estimation of Lighthill sources, which play a pivotal role in deciphering acoustic phenomena, remains a challenging task, especially when confronted with noisy and missing flow data. This study explores the potential of Physics Informed Neural Networks (PINNs) to address these challenges and capture the complex flow dynamics inherent in CAA. The integration of PINNs in CFD has gained significant attention in recent years. PINNs blend deep learning techniques with fundamental physical principles, enabling accurate predictions and enhanced modeling capabilities. Their versatility has been demonstrated across various CFD applications, ranging from turbulence modeling to flow control optimization and mesh generation. However, their potential in the field of CAA, specifically in estimating Lighthill sources from flow data, remains largely unexplored. To investigate the effectiveness of PINNs in the context of CAA, we conduct a series of experiments using high-fidelity flow data obtained from common flow configurations, such as flow around a cylinder. Leveraging this data, we create three distinct datasets that represent different data imperfections. The first dataset involves the deliberate removal of certain data points, the second dataset incorporates the addition of random noise, and the third dataset combines both missing data and noise. By incorporating the governing Navier-Stokes equations, we train the PINNs using these three datasets. The PINNs, with their inherent capability to capture complex flow patterns, are employed to estimate the aeroacoustic source map. The predicted map obtained from the PINNs is then rigorously compared to the ground truth source map derived from the high-fidelity data. Through these experiments, we demonstrate the remarkable ability of PINNs to effectively estimate the aeroacoustic source map in the presence of noisy and missing data. This validation establishes the potential of PINNs as a powerful tool for aeroacoustic analysis and source characterization. The successful application of PINNs in this study opens up new ways for further advancements in aeroacoustics. By leveraging PINNs we can enhance noise reduction techniques, optimize design processes, and improve the overall efficiency of aerodynamic systems. In conclusion, this research showcases the potential of Physics Informed Neural Networks for accurate aeroacoustic source estimation in scenarios where data quality is compromised. These findings contribute to the growing body of knowledge in aeroacoustics and offer a pathway toward more robust and efficient analysis techniques in the field.

Tim Büchner, Orlando Guntinas-Lichius, Joachim Denzler:
Improved Obstructed Facial Feature Reconstruction for Emotion Recognition with Minimal Change CycleGANs.
Advanced Concepts for Intelligent Vision Systems (Acivs).
Pages 262-274.
2023.
Best Paper Award
[bibtex]
[pdf]
[web]
[doi]
[abstract]
Comprehending facial expressions is essential for human interaction and closely linked to facial muscle understanding. Typically, muscle activation measurement involves electromyography (EMG) surface electrodes on the face. Consequently, facial regions are obscured by electrodes, posing challenges for computer vision algorithms to assess facial expressions. Conventional methods are unable to assess facial expressions with occluded features due to lack of training on such data. We demonstrate that a CycleGAN-based approach can restore occluded facial features without fine-tuning models and algorithms. By introducing the minimal change regularization term to the optimization problem for CycleGANs, we enhanced existing methods, reducing hallucinated facial features. We reached a correct emotion classification rate up to 90\% for individual subjects. Furthermore, we overcome individual model limitations by training a single model for multiple individuals. This allows for the integration of EMG-based expression recognition with existing computer vision algorithms, enriching facial understanding and potentially improving the connection between muscle activity and expressions.

Tim Büchner, Sven Sickert, Gerd F. Volk, Christoph Anders, Orlando Guntinas-Lichius, Joachim Denzler:
Let’s Get the FACS Straight - Reconstructing Obstructed Facial Features.
International Conference on Computer Vision Theory and Applications (VISAPP).
Pages 727-736.
2023.
[bibtex]
[pdf]
[web]
[doi]
[abstract]
The human face is one of the most crucial parts in interhuman communication. Even when parts of the face are hidden or obstructed the underlying facial movements can be understood. Machine learning approaches often fail in that regard due to the complexity of the facial structures. To alleviate this problem a common approach is to fine-tune a model for such a specific application. However, this is computational intensive and might have to be repeated for each desired analysis task. In this paper, we propose to reconstruct obstructed facial parts to avoid the task of repeated fine-tuning. As a result, existing facial analysis methods can be used without further changes with respect to the data. In our approach, the restoration of facial features is interpreted as a style transfer task between different recording setups. By using the CycleGAN architecture the requirement of matched pairs, which is often hard to fullfill, can be eliminated. To proof the viability of our approach, we compare our reconstructions with real unobstructed recordings. We created a novel data set in which 36 test subjects were recorded both with and without 62 surface electromyography sensors attached to their faces. In our evaluation, we feature typical facial analysis tasks, like the computation of Facial Action Units and the detection of emotions. To further assess the quality of the restoration, we also compare perceptional distances. We can show, that scores similar to the videos without obstructing sensors can be achieved.

Tim Büchner, Sven Sickert, Gerd F. Volk, Orlando Guntinas-Lichius, Joachim Denzler:
From Faces To Volumes - Measuring Volumetric Asymmetry in 3D Facial Palsy Scans.
International Symposium on Visual Computing (ISVC).
Pages 121-132.
2023.
Best Paper Award
[bibtex]
[pdf]
[web]
[doi]
[abstract]
The research of facial palsy, a unilateral palsy of the facial nerve, is a complex field of study with many different causes and symptoms. Even modern approaches to evaluate the facial palsy state rely mainly on stills and 2D videos of the face and rarely on 3D information. Many of these analysis and visualization methods require manual intervention, which is time-consuming and error-prone. Moreover, existing approaches depend on alignment algorithms or Euclidean measurements and consider only static facial expressions. Volumetric changes by muscle movement are essential for facial palsy analysis but require manual extraction. Our proposed method extracts a heuristic unilateral volumetric description for dynamic expressions from 3D scans. Accurate positioning of 3D landmarks, problematic for facial palsy, is automated by adapting existing methods. Additionally, we visualize the primary areas of volumetric disparity by projecting them onto the face. Our approach substantially minimizes human intervention simplifying the clinical routine and interaction with 3D scans. The proposed pipeline can potentially more effectively analyze and monitor patient treatment progress.

Tim Büchner, Sven Sickert, Roland Graßme, Christoph Anders, Orlando Guntinas-Lichius, Joachim Denzler:
Using 2D and 3D Face Representations to Generate Comprehensive Facial Electromyography Intensity Maps.
International Symposium on Visual Computing (ISVC).
Pages 136-147.
2023.
[bibtex]
[pdf]
[web]
[doi]
[code]
[abstract]
Electromyography (EMG) is a method to measure muscle activity. Physicians also use EMG to study the function of facial muscles through intensity maps (IMs) to support diagnostics and research. However, many existing visualizations neglect proper anatomical structures and disregard the physical properties of EMG signals. Especially the variance of facial structures between people complicates the generalization of IMs, which is crucial for their correct interpretation. In our work, we overcome these issues by introducing a pipeline to generate anatomically correct IMs for facial muscles. An IM generation algorithm is proposed based on a template model incorporating custom surface EMG schemes and combining them with a projection method to highlight the IMs on the patient's face in 2D and 3D. We evaluate the generated and projected IMs based on their correct projection quality for six base emotions on several subjects. These visualizations deepen the understanding of muscle activity areas and indicate that a holistic view of the face could be necessary to understand facial muscle activity. Medical experts can use our approach to study the function of facial muscles and to support diagnostics and therapy.
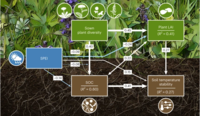
Yuanyuan Huang, Gideon Stein, Olaf Kolle, Karl Kuebler, Ernst-Detlef Schulze, Hui Dong, David Eichenberg, Gerd Gleixner, Anke Hildebrandt, Markus Lange, Christiane Roscher, Holger Schielzeth, Bernhard Schmid, Alexandra Weigelt, Wolfgang W. Weisser, Maha Shadaydeh, Joachim Denzler, Anne Ebeling, Nico Eisenhauer:
Enhanced Stability of Grassland Soil Temperature by Plant Diversity.
Nature Geoscience.
pp. 1-7.
2023.
[bibtex]
[doi]
[abstract]
Extreme weather events are occurring more frequently, and research has shown that plant diversity can help mitigate the impacts of climate change by increasing plant productivity and ecosystem stability. Although soil temperature and its stability are key determinants of essential ecosystem processes, no study has yet investigated whether plant diversity buffers soil temperature fluctuations over long-term community development. Here we have conducted a comprehensive analysis of a continuous 18-year dataset from a grassland biodiversity experiment with high spatial and temporal resolutions. Our findings reveal that plant diversity acts as a natural buffer, preventing soil heating in hot weather and cooling in cold weather. This diversity effect persists year-round, intensifying with the aging of experimental communities and being even stronger under extreme climate conditions, such as hot days or dry years. Using structural equation modelling, we found that plant diversity stabilizes soil temperature by increasing soil organic carbon concentrations and, to a lesser extent, plant leaf area index. Our results suggest that, in lowland grasslands, the diversity-induced stabilization of soil temperature may help to mitigate the negative effects of extreme climatic events such as soil carbon decomposition, thus slowing global warming.

Björn Barz, Joachim Denzler:
Weakly-Supervised Localization of Multiple Objects in Images using Cosine Loss.
International Conference on Computer Vision Theory and Applications (VISAPP).
Pages 287-296.
2022.
[bibtex]
[doi]
[abstract]
Can we learn to localize objects in images from just image-level class labels? Previous research has shown that this ability can be added to convolutional neural networks (CNNs) trained for image classification post hoc without additional cost or effort using so-called class activation maps (CAMs). However, while CAMs can localize a particular known class in the image quite accurately, they cannot detect and localize instances of multiple different classes in a single image. This limitation is a consequence of the missing comparability of prediction scores between classes, which results from training with the cross-entropy loss after a softmax activation. We find that CNNs trained with the cosine loss instead of cross-entropy do not exhibit this limitation and propose a variation of CAMs termed Dense Class Maps (DCMs) that fuse predictions for multiple classes into a coarse semantic segmentation of the scene. Even though the network has only been trained for single-label classification at the image level, DCMs allow for detecting the presence of multiple objects in an image and locating them. Our approach outperforms CAMs on the MS COCO object detection dataset by a relative increase of 27% in mean average precision.

Christoph Theiß, Joachim Denzler:
Towards a Unified Benchmark for Monocular Radial Distortion Correction and the Importance of Testing on Real World Data.
International Conference on Pattern Recognition and Artificial Intelligence (ICPRAI).
Pages 59-71.
2022.
[bibtex]
[web]
[doi]
[abstract]
Radial distortion correction for a single image is an often overlooked problem in computer vision. It is possible to rectify images accurately when the camera and lens are known or physically available to take additional images with a calibration pattern. However, some- times it is impossible to identify the type of camera or lens of an image, e.g. crowd-sourced datasets. Nonetheless, it is still important to cor- rect that image for radial distortion in these cases. Especially in the last few years, solving the radial distortion correction problem from a single image with a deep neural network approach increased in popular- ity. This paper shows that these approaches tend to overfit completely on the synthetic data generation process used to train such networks. Additionally, we investigate which parts of this process are responsi- ble for overfitting, and apply an explainability tool to further investi- gate the behavior of the trained models. Furthermore, we introduce a new dataset based on the popular ImageNet dataset as a new bench- mark for comparison. Lastly, we propose a efficient solution to the over- fitting problem by feeding edge images to the neural networks instead of the images. Source code, data, and models are publicly available at https://github.com/cvjena/deeprect.

Clemence Dubois, Jannik Jänichen, Maha Shadaydeh, Gideon Stein, Alexandra Katz, Daniel Klöpper, Joachim Denzler, Christiane Schmullius, Katja Last:
KI4KI: Neues Projekt zur regelmässigen Überwachung von Stauanlagen aus dem All.
Messtechnische Überwachung von Stauanlagen ; XII.Mittweidaer Talsperrentag.
Pages 15-19.
2022.
[bibtex]
[web]
[doi]
[abstract]
Die Überwachung von Staubauwerken stellt Stauanlagenbetreiber vor viele Herausforderungen. Insbesondere aufgrund der Kosten und des Zeitaufwandes werden Staubauwerke oft nur ein- bis zweimal im Jahr durch trigonometrische Messungen überwacht. Seit einigen Jahrzehnten liefern jedoch Radarsatellitendaten nützliche Informationen zum Infrastrukturmonitoring. Satellitendaten der Copernicus Sentinel-1 Mission erlauben es, mittels der Technik der Persistent Scatterer Interferometrie (PSI), Deformationsmessungen von Staubauwerken im Millimeterbereich mit einem zeitlichen Abstand von 6 bis 12 Tagen durchzuführen. In einem Verbundprojekt zwischen der Friedrich-Schiller-Universität Jena und dem Ruhrverband soll ein Dienst entwickelt werden, der bisherige Überwachungsstrategien der Anlagen durch Nutzung der PSI Technik verbessert. Zudem sollen neuartige Geräte genutzt werden, die die Sichtbarkeit der Stauanlagen im Satellitenbild erhöhen sowie Methoden der künstlichen Intelligenz genutzt werden, um Deformationen im Falle von Extremwetterereignissen besser vorhersagen zu können.

Dimitri Korsch, Paul Bodesheim, Gunnar Brehm, Joachim Denzler:
Automated Visual Monitoring of Nocturnal Insects with Light-based Camera Traps.
CVPR Workshop on Fine-grained Visual Classification (CVPR-WS).
2022.
[bibtex]
[pdf]
[web]
[code]
[abstract]
Automatic camera-assisted monitoring of insects for abundance estimations is crucial to understand and counteract ongoing insect decline. In this paper, we present two datasets of nocturnal insects, especially moths as a subset of Lepidoptera, photographed in Central Europe. One of the datasets, the EU-Moths dataset, was captured manually by citizen scientists and contains species annotations for 200 different species and bounding box annotations for those. We used this dataset to develop and evaluate a two-stage pipeline for insect detection and moth species classification in previous work. We further introduce a prototype for an automated visual monitoring system. This prototype produced the second dataset consisting of more than 27000 images captured on 95 nights. For evaluation and bootstrapping purposes, we annotated a subset of the images with bounding boxes enframing nocturnal insects. Finally, we present first detection and classification baselines for these datasets and encourage other scientists to use this publicly available data.

Emanuel Andrada, Oliver Mothes, Heiko Stark, Matthew C. Tresch, Joachim Denzler, Martin S. Fischer, Reinhard Blickhan:
Limb, Joint and Pelvic Kinematic Control in the Quail Coping with Steps Upwards and Downwards.
Scientific Reports.
12 (1) :
pp. 15901.
2022.
[bibtex]
[pdf]
[web]
[doi]
[abstract]
Small cursorial birds display remarkable walking skills and can negotiate complex and unstructured terrains with ease. The neuromechanical control strategies necessary to adapt to these challenging terrains are still not well understood. Here, we analyzed the 2D- and 3D pelvic and leg kinematic strategies employed by the common quail to negotiate visible steps (upwards and downwards) of about 10\%, and 50\% of their leg length. We used biplanar fluoroscopy to accurately describe joint positions in three dimensions and performed semi-automatic landmark localization using deep learning. Quails negotiated the vertical obstacles without major problems and rapidly regained steady-state locomotion. When coping with step upwards, the quail mostly adapted the trailing limb to permit the leading leg to step on the elevated substrate similarly as it did during level locomotion. When negotiated steps downwards, both legs showed significant adaptations. For those small and moderate step heights that did not induce aerial running, the quail kept the kinematic pattern of the distal joints largely unchanged during uneven locomotion, and most changes occurred in proximal joints. The hip regulated leg length, while the distal joints maintained the spring-damped limb patterns. However, to negotiate the largest visible steps, more dramatic kinematic alterations were observed. There all joints contributed to leg lengthening/shortening in the trailing leg, and both the trailing and leading legs stepped more vertically and less abducted. In addition, locomotion speed was decreased. We hypothesize a shift from a dynamic walking program to more goal-directed motions that might be focused on maximizing safety.

Gabriel Meincke, Johannes Krauß, Maren Geitner, Dirk Arnold, Anna-Maria Kuttenreich, Valeria Mastryukova, Jan Beckmann, Wengelawit Misikire, Tim Büchner, Joachim Denzler, Orlando Guntinas-Lichius, Gerd F. Volk:
Surface Electrostimulation Prevents Denervated Muscle Atrophy in Facial Paralysis: Ultrasound Quantification [Abstract].
Abstracts of the 2022 Joint Annual Conference of the Austrian (ÖGBMT), German (VDE DGBMT) and Swiss (SSBE) Societies for Biomedical Engineering, including the 14th Vienna International Workshop on Functional Electrical Stimulation.
67 (s1) :
pp. 542.
2022.
[bibtex]
[doi]
[abstract]
Sparse evidence of the potentialities of surface stimulation (ES) for preventing muscle atrophy in patients with acute or chronic facial palsy have been published so far. Especially studies addressing objective imaging methods for paralysis quantification are currently required. Facial muscles as principal target of ES can be directly quantified via ultrasound, a swiftly feasible imaging method. Our study represents one of the few systematic evaluations of this approach within patients with complete unilateral facial paralysis. Methods A well-established ultrasound protocol for the quantification of area and grey levels was used to evaluate therapeutical effects on patients with facial paralysis using ES. Only patients with complete facial paralysis confirmed by needleelectromyography were included. Individual ES parameters were set during the first visit and confirmed/adapted every month thereafter. At each visit patients additionally underwent facial needle-electromyography to rule out reinnervation as well as ultrasound imaging of 7 facial and 2 chewing muscles. Results In total 15 patients were recruited (medium 53 years, min. 25, max. 78; 8 female, 7 male). They underwent ES for a maximum of 1 year without serious adverse events. All patients were able to follow the ES protocol. First results in the assessment of ultrasound imaging already indicate that electrically stimulated paralytic muscles do not experience any further cross-sectional area decrease in comparison to the contralateral side. Non-stimulated muscles do not provide significant changes. Similar effects on grey levels currently remain to be assessed to draw further conclusions. Conclusion ES is supposed to decelerate the process of atrophy of facial muscles in patients with complete facial paralysis. Thus, the muscular cross-sectional area does not seem to aggravate during the period of electrostimulation within sonographic assessment. This demonstrates the benefit of ES regarding the facial muscle atrophy in patients with complete facial paralysis.

J. Wolfgang Wägele, Paul Bodesheim, Sarah J. Bourlat, Joachim Denzler, Michael Diepenbroek, Vera Fonseca, Karl-Heinz Frommolt, Matthias F. Geiger, Birgit Gemeinholzer, Frank Oliver Glöckner, Timm Haucke, Ameli Kirse, Alexander Kölpin, Ivaylo Kostadinov, Hjalmar S. Kühl, Frank Kurth, Mario Lasseck, Sascha Liedke, Florian Losch, Sandra Müller, Natalia Petrovskaya, Krzysztof Piotrowski, Bernd Radig, Christoph Scherber, Lukas Schoppmann, Jan Schulz, Volker Steinhage, Georg F. Tschan, Wolfgang Vautz, Domenico Velotto, Maximilian Weigend, Stefan Wildermann:
Towards a multisensor station for automated biodiversity monitoring.
Basic and Applied Ecology.
59 :
pp. 105-138.
2022.
[bibtex]
[pdf]
[web]
[doi]
[abstract]
Rapid changes of the biosphere observed in recent years are caused by both small and large scale drivers, like shifts in temperature, transformations in land-use, or changes in the energy budget of systems. While the latter processes are easily quantifiable, documentation of the loss of biodiversity and community structure is more difficult. Changes in organismal abundance and diversity are barely documented. Censuses of species are usually fragmentary and inferred by often spatially, temporally and ecologically unsatisfactory simple species lists for individual study sites. Thus, detrimental global processes and their drivers often remain unrevealed. A major impediment to monitoring species diversity is the lack of human taxonomic expertise that is implicitly required for large-scale and fine-grained assessments. Another is the large amount of personnel and associated costs needed to cover large scales, or the inaccessibility of remote but nonetheless affected areas. To overcome these limitations we propose a network of Automated Multisensor stations for Monitoring of species Diversity (AMMODs) to pave the way for a new generation of biodiversity assessment centers. This network combines cutting-edge technologies with biodiversity informatics and expert systems that conserve expert knowledge. Each AMMOD station combines autonomous samplers for insects, pollen and spores, audio recorders for vocalizing animals, sensors for volatile organic compounds emitted by plants (pVOCs) and camera traps for mammals and small invertebrates. AMMODs are largely self-containing and have the ability to pre-process data (e.g. for noise filtering) prior to transmission to receiver stations for storage, integration and analyses. Installation on sites that are difficult to access require a sophisticated and challenging system design with optimum balance between power requirements, bandwidth for data transmission, required service, and operation under all environmental conditions for years. An important prerequisite for automated species identification are databases of DNA barcodes, animal sounds, for pVOCs, and images used as training data for automated species identification. AMMOD stations thus become a key component to advance the field of biodiversity monitoring for research and policy by delivering biodiversity data at an unprecedented spatial and temporal resolution.

Johannes Krauß, Gabriel Meincke, Maren Geitner, Dirk Arnold, Anna-Maria Kuttenreich, Valeria Mastryukova, Jan Beckmann, Wengelawit Misikire, Tim Büchner, Joachim Denzler, Orlando Guntinas-Lichius, Gerd F. Volk:
Optical Quantification of Surface Electrical Stimulation to Prevent Denervation Muscle Atrophy in 15 Patients with Facial Paralysis [Abstract].
Abstracts of the 2022 Joint Annual Conference of the Austrian (ÖGBMT), German (VDE DGBMT) and Swiss (SSBE) Societies for Biomedical Engineering, including the 14th Vienna International Workshop on Functional Electrical Stimulation.
67 (s1) :
pp. 541.
2022.
[bibtex]
[doi]
[abstract]
Few studies showing therapeutic potentials of electrical stimulation (ES) of the facial surface in patients with facial palsy have been published so far. Not only muscular atrophy of the facial muscles but facial disfigurement represents the main issue for patient well-being. Therefore, objective methods are required to detect ES effects on facial symmetry within patients with complete unilateral facial paralysis. Methods Only patients with one-sided peripheral complete facial paralysis confirmed by needle-EMG were included and underwent ES twice a day for 20 min until the event of reinnervation or for a maximum of 1 year. ES-parameters were set during the first visit and confirmed/adapted every month thereafter. At each visit, patients underwent needle-electromyography, 2D-fotographic documentation and 3D-videos. Whereas 2D-images allow Euclidean measurements of facial symmetry, 3D-images permit detection of metrical divergence within both sides of face. Using the 2D and 3D-fotographic documentation, we aim to prove that ES is able to prevent muscular atrophy in patients with facial paralysis. Results In total 15 patients were recruited (medium 53 years, min. 25, max. 78; 8 female, 7 male). They underwent ES for a maximum of one year without serious adverse events. All patients were able to follow the ES protocol. On a short term, we could detect positive effects of ES on the extent of asymmetry of mouth corners. Preliminary results show positive effects leading to improvement of symmetry of denervated faces. Conclusion A positive short-term effect of ES on facial symmetry in patients with total paralysis could be shown. The improvement of optical appearance during ES has a positive effect on patients' satisfaction and resembles a promising, easily accessible marker for facial muscles in facial paralysis patients. Improving facial symmetry by ES might also be linked to preventing facial muscle atrophy. Acknowledgements Sponsored by DFG GU-463/12-1 and IZKF

Lorenzo Brigato, Björn Barz, Luca Iocchi, Joachim Denzler:
Image Classification with Small Datasets: Overview and Benchmark.
IEEE Access.
10 :
pp. 49233-49250.
2022.
[bibtex]
[pdf]
[web]
[doi]
[abstract]
Image classification with small datasets has been an active research area in the recent past. However, as research in this scope is still in its infancy, two key ingredients are missing for ensuring reliable and truthful progress: a systematic and extensive overview of the state of the art, and a common benchmark to allow for objective comparisons between published methods. This article addresses both issues. First, we systematically organize and connect past studies to consolidate a community that is currently fragmented and scattered. Second, we propose a common benchmark that allows for an objective comparison of approaches. It consists of five datasets spanning various domains (e.g., natural images, medical imagery, satellite data) and data types (RGB, grayscale, multispectral). We use this benchmark to re-evaluate the standard cross-entropy baseline and ten existing methods published between 2017 and 2021 at renowned venues. Surprisingly, we find that thorough hyper-parameter tuning on held-out validation data results in a highly competitive baseline and highlights a stunted growth of performance over the years. Indeed, only a single specialized method dating back to 2019 clearly wins our benchmark and outperforms the baseline classifier.

Maha Shadaydeh, Joachim Denzler, Mirco Migliavacca:
Partitioning of Net Ecosystem Exchange Using Dynamic Mode Decomposition and Time Delay Embedding.
Engineering Proceedings.
18 (1) :
2022.
[bibtex]
[web]
[doi]
[abstract]
Ecosystem respiration (Reco) represents a major component of the global carbon cycle. An accurate estimation of Reco dynamics is necessary for a better understanding of ecosystem-climate interactions and the impact of climate extremes on ecosystems. This paper proposes a new data-driven method for the estimation of the nonlinear dynamics of Reco using the method of dynamic mode decomposition with control input (DMDc). The method is validated on the half-hourly Fluxnet 2015 data. The model is first trained on the night-time net ecosystem exchange data. The day-time Reco values are then predicted using the obtained model with future values of a control input such as air temperature and soil water content. To deal with unobserved drivers of Reco other than the user control input, the method uses time-delay embedding of the history of Reco and the control input. Results indicate that, on the one hand, the prediction accuracy of Reco dynamics using DMDc is comparable to state-of-the-art deep learning-based methods, yet it has the advantages of being a simple and almost hyper-parameter-free method with a low computational load. On the other hand, the study of the impact of different control inputs on Reco dynamics showed that for most of the studied Fluxnet sites, air temperature is a better long-term predictor of Reco, while using soil water content as control input produced better short-term prediction accuracy.

Matthias Körschens, Paul Bodesheim, Joachim Denzler:
Beyond Global Average Pooling: Alternative Feature Aggregations for Weakly Supervised Localization.
International Conference on Computer Vision Theory and Applications (VISAPP).
Pages 180-191.
2022.
[bibtex]
[pdf]
[doi]
[abstract]
Weakly supervised object localization (WSOL) enables the detection and segmentation of objects in applications where localization annotations are hard or too expensive to obtain. Nowadays, most relevant WSOL approaches are based on class activation mapping (CAM), where a classification network utilizing global average pooling is trained for object classification. The classification layer that follows the pooling layer is then repurposed to generate segmentations using the unpooled features. The resulting localizations are usually imprecise and primarily focused around the most discriminative areas of the object, making a correct indication of the object location difficult. We argue that this problem is inherent in training with global average pooling due to its averaging operation. Therefore, we investigate two alternative pooling strategies: global max pooling and global log-sum-exp pooling. Furthermore, to increase the crispness and resolution of localization maps, we also investigate the application of Feature Pyramid Networks, which are commonplace in object detection. We confirm the usefulness of both alternative pooling methods as well as the Feature Pyramid Network on the CUB-200-2011 and OpenImages datasets.

Matthias Körschens, Paul Bodesheim, Joachim Denzler:
Occlusion-Robustness of Convolutional Neural Networks via Inverted Cutout.
International Conference on Pattern Recognition (ICPR).
Pages 2829-2835.
2022.
[bibtex]
[pdf]
[doi]
[supplementary]
[abstract]
Convolutional Neural Networks (CNNs) are able to reliably classify objects in images if they are clearly visible and only slightly affected by small occlusions. However, heavy occlusions can strongly deteriorate the performance of CNNs, which is critical for tasks where correct identification is paramount. For many real-world applications, images are taken in unconstrained environments under suboptimal conditions, where occluded objects are inevitable. We propose a novel data augmentation method called Inverted Cutout, which can be used for training a CNN by showing only small patches of the images. Together with this augmentation method, we present several ways of making the network robust against occlusion. On the one hand, we utilize a spatial aggregation module without modifying the base network and on the other hand, we achieve occlusion-robustness with appropriate fine-tuning in conjunction with Inverted Cutout. In our experiments, we compare two different aggregation modules and two loss functions on the Occluded-Vehicles and Occluded-COCO-Vehicles datasets, showing that our approach outperforms existing state-of-the-art methods for object categorization under varying levels of occlusion.

Niklas Penzel, Christian Reimers, Paul Bodesheim, Joachim Denzler:
Investigating Neural Network Training on a Feature Level using Conditional Independence.
ECCV Workshop on Causality in Vision (ECCV-WS).
Pages 383-399.
2022.
[bibtex]
[pdf]
[doi]
[abstract]
There are still open questions about how the learned representations of deep models change during the training process. Understanding this process could aid in validating the training. Towards this goal, previous works analyze the training in the mutual information plane. We use a different approach and base our analysis on a method built on Reichenbach’s common cause principle. Using this method, we test whether the model utilizes information contained in human-defined features. Given such a set of features, we investigate how the relative feature usage changes throughout the training process. We analyze mul- tiple networks training on different tasks, including melanoma classifica- tion as a real-world application. We find that over the training, models concentrate on features containing information relevant to the task. This concentration is a form of representation compression. Crucially, we also find that the selected features can differ between training from-scratch and finetuning a pre-trained network.

Paul Bodesheim, Jan Blunk, Matthias Körschens, Clemens-Alexander Brust, Christoph Käding, Joachim Denzler:
Pre-trained models are not enough: active and lifelong learning is important for long-term visual monitoring of mammals in biodiversity research. Individual identification and attribute prediction with image features from deep neural networks and decoupled decision models applied to elephants and great apes.
Mammalian Biology.
102 :
pp. 875-897.
2022.
[bibtex]
[pdf]
[web]
[doi]
[abstract]
Animal re-identification based on image data, either recorded manually by photographers or automatically with camera traps, is an important task for ecological studies about biodiversity and conservation that can be highly automatized with algorithms from computer vision and machine learning. However, fixed identification models only trained with standard datasets before their application will quickly reach their limits, especially for long-term monitoring with changing environmental conditions, varying visual appearances of individuals over time that differ a lot from those in the training data, and new occurring individuals that have not been observed before. Hence, we believe that active learning with human-in-the-loop and continuous lifelong learning is important to tackle these challenges and to obtain high-performance recognition systems when dealing with huge amounts of additional data that become available during the application. Our general approach with image features from deep neural networks and decoupled decision models can be applied to many different mammalian species and is perfectly suited for continuous improvements of the recognition systems via lifelong learning. In our identification experiments, we consider four different taxa, namely two elephant species: African forest elephants and Asian elephants, as well as two species of great apes: gorillas and chimpanzees. Going beyond classical re-identification, our decoupled approach can also be used for predicting attributes of individuals such as gender or age using classification or regression methods. Although applicable for small datasets of individuals as well, we argue that even better recognition performance will be achieved by improving decision models gradually via lifelong learning to exploit huge datasets and continuous recordings from long-term applications. We highlight that algorithms for deploying lifelong learning in real observational studies exist and are ready for use. Hence, lifelong learning might become a valuable concept that supports practitioners when analyzing large-scale image data during long-term monitoring of mammals.

Sven Festag, Gideon Stein, Tim Büchner, Maha Shadaydeh, Joachim Denzler, Cord Spreckelsen:
Outcome Prediction and Murmur Detection in Sets of Phonocardiograms by a Deep Learning-Based Ensemble Approach.
Computing in Cardiology (CinC).
Pages 1-4.
2022.
[bibtex]
[pdf]
[doi]
[abstract]
We, the team UKJ_FSU, propose a deep learning system for the prediction of congenital heart diseases. Our method is able to predict the clinical outcomes (normal, abnormal) of patients as well as to identify heart murmur (present, absent, unclear) based on phonocardiograms recorded at different auscultation locations. The system we propose is an ensemble of four temporal convolutional networks with identical topologies, each specialized in identifying murmurs and predicting patient outcome from a phonocardiogram taken at one specific auscultation location. Their intermediate outputs are augmented by the manually ascertained patient features such as age group, sex, height, and weight. The outputs of the four networks are combined to form a single final decision as demanded by the rules of the George B. Moody PhysioNet Challenge 2022. On the first task of this challenge, the murmur detection, our model reached a weighted accuracy of 0.567 with respect to the validation set. On the outcome prediction task (second task) the ensemble led to a mean outcome cost of 10679 on the same set. By focusing on the clinical outcome prediction and tuning some of the hyper-parameters only for this task, our model reached a cost score of 12373 on the official test set (rank 13 of 39). The same model scored a weighted accuracy of 0.458 regarding the murmur detection on the test set (rank 37 of 40).
Tim Büchner, Sven Sickert, Gerd F. Volk, Orlando Guntinas-Lichius, Joachim Denzler:
Automatic Objective Severity Grading of Peripheral Facial Palsy Using 3D Radial Curves Extracted from Point Clouds.
Challenges of Trustable AI and Added-Value on Health.
Pages 179-183.
2022.
[bibtex]
[pdf]
[web]
[doi]
[code]
[abstract]
Peripheral facial palsy is an illness in which a one-sided ipsilateral paralysis of the facial muscles occurs due to nerve damage. Medical experts utilize visual severity grading methods to estimate this damage. Our algorithm-based method provides an objective grading using 3D point clouds. We extract from static 3D recordings facial radial curves to measure volumetric differences between both sides of the face. We analyze five patients with chronic complete peripheral facial palsy to evaluate our method by comparing changes over several recording sessions. We show that our proposed method allows an objective assessment of facial palsy.

Violeta Teodora Trifunov, Maha Shadaydeh, Joachim Denzler:
Sequential Causal Effect Variational Autoencoder: Time Series Causal Link Estimation under Hidden Confounding.
arXiv preprint arXiv:2209.11497.
2022.
[bibtex]
[web]
[doi]
[abstract]
Estimating causal effects from observational data in the presence of latent variables sometimes leads to spurious relationships which can be misconceived as causal. This is an important issue in many fields such as finance and climate science. We propose Sequential Causal Effect Variational Autoencoder (SCEVAE), a novel method for time series causality analysis under hidden confounding. It is based on the CEVAE framework and recurrent neural networks. The causal link's intensity of the confounded variables is calculated by using direct causal criteria based on Pearl's do-calculus. We show the efficacy of SCEVAE by applying it to synthetic datasets with both linear and nonlinear causal links. Furthermore, we apply our method to real aerosol-cloud-climate observation data. We compare our approach to a time series deconfounding method with and without substitute confounders on the synthetic data. We demonstrate that our method performs better by comparing both methods to the ground truth. In the case of real data, we use the expert knowledge of causal links and show how the use of correct proxy variables aids data reconstruction.

Violeta Teodora Trifunov, Maha Shadaydeh, Joachim Denzler:
Time Series Causal Link Estimation under Hidden Confounding using Knockoff Interventions.
NeurIPS Workshop on A Causal View on Dynamical Systems (NeurIPS-WS).
2022.
[bibtex]
[pdf]
[web]
[abstract]
Latent variables often mask cause-effect relationships in observational data which provokes spurious links that may be misinterpreted as causal. This problem sparks great interest in the fields such as climate science and economics. We propose to estimate confounded causal links of time series using Sequential Causal Effect Variational Autoencoder (SCEVAE) while applying knockoff interventions. We show the advantage of knockoff interventions by applying SCEVAE to synthetic datasets with both linear and nonlinear causal links. Moreover, we apply SCEVAE with knockoffs to real aerosol-cloud-climate observational time series data. We compare our results on synthetic data to those of a time series deconfounding method both with and without estimated confounders. We show that our method outperforms this benchmark by comparing both methods to the ground truth. For the real data analysis, we rely on expert knowledge of causal links and demonstrate how using suitable proxy variables improves the causal link estimation in the presence of hidden confounders.

Wasim Ahmad, Maha Shadaydeh, Joachim Denzler:
Causal Discovery using Model Invariance through Knockoff Interventions.
ICML Workshop on Spurious Correlations, Invariance and Stability (ICML-WS).
2022.
[bibtex]
[pdf]
[web]
[abstract]
Cause-effect analysis is crucial to understand the underlying mechanism of a system. We propose to exploit model invariance through interventions on the predictors to infer causality in nonlinear multivariate systems of time series. We model nonlinear interactions in time series using DeepAR and then expose the model to different environments using Knockoffs-based interventions to test model invariance. Knockoff samples are pairwise exchangeable, in-distribution and statistically null variables generated without knowing the response. We test model invariance where we show that the distribution of the response residual does not change significantly upon interventions on non-causal predictors. We evaluate our method on real and synthetically generated time series. Overall our method outperforms other widely used causality methods, i.e, VAR Granger causality, VARLiNGAM and PCMCI+.
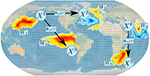
Xavier-Andoni Tibau, Christian Reimers, Andreas Gerhardus, Joachim Denzler, Veronika Eyring, Jakob Runge:
A spatiotemporal stochastic climate model for benchmarking causal discovery methods for teleconnections.
Environmental Data Science.
1 :
pp. E12.
2022.
[bibtex]
[web]
[doi]
[abstract]
Teleconnections that link climate processes at widely separated spatial locations form a key component of the climate system. Their analysis has traditionally been based on means, climatologies, correlations, or spectral properties, which cannot always reveal the dynamical mechanisms between different climatological processes. More recently, causal discovery methods based either on time series at grid locations or on modes of variability, estimated through dimension-reduction methods, have been introduced. A major challenge in the development of such analysis methods is a lack of ground truth benchmark datasets that have facilitated improvements in many parts of machine learning. Here, we present a simplified stochastic climate model that outputs gridded data and represents climate modes and their teleconnections through a spatially aggregated vector-autoregressive model. The model is used to construct benchmarks and evaluate a range of analysis methods. The results highlight that the model can be successfully used to benchmark different causal discovery methods for spatiotemporal data and show their strengths and weaknesses. Furthermore, we introduce a novel causal discovery method at the grid level and demonstrate that it has orders of magnitude better performance than the current approaches. Improved causal analysis tools for spatiotemporal climate data are pivotal to advance process-based understanding and climate model evaluation.

Bernd Gruner, Matthias Körschens, Björn Barz, Joachim Denzler:
Domain Adaptation and Active Learning for Fine-Grained Recognition in the Field of Biodiversity.
Findings of the CVPR Workshop on Continual Learning in Computer Vision (CLVision).
2021.
[bibtex]
[abstract]
Deep-learning methods offer unsurpassed recognition performance in a wide range of domains, including fine-grained recognition tasks. However, in most problem areas there are insufficient annotated training samples. Therefore, the topic of transfer learning respectively domain adaptation is particularly important. In this work, we investigate to what extent unsupervised domain adaptation can be used for fine-grained recognition in a biodiversity context to learn a real-world classifier based on idealized training data, e.g. preserved butterflies and plants. Moreover, we investigate the influence of different normalization layers, such as Group Normalization in combination with Weight Standardization, on the classifier. We discovered that domain adaptation works very well for fine-grained recognition and that the normalization methods have a great influence on the results. Using domain adaptation and Transferable Normalization, the accuracy of the classifier could be increased by up to 12.35 % compared to the baseline. Furthermore, the domain adaptation system is combined with an active learning component to improve the results. We compare different active learning strategies with each other. Surprisingly, we found that more sophisticated strategies provide better results than the random selection baseline for only one of the two datasets. In this case, the distance and diversity strategy performed best. Finally, we present a problem analysis of the datasets.

Bernd Radig, Paul Bodesheim, Dimitri Korsch, Joachim Denzler, Timm Haucke, Morris Klasen, Volker Steinhage:
Automated Visual Large Scale Monitoring of Faunal Biodiversity.
Pattern Recognition and Image Analysis. Advances in Mathematical Theory and Applications (PRIA).
31 (3) :
pp. 477-488.
2021.
[bibtex]
[pdf]
[web]
[doi]
[abstract]
To observe biodiversity, the variety of plant and animal life in the world or in a particular habitat, human observers make the most common examinations, often assisted by technical equipment. Measuring objectively the number of different species of animals, plants, fungi, and microbes that make up the ecosystem can be difficult. In order to monitor changes in biodiversity, data have to be compared across space and time. Cameras are an essential sensor to determine the species range, abundance, and behavior of animals. The millions of recordings from camera traps set up in natural environments can no longer be analyzed by biologists. We started research on doing this analysis automatically without human interaction. The focus of our present sensor is on image capture of wildlife and moths. Special hardware elements for the detection of different species are designed, implemented, tested, and improved, as well as the algorithms for classification and counting of samples from images and image sequences, e.g., to calculate presence, absence, and abundance values or the duration of characteristic activities related to the spatial mobilities. For this purpose, we are developing stereo camera traps that allow spatial reconstruction of the observed animals. This allows three-dimensional coordinates to be recorded and the shape to be characterized. With this additional feature data, species identification and movement detection are facilitated. To classify and count moths, they are attracted to an illuminated screen, which is then photographed at intervals by a high-resolution color camera. To greatly reduce the volume of data, redundant elements and elements that are consistent from image to image are eliminated. All design decisions take into account that at remote sites and in fully autonomous operation, power supply on the one hand and possibilities for data exchange with central servers on the other hand are limited. Installation at hard-to-reach locations requires a sophisticated and demanding system design with an optimal balance between power requirements, bandwidth for data transmission, required service and operation in all environmental conditions for at least ten years.

Björn Barz, Joachim Denzler:
Content-based Image Retrieval and the Semantic Gap in the Deep Learning Era.
ICPR Workshop on Content-Based Image Retrieval (CBIR2020).
Pages 245-260.
2021.
[bibtex]
[pdf]
[doi]
[abstract]
Content-based image retrieval has seen astonishing progress over the past decade, especially for the task of retrieving images of the same object that is depicted in the query image. This scenario is called instance or object retrieval and requires matching fine-grained visual patterns between images. Semantics, however, do not play a crucial role. This brings rise to the question: Do the recent advances in instance retrieval transfer to more generic image retrieval scenarios? To answer this question, we first provide a brief overview of the most relevant milestones of instance retrieval. We then apply them to a semantic image retrieval task and find that they perform inferior to much less sophisticated and more generic methods in a setting that requires image understanding. Following this, we review existing approaches to closing this so-called semantic gap by integrating prior world knowledge. We conclude that the key problem for the further advancement of semantic image retrieval lies in the lack of a standardized task definition and an appropriate benchmark dataset.

Björn Barz, Joachim Denzler:
WikiChurches: A Fine-Grained Dataset of Architectural Styles with Real-World Challenges.
NeurIPS 2021 Track on Datasets and Benchmarks.
2021.
[bibtex]
[pdf]
[presentation]
[abstract]
We introduce a novel dataset for architectural style classification, consisting of 9,485 images of church buildings. Both images and style labels were sourced from Wikipedia. The dataset can serve as a benchmark for various research fields, as it combines numerous real-world challenges: fine-grained distinctions between classes based on subtle visual features, a comparatively small sample size, a highly imbalanced class distribution, a high variance of viewpoints, and a hierarchical organization of labels, where only some images are labeled at the most precise level. In addition, we provide 631 bounding box annotations of characteristic visual features for 139 churches from four major categories. These annotations can, for example, be useful for research on fine-grained classification, where additional expert knowledge about distinctive object parts is often available. Images and annotations are available at: https://doi.org/10.5281/zenodo.5166986

Björn Barz, Kai Schröter, Ann-Christin Kra, Joachim Denzler:
Finding Relevant Flood Images on Twitter using Content-based Filters.
ICPR Workshop on Machine Learning Advances Environmental Science (MAES).
Pages 5-14.
2021.
[bibtex]
[pdf]
[web]
[doi]
[abstract]
The analysis of natural disasters such as floods in a timely manner often suffers from limited data due to coarsely distributed sensors or sensor failures. At the same time, a plethora of information is buried in an abundance of images of the event posted on social media platforms such as Twitter. These images could be used to document and rapidly assess the situation and derive proxy-data not available from sensors, e.g., the degree of water pollution. However, not all images posted online are suitable or informative enough for this purpose. Therefore, we propose an automatic filtering approach using machine learning techniques for finding Twitter images that are relevant for one of the following information objectives: assessing the flooded area, the inundation depth, and the degree of water pollution. Instead of relying on textual information present in the tweet, the filter analyzes the image contents directly. We evaluate the performance of two different approaches and various features on a case-study of two major flooding events. Our image-based filter is able to enhance the quality of the results substantially compared with a keyword-based filter, improving the mean average precision from 23% to 53% on average.

Christian Reimers, Niklas Penzel, Paul Bodesheim, Jakob Runge, Joachim Denzler:
Conditional Dependence Tests Reveal the Usage of ABCD Rule Features and Bias Variables in Automatic Skin Lesion Classification.
CVPR ISIC Skin Image Analysis Workshop (CVPR-WS).
Pages 1810-1819.
2021.
[bibtex]
[pdf]
[web]
[abstract]
Skin cancer is the most common form of cancer, and melanoma is the leading cause of cancer related deaths. To improve the chances of survival, early detection of melanoma is crucial. Automated systems for classifying skin lesions can assist with initial analysis. However, if we expect people to entrust their well-being to an automatic classification algorithm, it is important to ensure that the algorithm makes medically sound decisions. We investigate this question by testing whether two state-of-the-art models use the features defined in the dermoscopic ABCD rule or whether they rely on biases. We use a method that frames supervised learning as a structural causal model, thus reducing the question whether a feature is used to a conditional dependence test. We show that this conditional dependence method yields meaningful results on data from the ISIC archive. Furthermore, we find that the selected models incorporate asymmetry, border and dermoscopic structures in their decisions but not color. Finally, we show that the same classifiers also use bias features such as the patient's age, skin color or the existence of colorful patches.

Christian Reimers, Paul Bodesheim, Jakob Runge, Joachim Denzler:
Conditional Adversarial Debiasing: Towards Learning Unbiased Classifiers from Biased Data.
DAGM German Conference on Pattern Recognition (DAGM-GCPR).
Pages 48-62.
2021.
[bibtex]
[pdf]
[doi]
[abstract]
Bias in classifiers is a severe issue of modern deep learning methods, especially for their application in safety- and security-critical areas. Often, the bias of a classifier is a direct consequence of a bias in the training set, frequently caused by the co-occurrence of relevant features and irrelevant ones. To mitigate this issue, we require learning algorithms that prevent the propagation of known bias from the dataset into the classifier. We present a novel adversarial debiasing method, which addresses a feature of which we know that it is spuriously connected to the labels of training images but statistically independent of the labels for test images. The debiasing stops the classifier from falsly identifying this irrelevant feature as important. Irrelevant features co-occur with important features in a wide range of bias-related problems for many computer vision tasks, such as automatic skin cancer detection or driver assistance. We argue by a mathematical proof that our approach is superior to existing techniques for the abovementioned bias. Our experiments show that our approach performs better than the state-of-the-art on a well-known benchmark dataset with real-world images of cats and dogs.

Clemens-Alexander Brust, Björn Barz, Joachim Denzler:
Self-Supervised Learning from Semantically Imprecise Data.
arXiv preprint arXiv:2104.10901.
2021.
[bibtex]
[pdf]
[abstract]
Learning from imprecise labels such as "animal" or "bird", but making precise predictions like "snow bunting" at test time is an important capability when expertly labeled training data is scarce. Contributions by volunteers or results of web crawling lack precision in this manner, but are still valuable. And crucially, these weakly labeled examples are available in larger quantities for lower cost than high-quality bespoke training data. CHILLAX, a recently proposed method to tackle this task, leverages a hierarchical classifier to learn from imprecise labels. However, it has two major limitations. First, it is not capable of learning from effectively unlabeled examples at the root of the hierarchy, e.g. "object". Second, an extrapolation of annotations to precise labels is only performed at test time, where confident extrapolations could be already used as training data. In this work, we extend CHILLAX with a self-supervised scheme using constrained extrapolation to generate pseudo-labels. This addresses the second concern, which in turn solves the first problem, enabling an even weaker supervision requirement than CHILLAX. We evaluate our approach empirically and show that our method allows for a consistent accuracy improvement of 0.84 to 1.19 percent points over CHILLAX and is suitable as a drop-in replacement without any negative consequences such as longer training times.

Daphne Auer, Paul Bodesheim, Christian Fiderer, Marco Heurich, Joachim Denzler:
Minimizing the Annotation Effort for Detecting Wildlife in Camera Trap Images with Active Learning.
Computer Science for Biodiversity Workshop (CS4Biodiversity), INFORMATIK 2021.
Pages 547-564.
2021.
[bibtex]
[pdf]
[doi]
[abstract]
Analyzing camera trap images is a challenging task due to complex scene structures at different locations, heavy occlusions, and varying sizes of animals.One particular problem is the large fraction of images only showing background scenes, which are recorded when a motion detector gets triggered by signals other than animal movements.To identify these background images automatically, an active learning approach is used to train binary classifiers with small amounts of labeled data, keeping the annotation effort of humans minimal.By training classifiers for single sites or small sets of camera traps, we follow a region-based approach and particularly focus on distinct models for daytime and nighttime images.Our approach is evaluated on camera trap images from the Bavarian Forest National Park.Comparable or even superior performances to publicly available detectors trained with millions of labeled images are achieved while requiring significantly smaller amounts of annotated training images.

Dimitri Korsch, Paul Bodesheim, Joachim Denzler:
Deep Learning Pipeline for Automated Visual Moth Monitoring: Insect Localization and Species Classification.
INFORMATIK 2021, Computer Science for Biodiversity Workshop (CS4Biodiversity).
Pages 443-460.
2021.
[bibtex]
[pdf]
[web]
[doi]
[code]
[abstract]
Biodiversity monitoring is crucial for tracking and counteracting adverse trends in population fluctuations. However, automatic recognition systems are rarely applied so far, and experts evaluate the generated data masses manually. Especially the support of deep learning methods for visual monitoring is not yet established in biodiversity research, compared to other areas like advertising or entertainment. In this paper, we present a deep learning pipeline for analyzing images captured by a moth scanner, an automated visual monitoring system of moth species developed within the AMMOD project. We first localize individuals with a moth detector and afterward determine the species of detected insects with a classifier. Our detector achieves up to 99.01% mean average precision and our classifier distinguishes 200 moth species with an accuracy of 93.13% on image cutouts depicting single insects. Combining both in our pipeline improves the accuracy for species identification in images of the moth scanner from 79.62% to 88.05%.

Dimitri Korsch, Paul Bodesheim, Joachim Denzler:
End-to-end Learning of Fisher Vector Encodings for Part Features in Fine-grained Recognition.
DAGM German Conference on Pattern Recognition (DAGM-GCPR).
Pages 142-158.
2021.
[bibtex]
[pdf]
[web]
[doi]
[code]
[abstract]
Part-based approaches for fine-grained recognition do not show the expected performance gain over global methods, although explicitly focusing on small details that are relevant for distinguishing highly similar classes. We assume that part-based methods suffer from a missing representation of local features, which is invariant to the order of parts and can handle a varying number of visible parts appropriately. The order of parts is artificial and often only given by ground-truth annotations, whereas viewpoint variations and occlusions result in not observable parts. Therefore, we propose integrating a Fisher vector encoding of part features into convolutional neural networks. The parameters for this encoding are estimated by an online EM algorithm jointly with those of the neural network and are more precise than the estimates of previous works. Our approach improves state-of-the-art accuracies for three bird species classification datasets.

Felix Schneider, Phillip Brandes, Björn Barz, Sophie Marshall, Joachim Denzler:
Data-Driven Detection of General Chiasmi Using Lexical and Semantic Features.
SIGHUM Workshop on Computational Linguistics for Cultural Heritage, Social Sciences, Humanities and Literature.
Pages 96-100.
2021.
[bibtex]
[web]
[doi]
[abstract]
Automatic detection of stylistic devices is an important tool for literary studies, e.g., for stylometric analysis or argument mining. A particularly striking device is the rhetorical figure called chiasmus, which involves the inversion of semantically or syntactically related words. Existing works focus on a special case of chiasmi that involve identical words in an A B B A pattern, so-called antimetaboles. In contrast, we propose an approach targeting the more general and challenging case A B B’ A’, where the words A, A’ and B, B’ constituting the chiasmus do not need to be identical but just related in meaning. To this end, we generalize the established candidate phrase mining strategy from antimetaboles to general chiasmi and propose novel features based on word embeddings and lemmata for capturing both semantic and syntactic information. These features serve as input for a logistic regression classifier, which learns to distinguish between rhetorical chiasmi and coincidental chiastic word orders without special meaning. We evaluate our approach on two datasets consisting of classical German dramas, four texts with annotated chiasmi and 500 unannotated texts. Compared to previous methods for chiasmus detection, our novel features improve the average precision from 17% to 28% and the precision among the top 100 results from 13% to 35%.

Julia Böhlke, Dimitri Korsch, Paul Bodesheim, Joachim Denzler:
Exploiting Web Images for Moth Species Classification.
Computer Science for Biodiversity Workshop (CS4Biodiversity), INFORMATIK 2021.
Pages 481-498.
2021.
[bibtex]
[pdf]
[web]
[doi]
[abstract]
Due to shrinking habitats, moth populations are declining rapidly. An automated moth population monitoring tool is needed to support conservationists in making informed decisions for counteracting this trend. A non-invasive tool would involve the automatic classification of images of moths, a fine-grained recognition problem. Currently, the lack of images annotated by experts is the main hindrance to such a classification model. To understand how to achieve acceptable predictive accuracies, we investigate the effect of differently sized datasets and data acquired from the Internet. We find the use of web data immensely beneficial and observe that few images from the evaluation domain are enough to mitigate the domain shift in web data. Our experiments show that counteracting the domain shift may yield a relative reduction of the error rate of over 60\%. Lastly, the effect of label noise in web data and proposed filtering techniques are analyzed and evaluated.

Julia Böhlke, Dimitri Korsch, Paul Bodesheim, Joachim Denzler:
Lightweight Filtering of Noisy Web Data: Augmenting Fine-grained Datasets with Selected Internet Images.
International Conference on Computer Vision Theory and Applications (VISAPP).
Pages 466-477.
2021.
[bibtex]
[pdf]
[web]
[doi]
[abstract]
Despite the availability of huge annotated benchmark datasets and the potential of transfer learning, i.e., fine-tuning a pre-trained neural network to a specific task, deep learning struggles in applications where no labeled datasets of sufficient size exist. This issue affects fine-grained recognition tasks the most since correct image data annotations are expensive and require expert knowledge. Nevertheless, the Internet offers a lot of weakly annotated images. In contrast to existing work, we suggest a new lightweight filtering strategy to exploit this source of information without supervision and minimal additional costs. Our main contributions are specific filter operations that allow the selection of downloaded images to augment a training set. We filter test duplicates to avoid a biased evaluation of the methods, and two types of label noise: cross-domain noise, i.e., images outside any class in the dataset, and cross-class noise, a form of label-swapping noise. We evaluate our suggested filter operations in a controlled environment and demonstrate our methods' effectiveness with two small annotated seed datasets for moth species recognition. While noisy web images consistently improve classification accuracies, our filtering methoeds retain a fraction of the data such that high accuracies are achieved with a significantly smaller training dataset.

Lorenzo Brigato, Björn Barz, Luca Iocchi, Joachim Denzler:
Tune It or Don't Use It: Benchmarking Data-Efficient Image Classification.
ICCV Workshop on Visual Inductive Priors for Data-Efficient Deep Learning.
2021.
[bibtex]
[pdf]
[abstract]
Data-efficient image classification using deep neural networks in settings, where only small amounts of labeled data are available, has been an active research area in the recent past. However, an objective comparison between published methods is difficult, since existing works use different datasets for evaluation and often compare against untuned baselines with default hyper-parameters. We design a benchmark for data-efficient image classification consisting of six diverse datasets spanning various domains (e.g., natural images, medical imagery, satellite data) and data types (RGB, grayscale, multispectral). Using this benchmark, we re-evaluate the standard cross-entropy baseline and eight methods for data-efficient deep learning published between 2017 and 2021 at renowned venues. For a fair and realistic comparison, we carefully tune the hyper-parameters of all methods on each dataset. Surprisingly, we find that tuning learning rate, weight decay, and batch size on a separate validation split results in a highly competitive baseline, which outperforms all but one specialized method and performs competitively to the remaining one.

Maha Shadaydeh, Lea Müller, Dana Schneider, Martin Thümmel, Thomas Kessler, Joachim Denzler:
Analyzing the Direction of Emotional Influence in Nonverbal Dyadic Communication: A Facial-Expression Study.
IEEE Access.
9 :
pp. 73780-73790.
2021.
[bibtex]
[pdf]
[web]
[doi]
[presentation]
[abstract]
Identifying the direction of emotional influence in a dyadic dialogue is of increasing interest in the psychological sciences with applications in psychotherapy, analysis of political interactions, or interpersonal conflict behavior. Facial expressions are widely described as being automatic and thus hard to be overtly influenced. As such, they are a perfect measure for a better understanding of unintentional behavior cues about socio-emotional cognitive processes. With this view, this study is concerned with the analysis of the direction of emotional influence in dyadic dialogues based on facial expressions only. We exploit computer vision capabilities along with causal inference theory for quantitative verification of hypotheses on the direction of emotional influence, i.e., cause-effect relationships, in dyadic dialogues. We address two main issues. First, in a dyadic dialogue, emotional influence occurs over transient time intervals and with intensity and direction that are variant over time. To this end, we propose a relevant interval selection approach that we use prior to causal inference to identify those transient intervals where causal inference should be applied. Second, we propose to use fine-grained facial expressions that are present when strong distinct facial emotions are not visible. To specify the direction of influence, we apply the concept of Granger causality to the time-series of facial expressions over selected relevant intervals. We tested our approach on newly, experimentally obtained data. Based on quantitative verification of hypotheses on the direction of emotional influence, we were able to show that the proposed approach is promising to reveal the cause-effect pattern in various instructed interaction conditions.

Martin Thümmel, Sven Sickert, Joachim Denzler:
Facial Behavior Analysis using 4D Curvature Statistics for Presentation Attack Detection.
IEEE International Workshop on Biometrics and Forensics (IWBF).
Pages 1-6.
2021.
[bibtex]
[pdf]
[web]
[doi]
[code]
[abstract]
The human face has a high potential for biometric identification due to its many individual traits. At the same time, such identification is vulnerable to biometric copies. These presentation attacks pose a great challenge in unsupervised authentication settings. As a countermeasure, we propose a method that automatically analyzes the plausibility of facial behavior based on a sequence of 3D face scans. A compact feature representation measures facial behavior using the temporal curvature change. Finally, we train our method only on genuine faces in an anomaly detection scenario. Our method can detect presentation attacks using elastic 3D masks, bent photographs with eye holes, and monitor replay-attacks. For evaluation, we recorded a challenging database containing such cases using a high-quality 3D sensor. It features 109 4D face scans including eleven different types of presentation attacks. We achieve error rates of 11% and 6% for APCER and BPCER, respectively.

Matthias Körschens, Paul Bodesheim, Christine Römermann, Solveig Franziska Bucher, Mirco Migliavacca, Josephine Ulrich, Joachim Denzler:
Automatic Plant Cover Estimation with Convolutional Neural Networks.
Computer Science for Biodiversity Workshop (CS4Biodiversity), INFORMATIK 2021.
Pages 499-516.
2021.
[bibtex]
[pdf]
[doi]
[abstract]
Monitoring the responses of plants to environmental changes is essential for plant biodiversity research. This, however, is currently still being done manually by botanists in the field. This work is very laborious, and the data obtained is, though following a standardized method to estimate plant coverage, usually subjective and has a coarse temporal resolution. To remedy these caveats, we investigate approaches using convolutional neural networks (CNNs) to automatically extract the relevant data from images, focusing on plant community composition and species coverages of 9 herbaceous plant species. To this end, we investigate several standard CNN architectures and different pretraining methods. We find that we outperform our previous approach at higher image resolutions using a custom CNN with a mean absolute error of 5.16%. In addition to these investigations, we also conduct an error analysis based on the temporal aspect of the plant cover images. This analysis gives insight into where problems for automatic approaches lie, like occlusion and likely misclassifications caused by temporal changes.

Matthias Körschens, Paul Bodesheim, Christine Römermann, Solveig Franziska Bucher, Mirco Migliavacca, Josephine Ulrich, Joachim Denzler:
Weakly Supervised Segmentation Pretraining for Plant Cover Prediction.
DAGM German Conference on Pattern Recognition (DAGM-GCPR).
Pages 589-603.
2021.
[bibtex]
[pdf]
[doi]
[supplementary]
[abstract]
Automated plant cover prediction can be a valuable tool for botanists, as plant cover estimations are a laborious and recurring task in environmental research. Upon examination of the images usually encompassed in this task, it becomes apparent that the task is ill-posed and successful training on such images alone without external data is nearly impossible. While a previous approach includes pretraining on a domain-related dataset containing plants in natural settings, we argue that regular classification training on such data is insufficient. To solve this problem, we propose a novel pretraining pipeline utilizing weakly supervised object localization on images with only class annotations to generate segmentation maps that can be exploited for a second pretraining step. We utilize different pooling methods during classification pretraining, and evaluate and compare their effects on the plant cover prediction. For this evaluation, we focus primarily on the visible parts of the plants. To this end, contrary to previous works, we created a small dataset containing segmentations of plant cover images to be able to evaluate the benefit of our method numerically. We find that our segmentation pretraining approach outperforms classification pretraining and especially aids in the recognition of less prevalent plants in the plant cover dataset.

Niklas Penzel, Christian Reimers, Clemens-Alexander Brust, Joachim Denzler:
Investigating the Consistency of Uncertainty Sampling in Deep Active Learning.
DAGM German Conference on Pattern Recognition (DAGM-GCPR).
Pages 159-173.
2021.
[bibtex]
[pdf]
[web]
[doi]
[abstract]
Uncertainty sampling is a widely used active learning strategy to select unlabeled examples for annotation. However, previous work hints at weaknesses of uncertainty sampling when combined with deep learning, where the amount of data is even more significant. To investigate these problems, we analyze the properties of the latent statistical estimators of uncertainty sampling in simple scenarios. We prove that uncertainty sampling converges towards some decision boundary. Additionally, we show that it can be inconsistent, leading to incorrect estimates of the optimal latent boundary. The inconsistency depends on the latent class distribution, more specifically on the class overlap. Further, we empirically analyze the variance of the decision boundary and find that the performance of uncertainty sampling is also connected to the class regions overlap. We argue that our findings could be the first step towards explaining the poor performance of uncertainty sampling combined with deep models.

Oana-Iuliana Popescu, Maha Shadaydeh, Joachim Denzler:
Counterfactual Generation with Knockoffs.
arXiv preprint arXiv:2102.00951.
2021.
[bibtex]
[pdf]
[web]
[abstract]
Human interpretability of deep neural networks' decisions is crucial, especially in domains where these directly affect human lives. Counterfactual explanations of already trained neural networks can be generated by perturbing input features and attributing importance according to the change in the classifier's outcome after perturbation. Perturbation can be done by replacing features using heuristic or generative in-filling methods. The choice of in-filling function significantly impacts the number of artifacts, i.e., false-positive attributions. Heuristic methods result in false-positive artifacts because the image after the perturbation is far from the original data distribution. Generative in-filling methods reduce artifacts by producing in-filling values that respect the original data distribution. However, current generative in-filling methods may also increase false-negatives due to the high correlation of in-filling values with the original data. In this paper, we propose to alleviate this by generating in-fillings with the statistically-grounded Knockoffs framework, which was developed by Barber and Candès in 2015 as a tool for variable selection with controllable false discovery rate. Knockoffs are statistically null-variables as decorrelated as possible from the original data, which can be swapped with the originals without changing the underlying data distribution. A comparison of different in-filling methods indicates that in-filling with knockoffs can reveal explanations in a more causal sense while still maintaining the compactness of the explanations.

Violeta Teodora Trifunov, Maha Shadaydeh, Björn Barz, Joachim Denzler:
Anomaly Attribution of Multivariate Time Series using Counterfactual Reasoning.
IEEE International Conference on Machine Learning and Applications (ICMLA).
Pages 166-172.
2021.
[bibtex]
[pdf]
[web]
[doi]
[abstract]
There are numerous methods for detecting anomalies in time series, but that is only the first step to understanding them. We strive to exceed this by explaining those anomalies. Thus we develop a novel attribution scheme for multivariate time series relying on counterfactual reasoning. We aim to answer the counterfactual question of would the anomalous event have occurred if the subset of the involved variables had been more similarly distributed to the data outside of the anomalous interval. Specifically, we detect anomalous intervals using the Maximally Divergent Interval (MDI) algorithm, replace a subset of variables with their in-distribution values within the detected interval and observe if the interval has become less anomalous, by re-scoring it with MDI. We evaluate our method on multivariate temporal and spatio-temporal data and confirm the accuracy of our anomaly attribution of multiple well-understood extreme climate events such as heatwaves and hurricanes.

Violeta Teodora Trifunov, Maha Shadaydeh, Jakob Runge, Markus Reichstein, Joachim Denzler:
A Data-Driven Approach to Partitioning Net Ecosystem Exchange Using a Deep State Space Model.
IEEE Access.
9 :
pp. 107873-107883.
2021.
[bibtex]
[web]
[doi]
[abstract]
Describing ecosystem carbon fluxes is essential for deepening the understanding of the Earth system. However, partitioning net ecosystem exchange (NEE), i.e. the sum of ecosystem respiration (Reco) and gross primary production (GPP), into these summands is ill-posed since there can be infinitely many mathematically-valid solutions. We propose a novel data-driven approach to NEE partitioning using a deep state space model which combines the interpretability and uncertainty analysis of state space models with the ability of recurrent neural networks to learn the complex functions governing the data. We validate our proposed approach on the FLUXNET dataset. We suggest using both the past and the future of Reco’s predictors for training along with the nighttime NEE (NEEnight) to learn a dynamical model of Reco. We evaluate our nighttime Reco forecasts by comparing them to the ground truth NEEnight and obtain the best accuracy with respect to other partitioning methods. The learned nighttime Reco model is then used to forecast the daytime Reco conditioning on the future observations of different predictors, i.e., global radiation, air temperature, precipitation, vapor pressure deficit, and daytime NEE (NEEday). Subtracted from the NEEday, these estimates yield the GPP, finalizing the partitioning. Our purely data-driven daytime Reco forecasts are in line with the recent empirical partitioning studies reporting lower daytime Reco than the Reichstein method, which can be attributed to the Kok effect, i.e., the plant respiration being higher at night. We conclude that our approach is a good alternative for data-driven NEE partitioning and complements other partitioning methods.

Wasim Ahmad, Maha Shadaydeh, Joachim Denzler:
Causal Inference in Non-linear Time-series using Deep Networks and Knockoff Counterfactuals.
IEEE International Conference on Machine Learning and Applications (ICMLA).
Pages 449-454.
2021.
[bibtex]
[pdf]
[web]
[doi]
[abstract]
Estimating causal relations is vital in understanding the complex interactions in multivariate time series. Non-linear coupling of variables is one of the major challenges in accurate estimation of cause-effect relations. In this paper, we propose to use deep autoregressive networks (DeepAR) in tandem with counterfactual analysis to infer nonlinear causal relations in multivariate time series. We extend the concept of Granger causality using probabilistic forecasting with DeepAR. Since deep networks can neither handle missing input nor out-of-distribution intervention, we propose to use the Knockoffs framework (Barber and Candes, 2015) for generating intervention variables and consequently counterfactual probabilistic forecasting. Knockoff samples are independent of their output given the observed variables and exchangeable with their counterpart variables without changing the underlying distribution of the data. We test our method on synthetic as well as real-world time series datasets. Overall our method outperforms the widely used vector autoregressive Granger causality and PCMCI in detecting nonlinear causal dependency in multivariate time series.

Anish Raj, Oliver Mothes, Sven Sickert, Gerd F. Volk, Orlando Guntinas-Lichius, Joachim Denzler:
Automatic and Objective Facial Palsy Grading Index Prediction using Deep Feature Regression.
Annual Conference on Medical Image Understanding and Analysis (MIUA).
Pages 253-266.
2020.
[bibtex]
[pdf]
[web]
[doi]
[abstract]
One of the main reasons for a half-sided facial paralysis is caused by a dysfunction of the facial nerve. Physicians have to assess such a unilateral facial palsy with the help of standardized grading scales to evaluate the treatment. However, such assessments are usually very subjective and they are prone to variance and inconsistency between physicians regarding their experience. We propose an automatic non-biased method using deep features combined with a linear regression method for facial palsy grading index prediction. With an extension of the free software tool Auto-eFace we annotated images of facial palsy patients and healthy subjects according to a common facial palsy grading scale. In our experiments, we obtained an average grading error of 11%
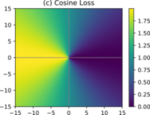
Björn Barz, Joachim Denzler:
Deep Learning on Small Datasets without Pre-Training using Cosine Loss.
IEEE Winter Conference on Applications of Computer Vision (WACV).
Pages 1360-1369.
2020.
[bibtex]
[pdf]
[doi]
[code]
[abstract]
Two things seem to be indisputable in the contemporary deep learning discourse: 1. The categorical cross-entropy loss after softmax activation is the method of choice for classification. 2. Training a CNN classifier from scratch on small datasets does not work well. In contrast to this, we show that the cosine loss function provides substantially better performance than cross-entropy on datasets with only a handful of samples per class. For example, the accuracy achieved on the CUB-200-2011 dataset without pre-training is by 30% higher than with the cross-entropy loss. Further experiments on other popular datasets confirm our findings. Moreover, we demonstrate that integrating prior knowledge in the form of class hierarchies is straightforward with the cosine loss and improves classification performance further.

Björn Barz, Joachim Denzler:
Do We Train on Test Data? Purging CIFAR of Near-Duplicates.
Journal of Imaging.
6 (6) :
2020.
[bibtex]
[pdf]
[web]
[doi]
[abstract]
We find that 3.3% and 10% of the images from the CIFAR-10 and CIFAR-100 test sets, respectively, have duplicates in the training set. This may incur a bias on the comparison of image recognition techniques with respect to their generalization capability on these heavily benchmarked datasets. To eliminate this bias, we provide the "fair CIFAR" (ciFAIR) dataset, where we replaced all duplicates in the test sets with new images sampled from the same domain. The training set remains unchanged, in order not to invalidate pre-trained models. We then re-evaluate the classification performance of various popular state-of-the-art CNN architectures on these new test sets to investigate whether recent research has overfitted to memorizing data instead of learning abstract concepts. We find a significant drop in classification accuracy of between 9% and 14% relative to the original performance on the duplicate-free test set. The ciFAIR dataset and pre-trained models are available at https://cvjena.github.io/cifair/, where we also maintain a leaderboard.

Christian Reimers, Jakob Runge, Joachim Denzler:
Determining the Relevance of Features for Deep Neural Networks.
European Conference on Computer Vision.
Pages 330-346.
2020.
[bibtex]
[abstract]
Deep neural networks are tremendously successful in many applications, but end-to-end trained networks often result in hard to un- derstand black-box classifiers or predictors. In this work, we present a novel method to identify whether a specific feature is relevant to a clas- sifier’s decision or not. This relevance is determined at the level of the learned mapping, instead of for a single example. The approach does neither need retraining of the network nor information on intermedi- ate results or gradients. The key idea of our approach builds upon con- cepts from causal inference. We interpret machine learning in a struc- tural causal model and use Reichenbach’s common cause principle to infer whether a feature is relevant. We demonstrate empirically that the method is able to successfully evaluate the relevance of given features on three real-life data sets, namely MS COCO, CUB200 and HAM10000.

Clemens-Alexander Brust, Björn Barz, Joachim Denzler:
Making Every Label Count: Handling Semantic Imprecision by Integrating Domain Knowledge.
International Conference on Pattern Recognition (ICPR).
2020.
[bibtex]
[pdf]
[doi]
[abstract]
Noisy data, crawled from the web or supplied by volunteers such as Mechanical Turkers or citizen scientists, is considered an alternative to professionally labeled data. There has been research focused on mitigating the effects of label noise. It is typically modeled as inaccuracy, where the correct label is replaced by an incorrect label from the same set. We consider an additional dimension of label noise: imprecision. For example, a non-breeding snow bunting is labeled as a bird. This label is correct, but not as precise as the task requires. Standard softmax classifiers cannot learn from such a weak label because they consider all classes mutually exclusive, which non-breeding snow bunting and bird are not. We propose CHILLAX (Class Hierarchies for Imprecise Label Learning and Annotation eXtrapolation), a method based on hierarchical classification, to fully utilize labels of any precision. Experiments on noisy variants of NABirds and ILSVRC2012 show that our method outperforms strong baselines by as much as 16.4 percentage points, and the current state of the art by up to 3.9 percentage points.

Clemens-Alexander Brust, Christoph Käding, Joachim Denzler:
Active and Incremental Learning with Weak Supervision.
Künstliche Intelligenz (KI).
2020.
[bibtex]
[pdf]
[doi]
[abstract]
Large amounts of labeled training data are one of the main contributors to the great success that deep models have achieved in the past. Label acquisition for tasks other than benchmarks can pose a challenge due to requirements of both funding and expertise. By selecting unlabeled examples that are promising in terms of model improvement and only asking for respective labels, active learning can increase the efficiency of the labeling process in terms of time and cost. In this work, we describe combinations of an incremental learning scheme and methods of active learning. These allow for continuous exploration of newly observed unlabeled data. We describe selection criteria based on model uncertainty as well as expected model output change (EMOC). An object detection task is evaluated in a continu ous exploration context on the PASCAL VOC dataset. We also validate a weakly supervised system based on active and incremental learning in a real-world biodiversity application where images from camera traps are analyzed. Labeling only 32 images by accepting or rejecting proposals generated by our method yields an increase in accuracy from 25.4% to 42.6%.

Jhonatan Contreras, Sven Sickert, Joachim Denzler:
Region-based Edge Convolutions with Geometric Attributes for the Semantic Segmentation of Large-scale 3D Point Clouds.
IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing.
13 (1) :
pp. 2598-2609.
2020.
[bibtex]
[pdf]
[web]
[doi]
[abstract]
In this paper, we present a semantic segmentation framework for large-scale 3D point clouds with high spatial resolution. For such data with huge amounts of points, the classification of each individual 3D point is an intractable task. Instead, we propose to segment the scene into meaningful regions as a first step. Afterward, we classify these segments using a combination of PointNet and geometric deep learning. This two-step approach resembles object-based image analysis. As an additional novelty, we apply surface normalization techniques and enrich features with geometric attributes. Our experiments show the potential of this approach for a variety of outdoor scene analysis tasks. In particular, we are able to reach 89.6\% overall accuracy and 64.4\% average intersection over union (IoU) in the Semantic3D benchmark. Furthermore, we achieve 66.7\% average IoU on Paris-Lille-3D. We also successfully apply our approach to the automatic semantic analysis of forestry data.

Maha Shadaydeh, Yanira Guanche Garcia, Miguel Mahecha, Joachim Denzler:
Understanding Changes in Environmental Time Series with Time-frequency Causality Analysis.
European Geosciences Union General Assembly (EGU): Abstract + Poster Presentation.
2020.
[bibtex]
[pdf]
[web]
[abstract]
Understanding causal effect relationships between the different variables in dynamical systems is an important and challenging problem in different areas of research such as attribution of climate change, brain neural connectivity analysis, psychology, among many others. These relationships are guided by the process generating them. Hence, detecting changes or new patterns in the causal effect relationships can be used not only for the detection but also for the diagnosis and attribution of changes in the underlying process.Time series of environmental time series most often contain multiple periodical components, e.g. daily and seasonal cycles, induced by the meteorological forcing variables. This can significantly mask the underlying endogenous causality structure when using time-domain analysis and therefore results in several spurious links. Filtering these periodic components as preprocessing step might degrade causal inference. This motivates the use of time-frequency processing techniques such as Wavelet or short-time Fourier transform where the causality structure can be examined at each frequency component and on multiple time scales.In this study, we use a parametric time-frequency representation of vector autoregressive Granger causality for causal inference. We first show that causal inference using time-frequency domain analysis outperforms time-domain analysis when dealing with time series that contain periodic components, trends, or noise. The proposed approach allows for the estimation of the causal effect interaction between each pair of variables in the system on multiple time scales and hence for excluding links that result from periodic components.Second, we investigate whether anomalous events can be identified based on the observed changes in causal relationships. We consider two representative examples in environmental systems: land-atmosphere ecosystem and marine climate. Through these two examples, we show that an anomalous event can indeed be identified as the event where the causal intensities differ according to a distance measure from the average causal intensities. Two different methods are used for testing the statistical significance of the causal-effect intensity at each frequency component.Once the anomalous event is detected, the driver of the event can be identified based on the analysis of changes in the obtained causal effect relationships during the time duration of the event and consequently provide an explanation of the detected anomalous event. Current research efforts are directed towards the extension of this work by using nonlinear state-space models, both statistical and deep learning-based ones.

Marcel Simon, Erik Rodner, Trevor Darell, Joachim Denzler:
The Whole Is More Than Its Parts? From Explicit to Implicit Pose Normalization.
IEEE Transactions on Pattern Analysis and Machine Intelligence.
42 (3) :
pp. 749-763.
2020.
(Pre-print published in 2019.)
[bibtex]
[pdf]
[web]
[doi]
[abstract]
Fine-grained classification describes the automated recognition of visually similar object categories like birds species. Previous works were usually based on explicit pose normalization, i.e., the detection and description of object parts. However, recent models based on a final global average or bilinear pooling have achieved a comparable accuracy without this concept. In this paper, we analyze the advantages of these approaches over generic CNNs and explicit pose normalization approaches. We also show how they can achieve an implicit normalization of the object pose. A novel visualization technique called activation flow is introduced to investigate limitations in pose handling in traditional CNNs like AlexNet and VGG. Afterward, we present and compare the explicit pose normalization approach neural activation constellations and a generalized framework for the final global average and bilinear pooling called α-pooling. We observe that the latter often achieves a higher accuracy improving common CNN models by up to 22.9%, but lacks the interpretability of the explicit approaches. We present a visualization approach for understanding and analyzing predictions of the model to address this issue. Furthermore, we show that our approaches for fine-grained recognition are beneficial for other fields like action recognition.

Matthias Körschens, Paul Bodesheim, Christine Römermann, Solveig Franziska Bucher, Josephine Ulrich, Joachim Denzler:
Towards Confirmable Automated Plant Cover Determination.
ECCV Workshop on Computer Vision Problems in Plant Phenotyping (CVPPP).
2020.
[bibtex]
[pdf]
[web]
[doi]
[supplementary]
[abstract]
Changes in plant community composition reflect environmental changes like in land-use and climate. While we have the means to record the changes in composition automatically nowadays, we still lack methods to analyze the generated data masses automatically. We propose a novel approach based on convolutional neural networks for analyzing the plant community composition while making the results explainable for the user. To realize this, our approach generates a semantic segmentation map while predicting the cover percentages of the plants in the community. The segmentation map is learned in a weakly supervised way only based on plant cover data and therefore does not require dedicated segmentation annotations. Our approach achieves a mean absolute error of 5.3% for plant cover prediction on our introduced dataset with 9 herbaceous plant species in an imbalanced distribution, and generates segmentation maps, where the location of the most prevalent plants in the dataset is correctly indicated in many images.

Sheeba Samuel, Maha Shadaydeh, Sebastian Böcker, Bernd Brügmann, Solveig F. Bucher, Volker Deckert, Joachim Denzler, Peter Dittrich, Ferdinand von Eggeling, Daniel Güllmar, Orlando Guntinas-Lichius, Birgitta König-Ries, Frank Löffler, Lutz Maicher, Manja Marz, Mirco Migliavacca, Jürgen R. Reichenbach, Markus Reichstein, Christine Römermann, Andrea Wittig:
A Virtual Werkstatt for Digitization in the Sciences.
Research Ideas and Outcomes.
6 :
2020.
[bibtex]
[web]
[doi]
[abstract]
Data is central in almost all scientific disciplines nowadays. Furthermore, intelligent systems have developed rapidly in recent years, so that in many disciplines the expectation is emerging that with the help of intelligent systems, significant challenges can be overcome and science can be done in completely new ways. In order for this to succeed, however, first, fundamental research in computer science is still required, and, second, generic tools must be developed on which specialized solutions can be built. In this paper, we introduce a recently started collaborative project funded by the Carl Zeiss Foundation, a virtual manufactory for digitization in the sciences, the "Werkstatt", which is being established at the Michael Stifel Center Jena (MSCJ) for data-driven and simulation science to address fundamental questions in computer science and applications. The Werkstatt focuses on three key areas, which include generic tools for machine learning, knowledge generation using machine learning processes, and semantic methods for the data life cycle, as well as the application of these topics in different disciplines. Core and pilot projects address the key aspects of the topics and form the basis for sustainable work in the Werkstatt.

Björn Barz, Erik Rodner, Yanira Guanche Garcia, Joachim Denzler:
Detecting Regions of Maximal Divergence for Spatio-Temporal Anomaly Detection.
IEEE Transactions on Pattern Analysis and Machine Intelligence.
41 (5) :
pp. 1088-1101.
2019.
(Pre-print published in 2018.)
[bibtex]
[pdf]
[web]
[doi]
[code]
[abstract]
Automatic detection of anomalies in space- and time-varying measurements is an important tool in several fields, e.g., fraud detection, climate analysis, or healthcare monitoring. We present an algorithm for detecting anomalous regions in multivariate spatio-temporal time-series, which allows for spotting the interesting parts in large amounts of data, including video and text data. In opposition to existing techniques for detecting isolated anomalous data points, we propose the "Maximally Divergent Intervals" (MDI) framework for unsupervised detection of coherent spatial regions and time intervals characterized by a high Kullback-Leibler divergence compared with all other data given. In this regard, we define an unbiased Kullback-Leibler divergence that allows for ranking regions of different size and show how to enable the algorithm to run on large-scale data sets in reasonable time using an interval proposal technique. Experiments on both synthetic and real data from various domains, such as climate analysis, video surveillance, and text forensics, demonstrate that our method is widely applicable and a valuable tool for finding interesting events in different types of data.
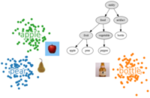
Björn Barz, Joachim Denzler:
Hierarchy-based Image Embeddings for Semantic Image Retrieval.
IEEE Winter Conference on Applications of Computer Vision (WACV).
Pages 638-647.
2019.
Best Paper Award
[bibtex]
[pdf]
[web]
[doi]
[code]
[presentation]
[supplementary]
[abstract]
Deep neural networks trained for classification have been found to learn powerful image representations, which are also often used for other tasks such as comparing images w.r.t. their visual similarity. However, visual similarity does not imply semantic similarity. In order to learn semantically discriminative features, we propose to map images onto class embeddings whose pair-wise dot products correspond to a measure of semantic similarity between classes. Such an embedding does not only improve image retrieval results, but could also facilitate integrating semantics for other tasks, e.g., novelty detection or few-shot learning. We introduce a deterministic algorithm for computing the class centroids directly based on prior world-knowledge encoded in a hierarchy of classes such as WordNet. Experiments on CIFAR-100, NABirds, and ImageNet show that our learned semantic image embeddings improve the semantic consistency of image retrieval results by a large margin.

Christian Reimers, Jakob Runge, Joachim Denzler:
Using Causal Inference to Globally Understand Black Box Predictors Beyond Saliency Maps.
International Workshop on Climate Informatics (CI).
2019.
[bibtex]
[pdf]
[doi]
[abstract]
State-of-the-art machine learning methods, especially deep neural networks, have reached impressive results in many prediction and classification tasks. Rising complexity and automatic feature selection make the resulting learned models hard to interpret and turns them into black boxes. Advances into feature visualization have mitigated this problem but some shortcomings still exist. For example, methods only work locally, meaning they only explain the behavior for single inputs, and they only identify important parts of the input. In this work, we propose a method that is also able to decide whether a feature calculated from the input to an estimator is globally useful. Since the question about explanatory power is a causal one, we frame this approach with causal inference methods.

Christian Requena-Mesa, Markus Reichstein, Miguel Mahecha, Basil Kraft, Joachim Denzler:
Predicting Landscapes from Environmental Conditions Using Generative Networks.
DAGM German Conference on Pattern Recognition (DAGM-GCPR).
Pages 203-217.
2019.
[bibtex]
[doi]
[abstract]
Landscapes are meaningful ecological units that strongly depend on the environmental conditions. Such dependencies between landscapes and the environment have been noted since the beginning of Earth sciences and cast into conceptual models describing the interdependencies of climate, geology, vegetation and geomorphology. Here, we ask whether landscapes, as seen from space, can be statistically predicted from pertinent environmental conditions. To this end we adapted a deep learning generative model in order to establish the relationship between the environmental conditions and the view of landscapes from the Sentinel-2 satellite. We trained a conditional generative adversarial network to generate multispectral imagery given a set of climatic, terrain and anthropogenic predictors. The generated imagery of the landscapes share many characteristics with the real one. Results based on landscape patch metrics, indicative of landscape composition and structure, show that the proposed generative model creates landscapes that are more similar to the targets than the baseline models while overall reflectance and vegetation cover are predicted better. We demonstrate that for many purposes the generated landscapes behave as real with immediate application for global change studies. We envision the application of machine learning as a tool to forecast the effects of climate change on the spatial features of landscapes, while we assess its limitations and breaking points.

Clemens-Alexander Brust, Christoph Käding, Joachim Denzler:
Active Learning for Deep Object Detection.
International Conference on Computer Vision Theory and Applications (VISAPP).
Pages 181-190.
2019.
[bibtex]
[pdf]
[doi]
[abstract]
The great success that deep models have achieved in the past is mainly owed to large amounts of labeled training data. However, the acquisition of labeled data for new tasks aside from existing benchmarks is both challenging and costly. Active learning can make the process of labeling new data more efficient by selecting unlabeled samples which, when labeled, are expected to improve the model the most. In this paper, we combine a novel method of active learning for object detection with an incremental learning scheme to enable continuous exploration of new unlabeled datasets. We propose a set of uncertainty-based active learning metrics suitable for most object detectors. Furthermore, we present an approach to leverage class imbalances during sample selection. All methods are evaluated systematically in a continuous exploration context on the PASCAL VOC 2012 dataset.

Clemens-Alexander Brust, Joachim Denzler:
Integrating Domain Knowledge: Using Hierarchies to Improve Deep Classifiers.
Asian Conference on Pattern Recognition (ACPR).
2019.
[bibtex]
[pdf]
[abstract]
One of the most prominent problems in machine learning in the age of deep learning is the availability of sufficiently large annotated datasets. For specific domains, \eg animal species, a long-tail distribution means that some classes are observed and annotated insufficiently. Additional labels can be prohibitively expensive, e.g. because domain experts need to be involved. However, there is more information available that is to the best of our knowledge not exploited accordingly. In this paper, we propose to make use of preexisting class hierarchies like WordNet to integrate additional domain knowledge into classification. We encode the properties of such a class hierarchy into a probabilistic model. From there, we derive a novel label encoding and a corresponding loss function. On the ImageNet and NABirds datasets our method offers a relative improvement of 10.4% and 9.6% in accuracy over the baseline respectively. After less than a third of training time, it is already able to match the baseline's fine-grained recognition performance. Both results show that our suggested method is efficient and effective.

Clemens-Alexander Brust, Joachim Denzler:
Not just a Matter of Semantics: The Relationship between Visual Similarity and Semantic Similarity.
DAGM German Conference on Pattern Recognition (DAGM-GCPR).
Pages 414-427.
2019.
[bibtex]
[pdf]
[doi]
[abstract]
Knowledge transfer, zero-shot learning and semantic image retrieval are methods that aim at improving accuracy by utilizing semantic information, e.g., from WordNet. It is assumed that this information can augment or replace missing visual data in the form of labeled training images because semantic similarity correlates with visual similarity. This assumption may seem trivial, but is crucial for the application of such semantic methods. Any violation can cause mispredictions. Thus, it is important to examine the visual-semantic relationship for a certain target problem. In this paper, we use five different semantic and visual similarity measures each to thoroughly analyze the relationship without relying too much on any single definition. We postulate and verify three highly consequential hypotheses on the relationship. Our results show that it indeed exists and that WordNet semantic similarity carries more information about visual similarity than just the knowledge of �different classes look different�. They suggest that classification is not the ideal application for semantic methods and that wrong semantic information is much worse than none.

Dimitri Korsch, Paul Bodesheim, Joachim Denzler:
Classification-Specific Parts for Improving Fine-Grained Visual Categorization.
DAGM German Conference on Pattern Recognition (DAGM-GCPR).
Pages 62-75.
2019.
[bibtex]
[pdf]
[web]
[doi]
[code]
[abstract]
Fine-grained visual categorization is a classification task for distinguishing categories with high intra-class and small inter-class variance. While global approaches aim at using the whole image for performing the classification, part-based solutions gather additional local information in terms of attentions or parts. We propose a novel classification-specific part estimation that uses an initial prediction as well as back-propagation of feature importance via gradient computations in order to estimate relevant image regions. The subsequently detected parts are then not only selected by a-posteriori classification knowledge, but also have an intrinsic spatial extent that is determined automatically. This is in contrast to most part-based approaches and even to available ground-truth part annotations, which only provide point coordinates and no additional scale information. We show in our experiments on various widely-used fine-grained datasets the effectiveness of the mentioned part selection method in conjunction with the extracted part features.
Erik Rodner, Thomas Bocklitz, Ferdinand von Eggeling, Günther Ernst, Olga Chernavskaia, Jürgen Popp, Joachim Denzler, Orlando Guntinas-Lichius:
Fully Convolutional Networks in Multimodal Nonlinear Microscopy Images for Automated Detection of Head and Neck Carcinoma: A Pilot Study.
Head \& Neck.
41 (1) :
pp. 116-121.
2019.
[bibtex]
[web]
[doi]
[abstract]
A fully convolutional neural networks (FCN)-based automated image analysis algorithm to discriminate between head and neck cancer and noncancerous epithelium based on nonlinear microscopic images was developed. Head and neck cancer sections were used for standard histopathology and co-registered with multimodal images from the same sections using the combination of coherent anti-Stokes Raman scattering, two-photon excited fluorescence, and second harmonic generation microscopy. The images analyzed with semantic segmentation using a FCN for four classes: cancer, normal epithelium, background, and other tissue types. A total of 114 images of 12 patients were analyzed. Using a patch score aggregation, the average recognition rate and an overall recognition rate or the four classes were 88.9\% and 86.7\%, respectively. A total of 113 seconds were needed to process a whole-slice image in the dataset. Multimodal nonlinear microscopy in combination with automated image analysis using FCN seems to be a promising technique for objective differentiation between head and neck cancer and noncancerous epithelium.

Gerd F. Volk, Martin Thümmel, Oliver Mothes, Dirk Arnold, Jovanna Thielker, Joachim Denzler, Valeria Mastryukova, Winfried Mayr, Orlando Guntinas-Lichius:
Long-term home-based Surface Electrostimulation is useful to prevent atrophy in denervated Facial Muscles.
Vienna Workshop on Functional Electrical Stimulation (FESWS).
2019.
[bibtex]
[pdf]
[abstract]
5 patients with facial paralysis received a home-based electrostimulation (ES) with charge-balanced biphasic triangular impulses 3x5min twice a day. Before the first ES, and every 4 weeks during the ES, all patients underwent regular needle electromyography (EMG), ultrasound and 3D-video measurements. Additionally, stimulation settings, patients? home-stimulation diaries and parameters were recorded. No patient reported relevant adverse events linked to ES. Training with optimized electrode positioning was associated with stable and specific zygomaticus muscle activation, accompanied by a reduction of the necessary minimum pulse duration from 250 to 70ms per phase within 16 weeks. Even before reinnervation, objective 3D-videos, sonography, MRI, and patient-related parameters (FDI, FaCE) improved significantly compared to the pre-stimulation situation. Preliminary results suggest that ES home-based training is beneficial for patients with denervated facial muscles in reducing muscle atrophy, maintaining muscle function and improving facial symmetry. A lack of relevant adverse events shows that such ES is safe. The patients showed excellent compliance with the protocol and rated the stimulation easy and effective.

Jhonatan Contreras, Joachim Denzler:
Edge-Convolution Point Net For Semantic Segmentation Of Large-Scale Point Clouds.
IEEE International Geoscience and Remote Sensing Symposium (IGARSS).
Pages 5236-5239.
2019.
[bibtex]
[web]
[doi]
[abstract]
We propose a deep learning-based framework which can manage large-scale point clouds of outdoor scenes with high spatial resolution. Analogous to Object-Based Image Analysis (OBIA), our approach segments the scene by grouping similar points together to generate meaningful objects. Later, our net classifies segments instead of individual points using an architecture inspired by PointNet, which applies Edge convolutions, making our approach efficient. Usually, Light Detection and Ranging (LiDAR) data do not come together with RGB information. This approach was trained using both RBG and RGB+XYZ information. In some circumstances, LiDAR data presents patterns that do not correspond to the surface object. This mainly occurs when objects partially block beans of light, to address this issue, normalized elevation was included in the analysis to make the model more robust.

Jhonatan Contreras, Joachim Denzler, Sven Sickert:
Automatically Estimating Forestal Characteristics in 3D Point Clouds using Deep Learning.
iDiv Annual Conference.
2019.
Abstract + Poster Presentation
[bibtex]
[web]
[abstract]
Biodiversity changes can be monitored using georeferenced and multitempo-ral data. Those changes refer to the process of automatically identifying differ-ences in the measurements computed over time. The height and the Diameterat Breast Height of the trees can be measured at different times. The mea-surements of individual trees can be tracked over the time resulting in growthrates, tree survival, among other possibles applications. We propose a deeplearning-based framework for semantic segmentation, which can manage largepoint clouds of forest areas with high spatial resolution. Our method divides apoint cloud into geometrically homogeneous segments. Then, a global feature isobtained from each segment, applying a deep learning network called PointNet.Finally, the local information of the adjacent segments is included through anadditional sub-network which applies edge convolutions. We successfully trainand test in a data set which covers an area with multiple trees. Two addi-tional forest areas were also tested. The semantic segmentation accuracy wastested using F1-score for four semantic classes:leaves(F1 = 0.908),terrain(F1 = 0.921),trunk(F1 = 0.848) anddead wood(F1 = 0.835). Furthermore,we show how our framework can be extended to deal with forest measurementssuch as measuring the height of the trees and the DBH.

Lea Müller, Maha Shadaydeh, Martin Thümmel, Thomas Kessler, Dana Schneider, Joachim Denzler:
Causal Inference in Nonverbal Dyadic Communication with Relevant Interval Selection and Granger Causality.
International Conference on Computer Vision Theory and Applications (VISAPP).
Pages 490-497.
2019.
[bibtex]
[pdf]
[web]
[doi]
[abstract]
Human nonverbal emotional communication in dyadic dialogs is a process of mutual influence and adaptation. Identifying the direction of influence, or cause-effect relation between participants, is a challenging task due to two main obstacles. First, distinct emotions might not be clearly visible. Second, participants cause-effect relation is transient and variant over time. In this paper, we address these difficulties by using facial expressions that can be present even when strong distinct facial emotions are not visible. We also propose to apply a relevant interval selection approach prior to causal inference to identify those transient intervals where adaptation process occurs. To identify the direction of influence, we apply the concept of Granger causality to the time series of facial expressions on the set of relevant intervals. We tested our approach on synthetic data and then applied it to newly, experimentally obtained data. Here, we were able to show that a more sensitive facial expression detection algorithm and a relevant interval detection approach is most promising to reveal the cause-effect pattern for dyadic communication in various instructed interaction conditions.

Maha Shadaydeh, Joachim Denzler, Yanira Guanche Garcia, Miguel Mahecha:
Time-Frequency Causal Inference Uncovers Anomalous Events in Environmental Systems.
DAGM German Conference on Pattern Recognition (DAGM-GCPR).
Pages 499-512.
2019.
[bibtex]
[pdf]
[doi]
[abstract]
Causal inference in dynamical systems is a challenge for dif- ferent research areas. So far it is mostly about understanding to what extent the underlying causal mechanisms can be derived from observed time series. Here we investigate whether anomalous events can also be identified based on the observed changes in causal relationships. We use a parametric time-frequency representation of vector autoregressive Granger causality for causal inference. The use of time-frequency ap- proach allows for dealing with the nonstationarity of the time series as well as for defining the time scale on which changes occur. We present two representative examples in environmental systems: land-atmosphere ecosystem and marine climate. We show that an anomalous event can be identified as the event where the causal intensities differ according to a distance measure from the average causal intensities. The driver of the anomalous event can then be identified based on the analysis of changes in the causal effect relationships.
Marie Arlt, Jack Peter, Sven Sickert, Clemens-Alexander Brust, Joachim Denzler, Andreas Stallmach:
Automated Polyp Differentiation on Coloscopic Data using Semantic Segmentation with CNNs.
Endoscopy.
51 (04) :
pp. 4.
2019.
Abstract + Poster Presentation
[bibtex]
[web]
[doi]
[abstract]
Interval carcinomas are a commonly known problem in endoscopic adenoma detection, especially when they follow negative index colonoscopy. To prevent patients from these carcinomas and support the endoscopist, we reach for a live assisted system in the future, which helps to remark polyps and increase adenoma detection rate. We present our first results of polyp recognition using a machine learning approach.
Markus Reichstein, Gustau Camps-Valls, Bjorn Stevens, Martin Jung, Joachim Denzler, Nuno Carvalhais, Prabhat:
Deep learning and process understanding for data-driven Earth system science.
Nature.
566 (7743) :
pp. 195-204.
2019.
[bibtex]
[web]
[doi]
[abstract]
Machine learning approaches are increasingly used to extract patterns and insights from the ever-increasing stream of geospatial data, but current approaches may not be optimal when system behaviour is dominated by spatial or temporal context. Here, rather than amending classical machine learning, we argue that these contextual cues should be used as part of deep learning (an approach that is able to extract spatio-temporal features automatically) to gain further process understanding of Earth system science problems, improving the predictive ability of seasonal forecasting and modelling of long-range spatial connections across multiple timescales, for example. The next step will be a hybrid modelling approach, coupling physical process models with the versatility of data-driven machine learning.

Matthias Körschens, Joachim Denzler:
ELPephants: A Fine-Grained Dataset for Elephant Re-Identification.
ICCV Workshop on Computer Vision for Wildlife Conservation (ICCV-WS).
2019.
[bibtex]
[pdf]
[abstract]
Despite many possible applications, machine learning and computer vision approaches are very rarely utilized in biodiversity monitoring. One reason for this might be that automatic image analysis in biodiversity research often poses a unique set of challenges, some of which are not commonly found in many popular datasets. Thus, suitable image datasets are necessary for the development of appropriate algorithms tackling these challenges. In this paper we introduce the ELPephants dataset, a re-identification dataset, which contains 276 elephant individuals in 2078 images following a long-tailed distribution. It offers many different challenges, like fine-grained differences between the individuals, inferring a new view on the elephant from only one training side, aging effects on the animals and large differences in skin color. We also present a baseline approach, which is a system using a YOLO object detector, feature extraction of ImageNet features and discrimination using a support vector machine. This system achieves a top-1 accuracy of 56% and top-10 accuracy of 80% on the ELPephants dataset.
Nils Gählert, Niklas Hanselmann, Uwe Franke, Joachim Denzler:
Visibility Guided NMS: Efficient Boosting of Amodal Object Detection in Crowded Traffic Scenes.
Machine Learning for Autonomous Driving Workshop at NeurIPS (NeurIPS-WS).
2019.
[bibtex]
[abstract]
Object detection is an important task in environment perception for autonomous driving. Modern 2D object detection frameworks such as Yolo, SSD or Faster R-CNN predict multiple bounding boxes per object that are refined using Non- Maximum Suppression (NMS) to suppress all but one bounding box. While object detection itself is fully end-to-end learnable and does not require any manual parameter selection, standard NMS is parametrized by an overlap threshold that has to be chosen by hand. In practice, this often leads to an inability of standard NMS strategies to distinguish different objects in crowded scenes in the presence of high mutual occlusion, e.g. for parked cars or crowds of pedestians. Our novel Visibility Guided NMS (vg-NMS) leverages both pixel-based as well as amodal object detection paradigms and improves the detection performance especially for highly occluded objects with little computational overhead. We evaluate vg-NMS using KITTI, VIPER as well as the Synscapes dataset and show that it outperforms current state-of-the-art NMS.

Oliver Mothes, Joachim Denzler:
One-Shot Learned Priors in Augmented Active Appearance Models for Anatomical Landmark Tracking.
Computer Vision, Imaging and Computer Graphics -- Theory and Applications.
Pages 85-104.
2019.
[bibtex]
[web]
[doi]
[abstract]
In motion science, biology and robotics animal movement analyses are used for the detailed understanding of the human bipedal locomotion. For this investigations an immense amount of recorded image data has to be evaluated by biological experts. During this time-consuming evaluation single anatomical landmarks, for example bone ends, have to be located and annotated in each image. In this paper we show a reduction of this effort by automating the annotation with a minimum level of user interaction. Recent approaches, based on Active Appearance Models, are improved by priors based on anatomical knowledge and an online tracking method, requiring only a single labeled frame. In contrast, we propose a one-shot learned tracking-by-detection prior which overcomes the shortcomings of template drifts without increasing the number of training data. We evaluate our approach based on a variety of real-world X-ray locomotion datasets and show that our method outperforms recent state-of-the-art concepts for the task at hand.

Oliver Mothes, Joachim Denzler:
Self-supervised Data Bootstrapping for Deep Optical Character Recognition of Identity Documents.
arXiv preprint arXiv:1908.04027.
2019.
[bibtex]
[pdf]
[abstract]
The essential task of verifying person identities at airports and national borders is very time-consuming. To accelerate it, optical character recognition for identity documents (IDs) using dictionaries is not appropriate due to the high variability of the text content in IDs, e.g., individual street names or surnames. Additionally, no properties of the used fonts in IDs are known. Therefore, we propose an iterative self-supervised bootstrapping approach using a smart strategy to mine real character data from IDs. In combination with synthetically generated character data, the real data is used to train efficient convolutional neural networks for character classification serving a practical runtime as well as a high accuracy. On a dataset with 74 character classes, we achieve an average class-wise accuracy of 99.4%. In contrast, if we would apply a classifier trained only using synthetic data, the accuracy is reduced to 58.1%. Finally, we show that our whole proposed pipeline outperforms an established open-source framework.
Stefan Hoffmann, Clemens-Alexander Brust, Maha Shadaydeh, Joachim Denzler:
Registration of High Resolution Sar and Optical Satellite Imagery Using Fully Convolutional Networks.
International Geoscience and Remote Sensing Symposium (IGARSS).
Pages 5152-5155.
2019.
[bibtex]
[pdf]
[doi]
[abstract]
Multi-modal image registration is a crucial step when fusing images which show different physical/chemical properties of an object. Depending on the compared modalities and the used registration metric, this process exhibits varying reliability. We propose a deep metric based on a fully convo-lutional neural network (FCN). It is trained from scratch on SAR-optical image pairs to predict whether certain image areas are aligned or not. Tests on the affine registration of SAR and optical images showing suburban areas verify an enormous improvement of the registration accuracy in comparison to registration metrics that are based on mutual information (MI).
Violeta Teodora Trifunov, Maha Shadaydeh, Jakob Runge, Veronika Eyring, Markus Reichstein, Joachim Denzler:
Causal Link Estimation under Hidden Confounding in Ecological Time Series.
International Workshop on Climate Informatics (CI).
2019.
[bibtex]
[pdf]
[abstract]
Understanding the causes of natural phe- nomena is a subject of continuous interest in many research fields such as climate and environmental science. We address the problem of recovering nonlinear causal relationships between time series of ecological variables in the presence of a hidden confounder. We suggest a deep learning approach with domain knowledge integration based on the Causal Effect Variational Autoencoder (CEVAE) which we extend and apply to ecological time series. We compare our method’s performance to that of vector autoregressive Granger Causality (VAR-GC) to emphasize its benefits.

Violeta Teodora Trifunov, Maha Shadaydeh, Jakob Runge, Veronika Eyring, Markus Reichstein, Joachim Denzler:
Nonlinear Causal Link Estimation under Hidden Confounding with an Application to Time-Series Anomaly Detection.
DAGM German Conference on Pattern Recognition (DAGM-GCPR).
Pages 261-273.
2019.
[bibtex]
[pdf]
[doi]
[abstract]
Causality analysis represents one of the most important tasks when examining dynamical systems such as ecological time series. We propose to mitigate the problem of inferring nonlinear cause-effect de- pendencies in the presence of a hidden confounder by using deep learning with domain knowledge integration. Moreover, we suggest a time series anomaly detection approach using causal link intensity increase as an indicator of the anomaly. Our proposed method is based on the Causal Effect Variational Autoencoder (CEVAE) which we extend and apply to anomaly detection in time series. We evaluate our method on synthetic data having properties of ecological time series and compare to the vector autoregressive Granger causality (VAR-GC) baseline.
Waldemar Jarisa, Roman Henze, Ferit Kücükay, Felix Schneider, Joachim Denzler, Bernd Hartmann:
Fusionskonzept zur Reibwertschätzung auf Basis von Wetter- und Fahrbahnzustandsinformationen.
VDI-Fachtagung Reifen - Fahrwerk - Fahrbahn.
2019.
Best Paper Award
[bibtex]
[abstract]
Die Fahrsicherheit ist ein zentrales Entwicklungsziel in der Automobilindustrie, welches mit dem automatisierten Fahren vor neuen Herausforderungen steht. Um die Fahrsicherheit zu gewährleisten, bedarf es einer genauen Kenntnis der unmittelbaren Fahrumgebung. Die Fahrumgebung setzt sich dabei aus mehreren Komponenten zusammen. Neben der Straßentopologie und den Verkehrsteilnehmern kommt der Kenntnis über den Fahrbahnzustand, in Form von trockenen, nassen oder schnee- und eisbedeckten Straßen, eine große Bedeutung zu. Im Rahmen dieser Arbeit werden in Kooperation mit der Friedrich-Schiller-Universität Jena und beauftragt durch die Continental AG Fusionskonzepte zur Fahrbahnzustandsklassifikation entwickelt, welche den Fahrbahnzustand, respektive den Reibwert, innerhalb der Gruppen trocken, nass und winterlich differenzieren. Grundlage für die Modellentwicklung sind Messdaten einer Messkampagne (ca. 6455 km) auf realen Straßen bei unterschiedlichsten Straßenzuständen und Witterungsbedingungen mit einem Versuchsträger des Instituts für Fahrzeugtechnik. Dieser ist in der Lage, auf unterschiedlichen Informationsebenen, bestehend aus digitalen Wetterkarten, Umfelddaten, Kamera- und Fahrdynamikinformationen sowie optional auch Laserdaten, den Fahrbahnzustand zu klassifizieren. Dabei wird jeweils ein Klassifikationsalgorithmus auf Basis der Frontkamera- als auch der Surround-View-Kamerabilder im rechten Außenspiegel verwendet. Die aufgezeichneten Signale werden mit einander fusioniert, um einerseits die Verfügbarkeit und andererseits die Genauigkeit der Fahrbahnzustandsklassifikation zu gewährleisten. Hierzu werden die Möglichkeiten zur frühen Fusion von Kamerabildern unter Berücksichtigung von Kontextwissen, wie z. B. Luft- oder Fahrbahntemperatur mittels Deep-Learning-Ansätzen untersucht. Abschließend wird der Zusammenhang zwischen dem tatsächlichen Fahrbahnzustand und einer maximalen Kraftschlussausnutzung anhand einer repräsentativen Anzahl von ABS-Bremsungen evaluiert.

Xavier-Andoni Tibau, Christian Reimers, Veronika Eyring, Joachim Denzler, Markus Reichstein, Jakob Runge:
Toy models to analyze emergent constraint approaches.
European Geosciences Union General Assembly (EGU): Abstract + Poster Presentation.
2019.
[bibtex]
[pdf]
[web]
[abstract]
Climate projections are limited by the arising uncertainties associated with not well-known physical processes in climate change. In every new generation, climate models improve several aspects of projections, while others remain in the same uncertainty range, especially those regarding equilibrium climate sensitivity (ECS) and climate feedbacks. Emergent constraints, defined as a 'physically explainable empirical relationships between characteristics of the current climate and long-term climate prediction that emerge in collections of climate model simulations' [1], is a promising novel approach that can shed light on climate change uncertainties and improve climate models. Since the first emergent constraint was proposed to constrain the Surface Albedo Feedback in 2006 by Hall & Qu [2], several of them have been proposed for constraining feedbacks and uncertainties of climate models, e.g., ECS, low-level cloud optical depth or tropical primary production. Emergent constraints have already been a prolific approach to improve our climate models. The typical approach to identify emergent constraints comes from expert knowledge when this is used to explore climate data and select those emergent constraints that are physically explainable. Caldwell et al. [3] presented a work where a new approach was suggested. In that paper, they attempt to identify quantities in the current climate which are skillful predictors of ECS yet can be constrained by observations. One of the main conclusions of this work was that the development of data mining methods for identifying emergent constraints should be aware of spurious emergent relations that could arise by chance. This becomes especially relevant in the next phase of the CMIP Project (6th). In the present work, we discuss simple spatiotemporal climate ("toy") models to analyze and evaluate methodologies to identify predictors for emergent constraints. Such models are simple enough to be analyzed not only empirically but also analytically, and at the same time incorporate relevant aspects of the complexity of a nonlinear dynamical spatiotemporal system. Consequently, they can be used to study assumptions and pitfalls of data mining methods for emergent constraints and guide the development of future approaches. [1]: Klein, S. A., & Hall, A. (2015). Emergent constraints for cloud feedbacks. Current Climate Change Reports, 1(4), 276-287. [2]: Hall, A., & Qu, X. (2006). Using the current seasonal cycle to constrain snow albedo feedback in future climate change. Geophysical Research Letters, 33(3). [3]: Caldwell, P. M., Bretherton, C. S., Zelinka, M. D., Klein, S. A., Santer, B. D., & Sanderson, B. M. (2014). Statistical significance of climate sensitivity predictors obtained by data mining. Geophysical Research Letters, 41(5), 1803-1808.

Yanira Guanche, Maha Shadaydeh, Miguel Mahecha, Joachim Denzler:
Attribution of Multivariate Extreme Events.
International Workshop on Climate Informatics (CI).
2019.
[bibtex]
[pdf]
[abstract]
The detection of multivariate extreme events is crucial to monitor the Earth system and to analyze their impacts on ecosystems and society. Once an abnormal event is detected, the following natural question is: what is causing this anomaly? Answering this question we try to understand these anomalies, to explain why they happened. In a previous work, the authors presented a multivariate anomaly detection approach based on the combination of a vector autoregressive model and the Mahalanobis distance metric. In this paper, we present an approach for the attribution of the detected anomalous events based on the decomposition of the Mahalanobis distance. The decomposed form of this metric provides an answer to the question: how much does each variable contribute to this distance metric? The method is applied to the extreme events detected in the land-atmosphere exchange fluxes: Gross Primary Productivity, Latent Energy, Net Ecosystem Exchange, Sensible Heat and Terrestrial Ecosystem Respiration. The attribution results of the proposed method for different known historic events are presented and compared with the univariate Z-score attribution method.
Andreas Dittberner, Sven Sickert, Joachim Denzler, Orlando Guntinas-Lichius, Thomas Bitter, Sven Koscielny:
Development of an Automatic Image Analysis Method by Deep Learning Methods for the Detection of Head and Neck Cancer Based on Standard Real-Time Near-Infrared ICG Fluorescence Endoscopy Images (NIR-ICG-FE).
Laryngo-Rhino-Otologie.
97 (S02) :
pp. 97.
2018.
[bibtex]
[web]
[doi]
[abstract]
Improving the gold standard in the diagnosis of head and neck cancer using white light and invasive biopsy with digital image recognition procedures, there is a need for a development of new technologies. In the sense of an "optical biopsy", they in vivo and online should provide additional objective information for decision making for the head and neck surgeon. Artificial neural networks in combination with machine learning might be a helpful and fast approach.
Björn Barz, Joachim Denzler:
Automatic Query Image Disambiguation for Content-Based Image Retrieval.
International Conference on Computer Vision Theory and Applications (VISAPP).
Pages 249-256.
2018.
[bibtex]
[pdf]
[doi]
[code]
[abstract]
Query images presented to content-based image retrieval systems often have various different interpretations, making it difficult to identify the search objective pursued by the user. We propose a technique for overcoming this ambiguity, while keeping the amount of required user interaction at a minimum. To achieve this, the neighborhood of the query image is divided into coherent clusters from which the user may choose the relevant ones. A novel feedback integration technique is then employed to re-rank the entire database with regard to both the user feedback and the original query. We evaluate our approach on the publicly available MIRFLICKR-25K dataset, where it leads to a relative improvement of average precision by 23% over the baseline retrieval, which does not distinguish between different image senses.

Björn Barz, Joachim Denzler:
Deep Learning is not a Matter of Depth but of Good Training.
International Conference on Pattern Recognition and Artificial Intelligence (ICPRAI).
Pages 683-687.
2018.
[bibtex]
[pdf]
[abstract]
In the past few years, deep neural networks have often been claimed to provide greater representational power than shallow networks. In this work, we propose a wide, shallow, and strictly sequential network architecture without any residual connections. When trained with cyclical learning rate schedules, this simple network achieves a classification accuracy on CIFAR-100 competitive to a 10 times deeper residual network, while it can be trained 4 times faster. This provides evidence that neither depth nor residual connections are crucial for deep learning. Instead, residual connections just seem to facilitate training using plain SGD by avoiding bad local minima. We believe that our work can hence point the research community to the actual bottleneck of contemporary deep learning: the optimization algorithms.

Björn Barz, Kai Schröter, Moritz Münch, Bin Yang, Andrea Unger, Doris Dransch, Joachim Denzler:
Enhancing Flood Impact Analysis using Interactive Retrieval of Social Media Images.
Archives of Data Science, Series A.
5 (1) :
pp. A06, 21 S. online.
2018.
[bibtex]
[pdf]
[doi]
[abstract]
The analysis of natural disasters such as floods in a timely manner often suffers from limited data due to a coarse distribution of sensors or sensor failures. This limitation could be alleviated by leveraging information contained in images of the event posted on social media platforms, so-called "Volunteered Geographic Information (VGI)". To save the analyst from the need to inspect all images posted online manually, we propose to use content-based image retrieval with the possibility of relevance feedback for retrieving only relevant images of the event to be analyzed. To evaluate this approach, we introduce a new dataset of 3,710 flood images, annotated by domain experts regarding their relevance with respect to three tasks (determining the flooded area, inundation depth, water pollution). We compare several image features and relevance feedback methods on that dataset, mixed with 97,085 distractor images, and are able to improve the precision among the top 100 retrieval results from 55% with the baseline retrieval to 87% after 5 rounds of feedback.
Björn Barz, Thomas C. van Dijk, Bert Spaan, Joachim Denzler:
Putting User Reputation on the Map: Unsupervised Quality Control for Crowdsourced Historical Data.
2nd ACM SIGSPATIAL Workshop on Geospatial Humanities.
Pages 3:1-3:6.
2018.
[bibtex]
[pdf]
[doi]
[abstract]
In this paper we propose a novel method for quality assessment of crowdsourced data. It computes user reputation scores without requiring ground truth; instead, it is based on the consistency among users. In this pilot study, we perform some explorative data analysis on two real crowdsourcing projects by the New York Public Library: extracting building footprints as polygons from historical insurance atlases, and geolocating historical photographs. We show that the computed reputation scores are plausible and furthermore provide insight into user behavior.

Christoph Käding, Erik Rodner, Alexander Freytag, Oliver Mothes, Björn Barz, Joachim Denzler:
Active Learning for Regression Tasks with Expected Model Output Changes.
British Machine Vision Conference (BMVC).
2018.
[bibtex]
[pdf]
[code]
[supplementary]
[abstract]
Annotated training data is the enabler for supervised learning. While recording data at large scale is possible in some application domains, collecting reliable annotations is time-consuming, costly, and often a project's bottleneck. Active learning aims at reducing the annotation effort. While this field has been studied extensively for classification tasks, it has received less attention for regression problems although the annotation cost is often even higher. We aim at closing this gap and propose an active learning approach to enable regression applications. To address continuous outputs, we build on Gaussian process models -- an established tool to tackle even non-linear regression problems. For active learning, we extend the expected model output change (EMOC) framework to continuous label spaces and show that the involved marginalizations can be solved in closed-form. This mitigates one of the major drawbacks of the EMOC principle. We empirically analyze our approach in a variety of application scenarios. In summary, we observe that our approach can efficiently guide the annotation process and leads to better models in shorter time and at lower costs.

Christoph Theiß, Clemens-Alexander Brust, Joachim Denzler:
Dataless Black-Box Model Comparison.
Pattern Recognition and Image Analysis. Advances in Mathematical Theory and Applications (PRIA).
28 (4) :
pp. 676-683.
2018.
(also published at ICPRAI 2018)
[bibtex]
[doi]
[abstract]
In a time where the training of new machine learning models is extremely time-consuming and resource-intensive and the sale of these models or the access to them is more popular than ever, it is important to think about ways to ensure the protection of these models against theft. In this paper, we present a method for estimating the similarity or distance between two black-box models. Our approach does not depend on the knowledge about specific training data and therefore may be used to identify copies of or stolen machine learning models. It can also be applied to detect instances of license violations regarding the use of datasets. We validate our proposed method empirically on the CIFAR-10 and MNIST datasets using convolutional neural networks, generative adversarial networks and support vector machines. We show that it can clearly distinguish between models trained on different datasets. Theoretical foundations of our work are also given.

Dimitri Korsch, Joachim Denzler:
In Defense of Active Part Selection for Fine-Grained Classification.
Pattern Recognition and Image Analysis. Advances in Mathematical Theory and Applications (PRIA).
28 (4) :
pp. 658-663.
2018.
[bibtex]
[pdf]
[web]
[doi]
[abstract]
Fine-grained classification is a recognition task where subtle differences distinguish between different classes. To tackle this classification problem, part-based classification methods are mostly used. Part-based methods learn an algorithm to detect parts of the observed object and extract local part features for the detected part regions. In this paper we show that not all extracted part features are always useful for the classification. Furthermore, given a part selection algorithm that actively selects parts for the classification we estimate the upper bound for the fine-grained recognition performance. This upper bound lies way above the current state- of-the-art recognition performances which shows the need for such an active part selection method. Though we do not present such an active part selection algorithm in this work, we propose a novel method that is required by active part selection and enables sequential part- based classification. This method uses a support vector machine (SVM) ensemble and allows to classify an image based on arbitrary number of part features. Additionally, the training time of our method does not increase with the amount of possible part features. This fact allows to extend the SVM ensemble with an active part selection component that operates on a large amount of part feature proposals without suffering from increasing training time.
Joachim Denzler, Christoph Käding, Clemens-Alexander Brust:
Keeping the Human in the Loop: Towards Automatic Visual Monitoring in Biodiversity Research.
International Conference on Ecological Informatics (ICEI).
Pages 16.
2018.
[bibtex]
[doi]
[abstract]
More and more methods in the area of biodiversity research grounds upon new opportunities arising from modern sensing devices that in principle make it possible to continuously record sensor data from the environment. However, these opportunities allow easy recording of huge amount of data, while its evaluation is difficult, if not impossible due to the enormous effort of manual inspection by the researchers. At the same time, we observe impressive results in computer vision and machine learning that are based on two major developments: firstly, the increased performance of hardware together with the advent of powerful graphical processing units applied in scientific computing. Secondly, the huge amount of, in part, annotated image data provided by today's generation of Facebook and Twitter users that are available easily over databases (e.g., Flickr) and/or search engines. However, for biodiversity applications appropriate data bases of annotated images are still missing. In this presentation we discuss already available methods from computer vision and machine learning together with upcoming challenges in automatic monitoring in biodiversity research. We argue that the key element towards success of any automatic method is the possibility to keep the human in the loop - either for correcting errors and improving the system's quality over time, for providing annotation data at moderate effort, or for acceptance and validation reasons. Thus, we summarize already existing techniques from active and life-long learning together with the enormous developments in automatic visual recognition during the past years. In addition, to allow detection of the unexpected such an automatic system must be capable to find anomalies or novel events in the data. We discuss a generic framework for automatic monitoring in biodiversity research which is the result of collaboration between computer scientists and ecologists of the past years. The key ingredients of such a framework are initial, generic classifier, for example, powerful deep learning architectures, active learning to reduce costly annotation effort by experts, fine-grained recognition to differentiate between visually very similar species, and efficient incremental update of the classifier's model over time. For most of these challenges, we present initial solutions in sample applications. The results comprise the automatic evaluation of images from camera traps, attribute estimation for species, as well as monitoring in-situ data in environmental science. Overall, we like to demonstrate the potentials and open issues in bringing together computer scientists and ecologist to open new research directions for either area.

Maha Shadaydeh, Yanira Guanche Garcia, Joachim Denzler:
Classification of Spatiotemporal Marine Climate Patterns using Wavelet Coherence and Markov Random Field.
American Geophysical Union Fall Meeting (AGU): Abstract + Oral Presentation.
2018.
[bibtex]
[web]
[abstract]
Sea condition characterization and classification is a widely studied topic but rather challenging one due to the spatial and temporal variability in marine climate. The aim of this study is to develop a data-driven method for the classification of marine climate patterns. The proposed method consists of two main steps: i) Feature extraction applied to the time series of each point of the grid independently. ii) Spatiotemporal classification applied on the obtained features over the entire study area. The causal intensity between coupled marine variables can be efficiently visualized at different time-scales using wavelet coherence. To this end, we extract a set of features from the statistically significant wavelet coherence of each pair of the used marine variables: significant wave height (hs), mean wave period (Tm), and wave direction (θm). The obtained features, in addition to the sea level pressure (SLP), over the entire study area are then treated as multi-channel images. For the spatiotemporal classification of these images, we first apply the unsupervised K-means clustering method on the images of each three consecutive time instances. The K clusters represent K different marine climate patterns. Markov Random Fields (MRFs) provide an effective methodology for integrating spatiotemporal dependency between adjacent points into the image classification process. In this study, we use a MRF model for defining the spatiotemporal extent of the detected marine climate patterns, with the statistics of the detected K clusters used for the initial training. Experimental results show that the proposed method allows for a practical classification of marine climate into representative patterns that can be used for an accurate characterization of sea conditions, the analysis of extreme events and its impacts along the coast. A case study in the North Sea will be presented using the coasDat dataset [1]. [1] Weisse, R., H. v. Storch, U. Callies, A. Chrastansky, F. Feser, I. Grabemann, H. Guenther, A. Pluess, Th. Stoye, J. Tellkamp, J. Winterfeldt and K. Woth, (2008): Regional meteo-marine reanalyses and climate change projections: Results for Northern Europe and potentials for coastal and offshore applications. Bull. Amer. Meteor. Soc., 90, 849-860.

Maha Shadaydeh, Yanira Guanche Garcia, Miguel Mahecha, Markus Reichstein, Joachim Denzler:
Analyzing the Time Variant Causality in Ecological Time Series: A Time-Frequency Approach.
International Conference on Ecological Informatics (ICEI).
Pages 151-152.
2018.
[bibtex]
[abstract]
Attribution in ecosystems aims to identify the cause-effect relationships between the variables involved. The availability of high temporal resolution data along with the powerful computing platforms further enhance the capacity of data-driven methods in capturing the complex relationships between the variables of the underlying system. Time series of ecological variables most often contain different periodical components that can significantly mask the underling causality structure in time domain. This motivates the use of time-frequency processing techniques such as wavelet analysis or short time Fourier transform. In this study we present a time-frequency approach for causality analysis where the coupling between the variables is assumed to follow a locally time-invariant multivariate autoregressive (MVAR) model. We propose a sliding time window approach to examine the change of interactions, i.e. direction and strength of causality, between the different variables over seasons. The cause-effect relationships are extracted using the frequency domain representation of the MVAR Granger causality (MVAR-GC) [1,2] based on the generalized partial directed coherence (gPDC) [3]. We have first applied the proposed method to synthetic data to evaluate its sensitivity to different issues such as the selection of the model order, the sampling frequency, the absence of cause as well as the presence of non-linear coupling. The method is then applied to half-hourly meteorological observations and land flux eddy covariance data to investigate the causal-effect relationships between global radiation (Rg), air temperature (Tair), and the CO2 land fluxes: gross primary productivity (GPP), net ecosystem exchange (NEE) and ecosystem respiration (Reco). The results show that time-frequency analysis based on MVAR-GC has promising potential in identifying the time variant causality structure within these variables along with the main time delay between different cause- effect pairs. Further research work is currently going for the investigation of the selection criteria of the model order, the sampling frequency, and the size of the time window at different time scales of causality analysis. This study is carried out within the framework of the project BACI which in part aims at developing an attribution scheme for changes in ecosystem functioning and studying the impacts of these changes on biodiversity patterns.

Matthias Körschens, Björn Barz, Joachim Denzler:
Towards Automatic Identification of Elephants in the Wild.
AI for Wildlife Conservation Workshop (AIWC).
2018.
[bibtex]
[pdf]
[abstract]
Identifying animals from a large group of possible individuals is very important for biodiversity monitoring and especially for collecting data on a small number of particularly interesting individuals, as these have to be identified first before this can be done. Identifying them can be a very time-consuming task. This is especially true, if the animals look very similar and have only a small number of distinctive features, like elephants do. In most cases the animals stay at one place only for a short period of time during which the animal needs to be identified for knowing whether it is important to collect new data on it. For this reason, a system supporting the researchers in identifying elephants to speed up this process would be of great benefit. In this paper, we present such a system for identifying elephants in the face of a large number of individuals with only few training images per individual. For that purpose, we combine object part localization, off-the-shelf CNN features, and support vector machine classification to provide field researches with proposals of possible individuals given new images of an elephant. The performance of our system is demonstrated on a dataset comprising a total of 2078 images of 276 individual elephants, where we achieve 56% top-1 test accuracy and 80% top-10 accuracy. To deal with occlusion, varying viewpoints, and different poses present in the dataset, we furthermore enable the analysts to provide the system with multiple images of the same elephant to be identified and aggregate confidence values generated by the classifier. With that, our system achieves a top-1 accuracy of 74% and a top-10 accuracy of 88% on the held-out test dataset.
Niclas Schmitt, Sven Sickert, Orlando Guntinas-Lichius, Thomas Bitter, Joachim Denzler:
Automated MRI Volumetry of the Olfactory Bulb.
Laryngo-Rhino-Otologie.
97 (S02) :
pp. 36.
2018.
[bibtex]
[web]
[doi]
[abstract]
The olfactory bulb (OB) as part of the olfactory pathway plays a central role in odor perception. Several studies have already established a connection between an olfactory impairment and the occurrence of neurodegenerative diseases (Parkinson's disease, Alzheimer's disease, etc.). This impairment is often detectable years before further symptoms. Moreover, it is connected to a volume loss of the OB. Therefore, in future the volume of the OB could contribute as a marker for detection and diagnosis of such diseases. Despite this great importance, there is currently no standard procedure for the volumetric analysis of the OB and above all no objective investigator-independent measurement methods.

Talha Qaiser, Abhik Mukherjee, Chaitanya Reddy PB, Sai D Munugoti, Vamsi Tallam, Tomi Pitkäaho, Taina Lehtimäki, Thomas Naughton, Matt Berseth, Anibal Pedraza, Ramakrishnan Mukundan, Matthew Smith, Abhir Bhalerao, Erik Rodner, Marcel Simon, Joachim Denzler, Chao-Hui Huang, Gloria Bueno, David Snead, Ian O Ellis, Mohammad Ilyas, Nasir Rajpoot:
HER2 challenge contest: a detailed assessment of automated HER2 scoring algorithms in whole slide images of breast cancer tissues.
Histopathology.
72 (2) :
pp. 227-238.
2018.
[bibtex]
[web]
[doi]
[abstract]
Aims Evaluating expression of the human epidermal growth factor receptor 2 (HER2) by visual examination of immunohistochemistry (IHC) on invasive breast cancer (BCa) is a key part of the diagnostic assessment of BCa due to its recognized importance as a predictive and prognostic marker in clinical practice. However, visual scoring of HER2 is subjective, and consequently prone to interobserver variability. Given the prognostic and therapeutic implications of HER2 scoring, a more objective method is required. In this paper, we report on a recent automated HER2 scoring contest, held in conjunction with the annual PathSoc meeting held in Nottingham in June 2016, aimed at systematically comparing and advancing the state-of-the-art artificial intelligence (AI)-based automated methods for HER2 scoring. Methods and results The contest data set comprised digitized whole slide images (WSI) of sections from 86 cases of invasive breast carcinoma stained with both haematoxylin and eosin (H&E) and IHC for HER2. The contesting algorithms predicted scores of the IHC slides automatically for an unseen subset of the data set and the predicted scores were compared with the 'ground truth' (a consensus score from at least two experts). We also report on a simple 'Man versus Machine' contest for the scoring of HER2 and show that the automated methods could beat the pathology experts on this contest data set. Conclusions This paper presents a benchmark for comparing the performance of automated algorithms for scoring of HER2. It also demonstrates the enormous potential of automated algorithms in assisting the pathologist with objective IHC scoring.

Violeta Teodora Trifunov, Maha Shadaydeh, Jakob Runge, Veronika Eyring, Markus Reichstein, Joachim Denzler:
Domain knowledge integration for causality analysis of carbon-cycle variables.
American Geophysical Union Fall Meeting (AGU): Abstract + Poster Presentation.
2018.
[bibtex]
[web]
[abstract]
Climate data has been vastly accumulated over the past several years, making climate science one of the most data-rich domains. Despite the abundance of data to process, data science has not had a lot of impact on climate research so far, due to the fact that ample expert knowledge is rarely exploited. Furthermore, the complex nature and the continuously changing climate system both contribute to the slow data science advances in the field. This issue was shown to be amend- able through the development of data-driven methodologies that are guided by theory to constrain search, discover more meaningful patterns, and produce more accurate models [1]. Causality analysis represents one of the most important tasks in climate research, its principal difficulties being the often found non-linearities in the data, in addition to hidden causes of the observed phenomena. We propose to ameliorate the problem of determining causal-effect dependencies to a certain extent by using deep learning methods together with domain knowledge integration. The suggested method is to be based on the causal effect variational auto-encoders (CEVAE) [2] and applied to half-hourly meteorological observations and land flux eddy covariance data. This will allow for exploration of the causal-effect relationships between air temperature (Tair), global radiation (Rg) and the CO2 fluxes gross primary productivity (GPP), net ecosystem exchange (NEE) and ecosystem respiration (Reco). The aim of this study is to show whether prior domain knowledge could aid discovery of new causal relationships between certain carbon-cycle variables. In addition, the proposed method is presumed to find its application to similar problems, such as those related to CO2 concentration estimation and facilitate efforts towards better understanding of the Earth system.
Xavier-Andoni Tibau, Christian Requena-Mesa, Christian Reimers, Joachim Denzler, Veronika Eyring, Markus Reichstein, Jakob Runge:
SupernoVAE: Using deep learning to find spatio-temporal dynamics in Earth system data.
American Geophysical Union Fall Meeting (AGU): Abstract + Poster Presentation.
2018.
[bibtex]
[web]
[abstract]
Exploring and understanding spatio-temporal patterns on Earth system datasets is one of the principal goals of the climate and geo-science communities. In this direction, Empirical Orthogonal Functions (EOFs) have been used to characterize phenomena such as the El Nino Southern Oscillation, the Arctic jet stream or the Indian Monsoon. However, EOF analysis has several limitations, for example, it can only identify linear and orthogonal patterns. We present a framework that makes use of a convolutional variational autoencoder (VAE) as a learnable feature function to extract spatio-temporal dynamics via PCA. The VAE encodes the information in an abstract space of higher order features representing different patterns. Over this space, PCA is performed to obtain a spatial representation of related temporal dynamics. We have used three datasets, two artificial datasets where the dynamics are ruled by a hidden spatially varying parameter and an observational reanalysis dataset of monthly sea surface temperature from 1898 to 2014. The artificial datasets have chaotic and, chaotic and stochastic dynamics depending on the spatial hidden parameter. As baseline methods, EOF analysis and Kernel PCA were performed over the original spaces. For the two artificial datasets, we found a high correlation between some of the first Principal Components on the feature space and the spatial hidden parameter. This correlation was not found using baseline methods in the original space. In the reanalysis dataset, the method was able to find known modes, such as ENSO, as well as other patterns that baseline methods did not reveal that might have inmmediate effect on how we understand the earth system after expert interpretation. These results provide a proof of concept: SupernoVAE is not only able to extract well-known climate patterns previously characterized with linear EOF analysis, but also allows to extract non-linear and non-orthogonal patterns that can help in analyzing Earth system dynamics that could not be characterized before.

Xavier-Andoni Tibau, Christian Requena-Mesa, Christian Reimers, Joachim Denzler, Veronika Eyring, Markus Reichstein, Jakob Runge:
SupernoVAE: VAE based Kernel-PCA for Analysis of Spatio-Temporal Earth Data.
International Workshop on Climate Informatics (CI).
Pages 73-76.
2018.
[bibtex]
[web]
[doi]
[abstract]
It is a constant challenge to better understand the underlying dynamics and forces driving the Earth system. Advances in the field of deep learning allow for unprecedented results, but use of these methods in Earth system science is still very limited. We present a framework that makes use of a convolutional variational autoencoder as a learnable kernel from which to extract spatio-temporal dynamics via PCA. The method promises the ability of deep learning to digest highly complex spatio-temporal datasets while allowing expert interpretability. Preliminary results over two artificial datasets, with chaotic and stochastic temporal dynamics, show that the method can recover a latent driver parameter while baseline approaches cannot. While further testing on the limitations of the method is needed and experiments on real Earth datasets are in order, the present approach may contribute to further the understanding of Earth datasets that are highly non-linear.

Yanira Guanche Garcia, Maha Shadaydeh, Miguel Mahecha, Joachim Denzler:
Extreme anomaly event detection in biosphere using linear regression and a spatiotemporal MRF model.
Natural Hazards.
pp. 1-19.
2018.
[bibtex]
[pdf]
[web]
[doi]
[abstract]
Detecting abnormal events within time series is crucial for analyzing and understanding the dynamics of the system in many research areas. In this paper, we propose a methodology to detect these anomalies in multivariate environmental data. Five biosphere variables from a preliminary version of the Earth System Data Cube have been used in this study: Gross Primary Productivity, Latent Energy, Net Ecosystem Exchange, Sensible Heat and Terrestrial Ecosystem Respiration. To tackle the spatiotemporal dependencies of the biosphere variables, the proposed methodology after preprocessing the data is divided into two steps: a feature extraction step applied to each time series in the grid independently, followed by a spatiotemporal event detection step applied to the obtained novelty scores over the entire study area. The first step is based on the assumption that the time series of each variable can be represented by an autoregressive moving average (ARMA) process, and the anomalies are those time instances that are not well represented by the estimated ARMA model. The Mahalanobis distance of the ARMA models’ multivariate residuals is used as a novelty score. In the second step, the obtained novelty scores of the entire study are treated as time series of images. Markov random fields (MRFs) provide an effective and theoretically well-established methodology for integrating spatiotemporal dependency into the classification of image time series. In this study, the classification of the novelty score images into three classes, intense anomaly, possible anomaly, and normal, is performed using unsupervised K-means clustering followed by multi-temporal MRF segmentation applied recursively on the images of each consecutive \(L \ge \) 1 time steps. The proposed methodology was applied to an area covering Europe and Africa. Experimental results and validation based on known historic events show that the method is able to detect historic events and also provides a useful tool to define sensitive regions.

Alexander Schultheiss, Christoph Käding, Alexander Freytag, Joachim Denzler:
Finding the Unknown: Novelty Detection with Extreme Value Signatures of Deep Neural Activations.
DAGM German Conference on Pattern Recognition (DAGM-GCPR).
Pages 226-238.
2017.
[bibtex]
[pdf]
[supplementary]
[abstract]
Achieving or even surpassing human-level accuracy became recently possible in a variety of application scenarios due to the rise of convolutional neural networks (CNNs) trained from large datasets. However, solving supervised visual recognition tasks by discriminating among known categories is only one side of the coin. In contrast to this, novelty detection is still an unsolved task where instances of yet unknown categories need to be identified. Therefore, we propose to leverage the powerful discriminative nature of CNNs to novelty detection tasks by investigating class-specific activation patterns. More precisely, we assume that a semantic category can be described by its extreme value signature, that specifies which dimensions of deep neural activations have largest values. By following this intuition, we show that already a small number of high-valued dimensions allows to separate known from unknown categories. Our approach is simple, intuitive, and can be easily put on top of CNNs trained for vanilla classification tasks. We empirically validate the benefits of our approach in terms of accuracy and speed by comparing it against established methods in a variety of novelty detection tasks derived from ImageNet. Finally, we show that visualizing extreme value signatures allows to inspect class-specific patterns learned during training which may ultimately help to better understand CNN models.

Ali Al-Raziqi, Joachim Denzler:
Unsupervised Group Activity Detection by Hierarchical Dirichlet Processes.
International Conference on Image Analysis and Recognition (ICIAR).
Pages 399-407.
2017.
[bibtex]
[pdf]
[web]
[doi]
[abstract]
Detecting groups plays an important role for group activity detection. In this paper, we propose an automatic group activity detection by segmenting the video sequences automatically into dynamic clips. As the first step, groups are detected by adopting a bottom-up hierarchical clustering, where the number of groups is not provided beforehand. Then, groups are tracked over time to generate consistent trajectories. Furthermore, the Granger causality is used to compute the mutual effect between objects based on motion and appearances features. Finally, the Hierarchical Dirichlet Process is used to cluster the groups. Our approach not only detects the activity among the objects of a particular group (intra-group) but also extracts the activities among multiple groups (inter-group). The experiments on public datasets demonstrate the effectiveness of the proposed method. Although our approach is completely unsupervised, we achieved results with a clustering accuracy of up to 79.35 \% and up to 81.94\% on the Behave and the NUS-HGA datasets.
Björn Barz, Yanira Guanche, Erik Rodner, Joachim Denzler:
Maximally Divergent Intervals for Extreme Weather Event Detection.
MTS/IEEE OCEANS Conference Aberdeen.
Pages 1-9.
2017.
[bibtex]
[pdf]
[doi]
[abstract]
We approach the task of detecting anomalous or extreme events in multivariate spatio-temporal climate data using an unsupervised machine learning algorithm for detection of anomalous intervals in time-series. In contrast to many existing algorithms for outlier and anomaly detection, our method does not search for point-wise anomalies, but for contiguous anomalous intervals. We demonstrate the suitability of our approach through numerous experiments on climate data, including detection of hurricanes, North Sea storms, and low-pressure fields.
Clemens-Alexander Brust, Christoph Käding, Joachim Denzler:
You Have To Look More Than Once: Active and Continuous Exploration using YOLO.
CVPR Workshop on Continuous and Open-Set Learning (CVPR-WS).
2017.
Extended Abstract + Poster Presentation
[bibtex]
[abstract]
Traditionally, most research in the area of object detection builds on models trained once on reliable labeled data for a predefined application. However, in many application scenarios, new data becomes available over time or the distribution underlying the problem changes itself. In this case, models are usually retrained from scratch or refined via fine-tuning or incremental learning. For most applications, acquiring new labels is the limiting factor in terms of effort or costs. Active learning aims to minimize the labeling effort by selecting only valuable samples for annotation. It is widely studied in classification tasks, where different measures of uncertainty are the most common choice for selection. We combine the deep object detector YOLO with active learning and an incremental learning scheme to build an object detection system suitable for active and continuous exploration and open-set problems by querying whole images for annotation rather than single proposals.

Clemens-Alexander Brust, Tilo Burghardt, Milou Groenenberg, Christoph Käding, Hjalmar Kühl, Marie Manguette, Joachim Denzler:
Towards Automated Visual Monitoring of Individual Gorillas in the Wild.
ICCV Workshop on Visual Wildlife Monitoring (ICCV-WS).
Pages 2820-2830.
2017.
[bibtex]
[pdf]
[doi]
[abstract]
In this paper we report on the context and evaluation of a system for an automatic interpretation of sightings of individual western lowland gorillas (Gorilla gorilla gorilla) as captured in facial field photography in the wild. This effort aligns with a growing need for effective and integrated monitoring approaches for assessing the status of biodiversity at high spatio-temporal scales. Manual field photography and the utilisation of autonomous camera traps have already transformed the way ecological surveys are conducted. In principle, many environments can now be monitored continuously, and with a higher spatio-temporal resolution than ever before. Yet, the manual effort required to process photographic data to derive relevant information delimits any large scale application of this methodology. The described system applies existing computer vision techniques including deep convolutional neural networks to cover the tasks of detection and localisation, as well as individual identification of gorillas in a practically relevant setup. We evaluate the approach on a relatively large and challenging data corpus of 12,765 field images of 147 individual gorillas with image-level labels (i.e. missing bounding boxes) photographed at Mbeli Bai at the Nouabal-Ndoki National Park, Republic of Congo. Results indicate a facial detection rate of 90.8% AP and an individual identification accuracy for ranking within the Top 5 set of 80.3%. We conclude that, whilst keeping the human in the loop is critical, this result is practically relevant as it exemplifies model transferability and has the potential to assist manual identification efforts. We argue further that there is significant need towards integrating computer vision deeper into ecological sampling methodologies and field practice to move the discipline forward and open up new research horizons.
Cornelia Dittmar, Joachim Denzler, Horst-Michael Gross:
A Feedback Estimation Approach for Therapeutic Facial Training.
IEEE International Conference on Automatic Face and Gesture Recognition (FG).
Pages 141-148.
2017.
[bibtex]
[abstract]
Neuromuscular retraining is an important part of facial paralysis rehabilitation. To date, few publications have addressed the development of automated systems that support facial training. Current approaches require external devices attached to the patient’s face, lack quantitative feedback, and are constrained to one or two facial training exercises. We propose an automated camera-based training system that provides global and local feedback for 12 different facial training exercises. Based on extracted 3D facial features, the patient’s performance is evaluated and quantitative feedback is derived. The description of the feedback estimation is supplemented by a detailed experimental evaluation of the 3D feature extraction.

Erik Rodner, Alexander Freytag, Paul Bodesheim, Björn Fröhlich, Joachim Denzler:
Large-Scale Gaussian Process Inference with Generalized Histogram Intersection Kernels for Visual Recognition Tasks.
International Journal of Computer Vision (IJCV).
121 (2) :
pp. 253-280.
2017.
[bibtex]
[pdf]
[web]
[doi]
[abstract]
We present new methods for fast Gaussian process (GP) inference in large-scale scenarios including exact multi-class classification with label regression, hyperparameter optimization, and uncertainty prediction. In contrast to previous approaches, we use a full Gaussian process model without sparse approximation techniques. Our methods are based on exploiting generalized histogram intersection kernels and their fast kernel multiplications. We empirically validate the suitability of our techniques in a wide range of scenarios with tens of thousands of examples. Whereas plain GP models are intractable due to both memory consumption and computation time in these settings, our results show that exact inference can indeed be done efficiently. In consequence, we enable every important piece of the Gaussian process framework - learning, inference, hyperparameter optimization, variance estimation, and online learning - to be used in realistic scenarios with more than a handful of data.

Milan Flach, Fabian Gans, Alexander Brenning, Joachim Denzler, Markus Reichstein, Erik Rodner, Sebastian Bathiany, Paul Bodesheim, Yanira Guanche, Sebasitan Sippel, Miguel D. Mahecha:
Multivariate anomaly detection for Earth observations: a comparison of algorithms and feature extraction techniques.
Earth System Dynamics.
8 (3) :
pp. 677-696.
2017.
[bibtex]
[pdf]
[web]
[doi]
[abstract]
Today, many processes at the Earth's surface are constantly monitored by multiple data streams. These observations have become central to advancing our understanding of vegetation dynamics in response to climate or land use change. Another set of important applications is monitoring effects of extreme climatic events, other disturbances such as fires, or abrupt land transitions. One important methodological question is how to reliably detect anomalies in an automated and generic way within multivariate data streams, which typically vary seasonally and are interconnected across variables. Although many algorithms have been proposed for detecting anomalies in multivariate data, only a few have been investigated in the context of Earth system science applications. In this study, we systematically combine and compare feature extraction and anomaly detection algorithms for detecting anomalous events. Our aim is to identify suitable workflows for automatically detecting anomalous patterns in multivariate Earth system data streams. We rely on artificial data that mimic typical properties and anomalies in multivariate spatiotemporal Earth observations like sudden changes in basic characteristics of time series such as the sample mean, the variance, changes in the cycle amplitude, and trends. This artificial experiment is needed as there is no "gold standard" for the identification of anomalies in real Earth observations. Our results show that a well-chosen feature extraction step (e.g., subtracting seasonal cycles, or dimensionality reduction) is more important than the choice of a particular anomaly detection algorithm. Nevertheless, we identify three detection algorithms (k-nearest neighbors mean distance, kernel density estimation, a recurrence approach) and their combinations (ensembles) that outperform other multivariate approaches as well as univariate extreme-event detection methods. Our results therefore provide an effective workflow to automatically detect anomalies in Earth system science data.

Rebecca Anna Schaede, Gerd F. Volk, Luise Modersohn, Jodie M. Barth, Joachim Denzler, Orlando Guntinas-Lichius:
Video Instruction for Synchronous Video Recording of Mimic Movement of Patients with Facial Palsy.
Laryngo-Rhino-Otologie.
2017.
[bibtex]
[web]
[doi]
[abstract]
Background: Photography and video are necessary to record the severity of a facial palsy or to allow offline grading with a grading system. There is no international standard for the video recording urgently needed to allow a standardized comparison of different patient cohorts. Methods: A video instruction was developed. The instruction was shown to the patient and presents several mimic movements. At the same time the patient is recorded while repeating the presented movement using commercial hardware. Facial movements were selected in such a way that it was afterwards possible to evaluate the recordings with standard grading systems (House-Brackmann, Sunnybrook, Stennert, Yanagihara) or even with (semi)automatic software. For quality control, the patients evaluated the instruction using a questionnaire. Results: The video instruction takes 11 min and 05 and is divided in three parts: 1) Explanation of the procedure; 2) Foreplay and recreating of the facial movements; 3) Repeating of sentences to analyze the communication skills. So far 13 healthy subjects and 10 patients with acute or chronic facial palsy were recorded. All recordings could be assessed by the above mentioned grading systems. The instruction was rated as well explaining and easy to follow by healthy persons and patients. Discussion: There is now a video instruction available for standardized recording of facial movement. This instruction is recommended for use in clinical routine and in clinical trials. This will allow a standardized comparison of patients within Germany and international patient cohorts.
Sven Sickert, Joachim Denzler:
Semantic Segmentation of Outdoor Areas using 3D Moment Invariants and Contextual Cues.
DAGM German Conference on Pattern Recognition (DAGM-GCPR).
Pages 165-176.
2017.
[bibtex]
[pdf]
[doi]
[abstract]
In this paper, we propose an approach for the semantic segmentation of a 3D point cloud using local 3D moment invariants and the integration of contextual information. Specifically, we focus on the task of analyzing forestal and urban areas which were recorded by terrestrial LiDAR scanners. We demonstrate how 3D moment invariants can be leveraged as local features and that they are on a par with established descriptors. Furthermore, we show how an iterative learning scheme can increase the overall quality by taking neighborhood relationships between classes into account. Our experiments show that the approach achieves very good results for a variety of tasks including both binary and multi-class settings.

Thomas Wenzel, Steffen Brueggert, Joachim Denzler:
Towards Unconstrained Content Recognition of Additional Traffic Signs.
IEEE Intelligent Vehicles Symposium (IV).
Pages 1421-1427.
2017.
[bibtex]
[web]
[doi]
[abstract]
The task of traffic sign recognition is often considered to be solved after almost perfect results have been achieved on some public benchmarks. Yet, the closely related recognition of additional traffic signs is still lacking a solution. Following up on our earlier work on detecting additional traffic signs given a main sign detection [1], we here propose a complete pipeline for recognizing the content of additional signs, including text recognition by optical character recognition (OCR). We assume a given additional sign detection, first classify its layout, then determine content bounding boxes by regression, followed by a multi-class classification step or, if necessary, OCR by applying a text sequence classifier. We evaluate the individual stages of our proposed pipeline and the complete system on a database of German additional signs and show that it can successfully recognize about 80% of the signs correctly, even under very difficult conditions and despite low input resolutions at runtimes well below 12ms per sign.

Thomas Wenzel, Ta-Wei Chou, Steffen Brueggert, Joachim Denzler:
From Corners To Rectangles — Directional Road Sign Detection Using Learned Corner Representations.
IEEE Intelligent Vehicles Symposium (IV).
Pages 1039-1044.
2017.
[bibtex]
[web]
[doi]
[abstract]
In this work we adopt a novel approach for the detection of rectangular directional road signs in single frames captured from a moving car. These signs exhibit wide variations in sizes and aspect ratios and may contain arbitrary information, thus making their detection a challenging task with applications in traffic sign recognition systems and vision-based localization. Our proposed approach was originally presented for additional traffic sign detection in small image regions and is generalized to full image frames in this work. Sign corner areas are detected by four ACF-detectors (Aggregated Channel Features) on a single scale. The resulting corner detections are subsequently used to generate quadrangle hypotheses, followed by an aggressive pruning strategy. A comparative evaluation on a database of 1500 German road signs shows that our proposed detector outperforms other methods significantly at close to real-time runtimes and yields thrice the very low error-rate of the recent MS-CNN framework while being two orders of magnitude faster.
Alexander Freytag, Erik Rodner, Marcel Simon, Alexander Loos, Hjalmar Kühl, Joachim Denzler:
Chimpanzee Faces in the Wild: Log-Euclidean CNNs for Predicting Identities and Attributes of Primates.
DAGM German Conference on Pattern Recognition (DAGM-GCPR).
Pages 51-63.
2016.
[bibtex]
[pdf]
[web]
[doi]
[supplementary]
[abstract]
In this paper, we investigate how to predict attributes of chimpanzees such as identity, age, age group, and gender. We build on convolutional neural networks, which lead to significantly superior results compared with previous state-of-the-art on hand-crafted recognition pipelines. In addition, we show how to further increase discrimination abilities of CNN activations by the Log-Euclidean framework on top of bilinear pooling. We finally introduce two curated datasets consisting of chimpanzee faces with detailed meta-information to stimulate further research. Our results can serve as the foundation for automated large-scale animal monitoring and analysis.

Ali Al-Raziqi, Joachim Denzler:
Unsupervised Framework for Interactions Modeling between Multiple Objects.
International Conference on Computer Vision Theory and Applications (VISAPP).
Pages 509-516.
2016.
[bibtex]
[pdf]
[abstract]
Extracting compound interactions involving multiple objects is a challenging task in computer vision due to different issues such as the mutual occlusions between objects, the varying group size and issues raised from the tracker. Additionally, the single activities are uncommon compared with the activities that are performed by two or more objects e.g. gathering, fighting, running, etc. The purpose of this paper is to address the problem of interaction recognition among multiple objects based on dynamic features in an unsupervised manner. Our main contribution is twofold. First, a combined framework using a tracking-by-detection framework for trajectory extraction and HDPs for latent interaction extraction is introduced. Another important contribution of this work is the introduction of a new dataset (the Cavy dataset). The Cavy dataset contains about six dominant interactions performed several times by two or three cavies at different locations. The cavies are interacting in complicated and unexpected ways, which leads to perform many interactions in a short time. This makes working on this dataset more challenging. The experiments in this study are not only performed on the Cavy dataset but to enrich the evaluation of our framework; we also use the benchmark dataset Behave. The experiments on these datasets demonstrate the effectiveness of the proposed method. Although the fact that our approach is completely unsupervised, we achieved satisfactory results with a clustering accuracy of up to 68.84\% on the Behave dataset and up to 45\% on Cavy dataset. Keywords: Interaction Detection, Multiple Object Tracking, Unsupervised Clustering, Hierarchical Dirichlet Processes.

Ali Al-Raziqi, Mahesh Venkata Krishna, Joachim Denzler:
Detection of Dog-Robot Interactions in Video Sequences.
Pattern Recognition and Image Analysis. Advances in Mathematical Theory and Applications (PRIA).
26 (1) :
pp. 46-54.
2016.
[bibtex]
[pdf]
[abstract]
In this paper, we propose a novel framework for unsupervised detection of object interactions in video sequences based on dynamic features. The goal of our system is to process videos in an unsupervised manner using Hierarchical Bayesian Topic Models, specifically the Hierarchical Dirichlet Processes (HDP). We investigate how low-level features such as optical flow combined with Hierarchical Dirichlet Process (HDP) can help to recognize meaningful interactions between objects in the scene, for example, in videos of animal interaction recordings, kicking ball, standing, moving around etc. The underlying hypothesis that we validate is that interactions in such scenarios are heavily characterized by their 2D spatio-temporal features. Various experiments have been performed on the challenging JAR-AIBO dataset and first promising results are reported.

Benjamin Dorschner, Herbert Süße, Wolfgang Ortmann, Andrey Irintchev, Joachim Denzler, Orlando Guntinas-Lichius:
An Automated Whisker Tracking Tool for the Rat Facial Nerve Injury Paradigm.
Journal of Neuroscience Methods.
271 :
pp. 143-148.
2016.
[bibtex]
[web]
[doi]
[abstract]
Background: The two-dimensional videographic analysis of vibrissal movements in behaving rodents has become a standard method to estimate the degree of functional impairment and recovery after facial nerve injuries quantitatively. The main limitation of the method is the time consuming, uneconomic process of manually tracking the vibrissae in video sequences. New method: We developed a novel tool allowing automated detection of untagged vibrissae (two on each side of the snout). To compare the new method with the standard manual tracking approach, we used videos of unrestrained rats with unilateral section and immediate suture of the facial nerve performed two months earlier. Results: Measurement agreement analyses showed that the two methods are equivalent for both normal? high-amplitude vibrissal movements (non-operated side) and low-amplitude whisking (reinnervated side). Spectral analysis revealed a significant deviation in the power spectra on the control and injured side, indicating that bilaterally coordinated whisker movements are not present two months after surgery. Comparison with existing method(s): The novel method yields results equal to those of the manual tracking approach. An advantage of our tool is the possibility to significantly increase sample size without additional labor cost. Conclusions The novel tool can increase the efficacy and spectrum of functional measures used in facial nerve regeneration research.

Christoph Käding, Alexander Freytag, Erik Rodner, Andrea Perino, Joachim Denzler:
Large-scale Active Learning with Approximated Expected Model Output Changes.
DAGM German Conference on Pattern Recognition (DAGM-GCPR).
Pages 179-191.
2016.
[bibtex]
[pdf]
[web]
[doi]
[code]
[supplementary]
[abstract]
Incremental learning of visual concepts is one step towards reaching human capabilities beyond closed-world assumptions. Besides recent progress, it remains one of the fundamental challenges in computer vision and machine learning. Along that path, techniques are needed which allow for actively selecting informative examples from a huge pool of unlabeled images to be annotated by application experts. Whereas a manifold of active learning techniques exists, they commonly suffer from one of two drawbacks: (i) either they do not work reliably on challenging real-world data or (ii) they are kernel-based and not scalable with the magnitudes of data current vision applications need to deal with. Therefore, we present an active learning and discovery approach which can deal with huge collections of unlabeled real-world data. Our approach is based on the expected model output change principle and overcomes previous scalability issues. We present experiments on the large-scale MS-COCO dataset and on a dataset provided by biodiversity researchers. Obtained results reveal that our technique clearly improves accuracy after just a few annotations. At the same time, it outperforms previous active learning approaches in academic and real-world scenarios.

Christoph Käding, Erik Rodner, Alexander Freytag, Joachim Denzler:
Active and Continuous Exploration with Deep Neural Networks and Expected Model Output Changes.
NIPS Workshop on Continual Learning and Deep Networks (NIPS-WS).
2016.
[bibtex]
[pdf]
[web]
[abstract]
The demands on visual recognition systems do not end with the complexity offered by current large-scale image datasets, such as ImageNet. In consequence, we need curious and continuously learning algorithms that actively acquire knowledge about semantic concepts which are present in available unlabeled data. As a step towards this goal, we show how to perform continuous active learning and exploration, where an algorithm actively selects relevant batches of unlabeled examples for annotation. These examples could either belong to already known or to yet undiscovered classes. Our algorithm is based on a new generalization of the Expected Model Output Change principle for deep architectures and is especially tailored to deep neural networks. Furthermore, we show easy-to-implement approximations that yield efficient techniques for active selection. Empirical experiments show that our method outperforms currently used heuristics.

Christoph Käding, Erik Rodner, Alexander Freytag, Joachim Denzler:
Fine-tuning Deep Neural Networks in Continuous Learning Scenarios.
ACCV Workshop on Interpretation and Visualization of Deep Neural Nets (ACCV-WS).
2016.
[bibtex]
[pdf]
[web]
[supplementary]
[abstract]
The revival of deep neural networks and the availability of ImageNet laid the foundation for recent success in highly complex recognition tasks. However, ImageNet does not cover all visual concepts of all possible application scenarios. Hence, application experts still record new data constantly and expect the data to be used upon its availability. In this paper, we follow this observation and apply the classical concept of fine-tuning deep neural networks to scenarios where data from known or completely new classes is continuously added. Besides a straightforward realization of continuous fine-tuning, we empirically analyze how computational burdens of training can be further reduced. Finally, we visualize how the networks attention maps evolve over time which allows for visually investigating what the network learned during continuous fine-tuning.
Christoph Käding, Erik Rodner, Alexander Freytag, Joachim Denzler:
Watch, Ask, Learn, and Improve: A Lifelong Learning Cycle for Visual Recognition.
European Symposium on Artificial Neural Networks (ESANN).
Pages 381-386.
2016.
[bibtex]
[pdf]
[code]
[presentation]
[abstract]
We present WALI, a prototypical system that learns object categories over time by continuously watching online videos. WALI actively asks questions to a human annotator about the visual content of observed video frames. Thereby, WALI is able to receive information about new categories and to simultaneously improve its generalization abilities. The functionality of WALI is driven by scalable active learning, efficient incremental learning, as well as state-of-the-art visual descriptors. In our experiments, we show qualitative and quantitative statistics about WALI's learning process. WALI runs continuously and regularly asks questions.
Clemens-Alexander Brust, Sven Sickert, Marcel Simon, Erik Rodner, Joachim Denzler:
Neither Quick Nor Proper -- Evaluation of QuickProp for Learning Deep Neural Networks.
2016.
Technical Report TR-FSU-INF-CV-2016-01
[bibtex]
[pdf]
[abstract]
Neural networks and especially convolutional neural networks are of great interest in current computer vision research. However, many techniques, extensions, and modifications have been published in the past, which are not yet used by current approaches. In this paper, we study the application of a method called QuickProp for training of deep neural networks. In particular, we apply QuickProp during learning and testing of fully convolutional networks for the task of semantic segmentation. We compare QuickProp empirically with gradient descent, which is the current standard method. Experiments suggest that QuickProp can not compete with standard gradient descent techniques for complex computer vision tasks like semantic segmentation.
Erik Rodner, Björn Barz, Yanira Guanche, Milan Flach, Miguel Mahecha, Paul Bodesheim, Markus Reichstein, Joachim Denzler:
Maximally Divergent Intervals for Anomaly Detection.
Workshop on Anomaly Detection (ICML-WS).
2016.
Best Paper Award
[bibtex]
[pdf]
[web]
[code]
[abstract]
We present new methods for batch anomaly detection in multivariate time series. Our methods are based on maximizing the Kullback-Leibler divergence between the data distribution within and outside an interval of the time series. An empirical analysis shows the benefits of our algorithms compared to methods that treat each time step independently from each other without optimizing with respect to all possible intervals.
Luise Modersohn, Joachim Denzler:
Facial Paresis Index Prediction by Exploiting Active Appearance Models for Compact Discriminative Features.
International Conference on Computer Vision Theory and Applications (VISAPP).
Pages 271-278.
2016.
[bibtex]
[pdf]
[abstract]
In the field of otorhinolaryngology, the dysfunction of the facial nerve is a common disease which results in a paresis of usually one half of the patients face. The grade of paralysis is measured by physicians with rating scales, e.g. the Stennert Index or the House-Brackmann scale. In this work, we propose a method to analyse and predict the severity of facial paresis on the basis of single images. We combine feature extraction methods based on a generative approach (Active Appearance Models) with a fast non-linear classifier (Random Decision Forests) in order to predict the patients grade of facial paresis. In our proposed framework, we make use of highly discriminative features based on the fitting parameters of the Active Appearance Model, Action Units and Landmark distances. We show in our experiments that it is possible to correctly predict the grade of facial paresis in many cases, although the visual appearance is strongly varying. The presented method creates new opportunities to objectively document the patients progress in therapy.
Marcel Simon, Erik Rodner, Joachim Denzler:
ImageNet pre-trained models with batch normalization.
arXiv preprint 1612.01452.
2016.
[bibtex]
[pdf]
[web]
[abstract]
Convolutional neural networks (CNN) pre-trained on ImageNet are the backbone of most state-of-the-art approaches. In this paper, we present a new set of pretrained models with popular state-of-the-art architectures for the Caffe framework. The first release includes Residual Networks (ResNets) with generation script as well as the batch-normalization-variants of AlexNet and VGG19. All models outperform previous models with the same architecture. The models and training code are available at http://www.inf-cv.uni-jena.de/Research/CNN+Models.html and https://github.com/cvjena/cnn-models.

Markus Reichstein, Martin Jung, Paul Bodesheim, Miguel D. Mahecha, Fabian Gans, Erik Rodner, Gustau Camps-Valls, Dario Papale, Gianluca Tramontana, Joachim Denzler, Dennis D. Baldocchi:
Potential of new machine learning methods for understanding long-term interannual variability of carbon and energy fluxes and states from site to global scale.
American Geophysical Union Fall Meeting (AGU): Abstract + Oral Presentation.
2016.
[bibtex]
[web]
[abstract]
Machine learning tools have been very successful in describing and predicting instantaneous climatic influences on the spatial and seasonal variability of biosphere-atmosphere exchange, while interannual variability is harder to model (e.g. Jung et al. 2011, JGR Biogeosciences). Here we hypothesize that innterannual variability is harder to describe for two reasons. 1) The signal-to-noise ratio in both, predictors (e.g. remote sensing) and target variables (e.g. net ecosystem exchange) is relatively weak, 2) The employed machine learning methods do not sufficiently account for dynamic lag and carry-over effects. In this presentation we can largely confirm both hypotheses: 1) We show that based on FLUXNET data and an ensemble of machine learning methods we can arrive at estimates of global NEE that correlate well with the residual land sink overall and CO2 flux inversions over latitudinal bands. Furthermore these results highlight the importance of variations in water availability for variations in carbon fluxes locally, while globally, as a scale-emergent property, tropical temperatures correlate well with the atmospheric CO2 growth rate, because of spatial anticorrelation and compensation of water availability. 2) We evidence with synthetic and real data that machine learning methods with embed dynamic memory effects of the system such as recurrent neural networks (RNNs) are able to better capture lag and carry-over effect which are caused by dynamic carbon pools in vegetation and soils. For these methods, long-term replicate observations are an essential asset.

Milan Flach, Miguel Mahecha, Fabian Gans, Erik Rodner, Paul Bodesheim, Yanira Guanche-Garcia, Alexander Brenning, Joachim Denzler, Markus Reichstein:
Using Statistical Process Control for detecting anomalies in multivariate spatiotemporal Earth Observations.
European Geosciences Union General Assembly (EGU): Abstract + Oral Presentation.
2016.
[bibtex]
[pdf]
[web]
[abstract]
The number of available Earth observations (EOs) is currently substantially increasing. Detecting anomalous pat-terns in these multivariate time series is an important step in identifying changes in the underlying dynamicalsystem. Likewise, data quality issues might result in anomalous multivariate data constellations and have to beidentified before corrupting subsequent analyses. In industrial application a common strategy is to monitor pro-duction chains with several sensors coupled to some statistical process control (SPC) algorithm. The basic ideais to raise an alarm when these sensor data depict some anomalous pattern according to the SPC, i.e. the produc-tion chain is considered ’out of control’. In fact, the industrial applications are conceptually similar to the on-linemonitoring of EOs. However, algorithms used in the context of SPC or process monitoring are rarely consideredfor supervising multivariate spatio-temporal Earth observations. The objective of this study is to exploit the poten-tial and transferability of SPC concepts to Earth system applications. We compare a range of different algorithmstypically applied by SPC systems and evaluate their capability to detect e.g. known extreme events in land sur-face processes. Specifically two main issues are addressed: (1) identifying the most suitable combination of datapre-processing and detection algorithm for a specific type of event and (2) analyzing the limits of the individual ap-proaches with respect to the magnitude, spatio-temporal size of the event as well as the data’s signal to noise ratio.Extensive artificial data sets that represent the typical properties of Earth observations are used in this study. Ourresults show that the majority of the algorithms used can be considered for the detection of multivariate spatiotem-poral events and directly transferred to real Earth observation data as currently assembled in different projectsat the European scale, e.g. http://baci-h2020.eu/index.php/ and http://earthsystemdatacube.net/. Known anomaliessuch as the Russian heatwave are detected as well as anomalies which are not detectable with univariate methods.

Milan Flach, Sebastian Sippel, Paul Bodesheim, Alexander Brenning, Joachim Denzler, Fabian Gans, Yanira Guanche, Markus Reichstein, Erik Rodner, Miguel D. Mahecha:
Hot spots of multivariate extreme anomalies in Earth observations.
American Geophysical Union Fall Meeting (AGU): Abstract + Oral Presentation.
2016.
[bibtex]
[web]
[abstract]
Anomalies in Earth observations might indicate data quality issues, extremes or the change of underlying processes within a highly multivariate system. Thus, considering the multivariate constellation of variables for extreme detection yields crucial additional information over conventional univariate approaches. We highlight areas in which multivariate extreme anomalies are more likely to occur, i.e. hot spots of extremes in global atmospheric Earth observations that impact the Biosphere. In addition, we present the year of the most unusual multivariate extreme between 2001 and 2013 and show that these coincide with well known high impact extremes. Technically speaking, we account for multivariate extremes by using three sophisticated algorithms adapted from computer science applications. Namely an ensemble of the k-nearest neighbours mean distance, a kernel density estimation and an approach based on recurrences is used. However, the impact of atmosphere extremes on the Biosphere might largely depend on what is considered to be normal, i.e. the shape of the mean seasonal cycle and its inter-annual variability. We identify regions with similar mean seasonality by means of dimensionality reduction in order to estimate in each region both the `normal' variance and robust thresholds for detecting the extremes. In addition, we account for challenges like heteroscedasticity in Northern latitudes. Apart from hot spot areas, those anomalies in the atmosphere time series are of particular interest, which can only be detected by a multivariate approach but not by a simple univariate approach. Such an anomalous constellation of atmosphere variables is of interest if it impacts the Biosphere. The multivariate constellation of such an anomalous part of a time series is shown in one case study indicating that multivariate anomaly detection can provide novel insights into Earth observations.

Sven Sickert, Erik Rodner, Joachim Denzler:
Semantic Volume Segmentation with Iterative Context Integration for Bio-medical Image Stacks.
Pattern Recognition and Image Analysis. Advances in Mathematical Theory and Applications (PRIA).
26 (1) :
pp. 197-204.
2016.
[bibtex]
[pdf]
[abstract]
Automatic recognition of biological structures like membranes or synapses is important to analyze organic processes and to understand their functional behavior. To achieve this, volumetric images taken by electron microscopy or computer tomography have to be segmented into meaningful semantic regions. We are extending iterative context forests which were developed for 2D image data to image stack segmentation. In particular, our method is able to learn high-order dependencies and import contextual information, which often can not be learned by conventional Markov random field approaches usually used for this task. Our method is tested on very different and challenging medical and biological segmentation tasks.
Thomas Wenzel, Steffen Brueggert, Joachim Denzler:
Additional Traffic Sign Detection Using Learned Corner Representations.
IEEE Intelligent Vehicles Symposium (IV).
Pages 316-321.
2016.
[bibtex]
[web]
[doi]
[abstract]
The detection of traffic signs and recognizing their meanings is crucial for applications such as online detection in automated driving or automated map data updates. Despite all progress in this field detecting and recognizing additional traffic signs, which may invalidate main traffic signs, has been widely disregarded in the scientific community. As a continuation of our earlier work we present a novel high-performing additional sign detector here, which outperforms our recently published state-of-the-art results significantly. Our approach relies on learning corner area representations using Aggregated Channel Features (ACF). Subsequently, a quadrangle generation and filtering strategy is applied, thus effectively dealing with the large aspect ratio variations of additional signs. It yields very high detection rates on a challenging dataset of high-resolution images captured with a windshield-mounted smartphone, and offers very precise localization while maintaining real-time capability. More than 95% of the additional traffic signs are detected successfully with full content detection at a false positive rate well below 0.1 per main sign, thus contributing a small step towards enabling automated driving.
Wolfgang Bothe, Harald Schubert, Mahmoud Diab, Gloria Faerber, Christoph Bettag, Xiaoyan Jiang, Martin S. Fischer, Joachim Denzler, Torsten Doenst:
Fully automated tracking of cardiac structures using radiopaque markers and high-frequency videofluoroscopy in an in vivo ovine model: from three-dimensional marker coordinates to quantitative analyses.
SpringerPlus.
5 (1) :
2016.
[bibtex]
[pdf]
[doi]
[abstract]
Purpose: Recently, algorithms were developed to track radiopaque markers in the heart fully automated. However, the methodology did not allow to assign the exact anatomical location to each marker. In this case study we describe the steps from the generation of three-dimensional marker coordinates to quantitative data analyses in an in vivo ovine model.Methods: In one adult sheep, twenty silver balls were sutured to the right side of the heart: 10 to the tricuspid annulus, one to the anterior tricuspid leaflet and nine to the epicardial surface of the right ventricle. In addition, 13 cylindrical tantalum markers were implanted into the left ventricle. Data were acquired with a biplanar X-ray acquisition system (Neurostar R, Siemens AG, 500 Hz). Radiopaque marker coordinates were determined fully automated using novel tracking algorithms.Results: The anatomical marker locations were identified using a 3-dimensional model of a single frame containing all tracked markers. First, cylindrical markers were manually separated from spherical markers, thus allowing to distinguish right from left heart markers. The fast moving leaflet marker was identified by using video loops constructed of all recorded frames. Rotation of the 3-dimensional model allowed the identification of the precise anatomical position for each marker. Data sets were then analyzed quantitatively using customized software.Conclusions: The method presented in this case study allowed quantitative data analyses of radiopaque cardiac markers that were tracked fully automated with high temporal resolution. However, marker identification still requires substantial manual work. Future improvements including the implication of marker identification algorithms and data analysis software could allow almost real-time quantitative analyses of distinct cardiac structures with high temporal and spatial resolution.
Yanira Guanche Garcia, Erik Rodner, Milan Flach, Sebastian Sippel, Miguel Mahecha, Joachim Denzler:
Detecting Multivariate Biosphere Extremes.
International Workshop on Climate Informatics (CI).
Pages 9-12.
2016.
[bibtex]
[web]
[doi]
[abstract]
The detection of anomalies in multivariate time series is crucial to identify changes in the ecosystems. We propose an intuitive methodology to assess the occurrence of tail events of multiple biosphere variables.
Yerania Campos, Erik Rodner, Joachim Denzler, Humberto Sossa, Gonzalo Pajares:
Vegetation segmentation in cornfield images using bag of words.
Advanced Concepts for Intelligent Vision Systems (Acivs).
Pages 193-204.
2016.
[bibtex]
[pdf]
[web]
[doi]
[abstract]
We provide an alternative methodology for vegetation segmentation in cornfield images. The process includes two main steps, which makes the main contribution of this approach: (a) a low-level segmentation and (b) a class label assignment using Bag of Words (BoW) representation in conjunction with a supervised learning framework. The experimental results show our proposal is adequate to extract green plants in images of maize fields. The accuracy for classification is 95.3 % which is comparable to values in current literature.

Alexander Freytag, Alena Schadt, Joachim Denzler:
Interactive Image Retrieval for Biodiversity Research.
DAGM German Conference on Pattern Recognition (DAGM-GCPR).
Pages 129-141.
2015.
[bibtex]
[pdf]
[abstract]
On a daily basis, experts in biodiversity research are confronted with the challenging task of classifying individuals to build statistics over their distributions, their habitats, or the overall biodiversity. While the number of species is vast, experts with affordable time-budgets are rare. Image retrieval approaches could greatly assist experts: when new images are captured, a list of visually similar and previously collected individuals could be returned for further comparison. Following this observation, we start by transferring latest image retrieval techniques to biodiversity scenarios. We then propose to additionally incorporate an expert's knowledge into this process by allowing him to select must-have-regions. The obtained annotations are used to train exemplar-models for region detection. Detection scores efficiently computed with convolutions are finally fused with an initial ranking to reflect both sources of information, global and local aspects. The resulting approach received highly positive feedback from several application experts. On datasets for butterfly and bird identification, we quantitatively proof the benefit of including expert-feedback resulting in gains of accuracy up to 25% and we extensively discuss current limitations and further research directions.

Christoph Käding, Alexander Freytag, Erik Rodner, Paul Bodesheim, Joachim Denzler:
Active Learning and Discovery of Object Categories in the Presence of Unnameable Instances.
IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
Pages 4343-4352.
2015.
[bibtex]
[pdf]
[web]
[doi]
[code]
[presentation]
[supplementary]
[abstract]
Current visual recognition algorithms are "hungry" for data but massive annotation is extremely costly. Therefore, active learning algorithms are required that reduce labeling efforts to a minimum by selecting examples that are most valuable for labeling. In active learning, all categories occurring in collected data are usually assumed to be known in advance and experts should be able to label every requested instance. But do these assumptions really hold in practice? Could you name all categories in every image? Existing algorithms completely ignore the fact that there are certain examples where an oracle can not provide an answer or which even do not belong to the current problem domain. Ideally, active learning techniques should be able to discover new classes and at the same time cope with queries an expert is not able or willing to label. To meet these observations, we present a variant of the expected model output change principle for active learning and discovery in the presence of unnameable instances. Our experiments show that in these realistic scenarios, our approach substantially outperforms previous active learning methods, which are often not even able to improve with respect to the baseline of random query selection.

Clemens-Alexander Brust, Sven Sickert, Marcel Simon, Erik Rodner, Joachim Denzler:
Convolutional Patch Networks with Spatial Prior for Road Detection and Urban Scene Understanding.
International Conference on Computer Vision Theory and Applications (VISAPP).
Pages 510-517.
2015.
[bibtex]
[pdf]
[doi]
[abstract]
Classifying single image patches is important in many different applications, such as road detection or scene understanding. In this paper, we present convolutional patch networks, which are convolutional networks learned to distinguish different image patches and which can be used for pixel-wise labeling. We also show how to incorporate spatial information of the patch as an input to the network, which allows for learning spatial priors for certain categories jointly with an appearance model. In particular, we focus on road detection and urban scene understanding, two application areas where we are able to achieve state-of-the-art results on the KITTI as well as on the LabelMeFacade dataset. Furthermore, our paper offers a guideline for people working in the area and desperately wandering through all the painstaking details that render training CNs on image patches extremely difficult.
Clemens-Alexander Brust, Sven Sickert, Marcel Simon, Erik Rodner, Joachim Denzler:
Efficient Convolutional Patch Networks for Scene Understanding.
CVPR Workshop on Scene Understanding (CVPR-WS).
2015.
Extended Abstract + Poster Presentation
[bibtex]
[pdf]
[abstract]
In this paper, we present convolutional patch networks, which are convolutional (neural) networks (CNN) learned to distinguish different image patches and which can be used for pixel-wise labeling. We show how to easily learn spatial priors for certain categories jointly with their appearance. Experiments for urban scene understanding demonstrate state-of-the-art results on the LabelMeFacade dataset. Our approach is implemented as a new CNN framework especially designed for semantic segmentation with fully-convolutional architectures.

Daniel Haase, Laura Minnigerode, Gerd F. Volk, Joachim Denzler, Orlando Guntinas-Lichius:
Automated and objective action coding of facial expressions in patients with acute facial palsy.
European Archives of Oto-Rhino-Laryngology.
272 (5) :
pp. 1259-1267.
2015.
[bibtex]
[web]
[doi]
[abstract]
Aim of the present observational single center study was to objectively assess facial function in patients with idiopathic facial palsy with a new computer-based system that automatically recognizes action units (AUs) defined by the Facial Action Coding System (FACS). Still photographs using posed facial expressions of 28 healthy subjects and of 299 patients with acute facial palsy were automatically analyzed for bilateral AU expression profiles. All palsies were graded with the House–Brackmann (HB) grading system and with the Stennert Index (SI). Changes of the AU profiles during follow-up were analyzed for 77 patients. The initial HB grading of all patients was 3.3 ± 1.2. SI at rest was 1.86 ± 1.3 and during motion 3.79 ± 4.3. Healthy subjects showed a significant AU asymmetry score of 21 ± 11 % and there was no significant difference to patients (p = 0.128). At initial examination of patients, the number of activated AUs was significantly lower on the paralyzed side than on the healthy side (p < 0.0001). The final examination for patients took place 4 ± 6 months post baseline. The number of activated AUs and the ratio between affected and healthy side increased significantly between baseline and final examination (both p < 0.0001). The asymmetry score decreased between baseline and final examination (p < 0.0001). The number of activated AUs on the healthy side did not change significantly (p = 0.779). Radical rethinking in facial grading is worthwhile: automated FACS delivers fast and objective global and regional data on facial motor function for use in clinical routine and clinical trials.

Emanuel Andrada, Daniel Haase, Yefta Sutedja, John A. Nyakatura, Brandon M. Kilbourne, Joachim Denzler, Martin S. Fischer, Reinhard Blickhan:
Mixed Gaits in Small Avian Terrestrial Locomotion.
Scientific Reports.
5 :
2015.
[bibtex]
[web]
[doi]
[abstract]
Scientists have historically categorized gaits discretely (e.g. regular gaits such as walking, running). However, previous results suggest that animals such as birds might mix or regularly or stochastically switch between gaits while maintaining a steady locomotor speed. Here, we combined a novel and completely automated large-scale study (over one million frames) on motions of the center of mass in several bird species (quail, oystercatcher, northern lapwing, pigeon, and avocet) with numerical simulations. The birds studied do not strictly prefer walking mechanics at lower speeds or running mechanics at higher speeds. Moreover, our results clearly display that the birds in our study employ mixed gaits (such as one step walking followed by one step using running mechanics) more often than walking and, surprisingly, maybe as often as grounded running. Using a bio-inspired model based on parameters obtained from real quails, we found two types of stable mixed gaits. In the first, both legs exhibit different gait mechanics, whereas in the second, legs gradually alternate from one gait mechanics into the other. Interestingly, mixed gaits parameters mostly overlap those of grounded running. Thus, perturbations or changes in the state induce a switch from grounded running to mixed gaits or vice versa.
Johannes Rühle, Erik Rodner, Joachim Denzler:
Beyond Thinking in Common Categories: Predicting Obstacle Vulnerability using Large Random Codebooks.
Machine Vision Applications (MVA).
Pages 198-201.
2015.
[bibtex]
[pdf]
[web]
[abstract]
Obstacle detection for advanced driver assistance systems has focused on building detectors for only a few number of categories so far, such as pedestrians and cars. However, vulnerable obstacles of other categories are often dismissed, such as wheel-chairs and baby strollers. In our work, we try to tackle this limitation by presenting an approach which is able to predict the vulnerability of an arbitrary obstacle independently from its category. This allows for using models not specifically tuned for category recognition. To classify the vulnerability, we apply a generic category-free approach based on large random bag-of-visual-words representations (BoW), where we make use of both the intensity image as well as a given disparity map. In experimental results, we achieve a classification accuracy of over 80% for predicting one of four vulnerability levels for each of the 10000 obstacle hypotheses detected in a challenging dataset of real urban street scenes. Vulnerability prediction in general and our working algorithm in particular, pave the way to more advanced reasoning in autonomous driving, emergency route planning, as well as reducing the false-positive rate of obstacle warning systems.

Manuel Amthor, Bernd Hartmann, Joachim Denzler:
Road Condition Estimation based on Spatio-Temporal Reflection Models.
DAGM German Conference on Pattern Recognition (DAGM-GCPR).
Pages 3-15.
2015.
[bibtex]
[pdf]
[abstract]
Automated road condition estimation is a crucial basis for Advanced Driver Assistance Systems (ADAS) and even more for highly and fully automated driving functions in future. In order to improve vehicle safety relevant vehicle dynamics parameters, e.g. last-point-to-brake (LPB), last-point-to-steer (LPS), or vehicle curve speed should be adapted depending on the current weather-related road surface conditions. As vision-based systems are already integrated in many of today’s vehicles they constitute a beneficial resource for such a task. As a first contribution, we present a novel approach for reflection modeling which is a reliable and robust indicator for wet road surface conditions. We then extend our method by texture description features since local structures enable for the distinction of snow-covered and bare road surfaces. Based on a large real-life dataset we evaluate the performance of our approach and achieve results which clearly outperform other established vision-based methods while ensuring real-time capability.
Marcel Simon, Erik Rodner, Joachim Denzler:
Fine-grained Classification of Identity Document Types with Only One Example.
Machine Vision Applications (MVA).
Pages 126-129.
2015.
[bibtex]
[pdf]
[web]
[abstract]
This paper shows how to recognize types of identity documents, such as passports, using state-of-the-art visual recognition approaches. Whereas recognizing individual parts on identity documents with a standardized layout is one of the old classics in computer vision, recognizing the type of the document and therefore also the layout is a challenging problem due to the large variation of the documents. In our paper, we evaluate different techniques for this application including feature representations based on recent achievements with convolutional neural networks.
Marco Körner, Mahesh Venkata Krishna, Herbert Süße, Wolfgang Ortmann, Joachim Denzler:
Regularized Geometric Hulls for Bio-medical Image Segmentation.
Annals of the BMVA.
pp. 1-12.
2015.
[bibtex]
[pdf]
[abstract]
One of the most important and challenging tasks in bio-medical image analysis is the localization, identification, and discrimination of salient objects or structures. While to date human experts are performing these tasks manually at the expense of time and reliability, methods for automation of these processes are evidently called for. This paper outlines a novel technique for geometric clustering of related object evidence called regularized geometric hulls (RGH) and gives three exemplary real-world application scenarios. Several experiments performed on real-world data highlight a set of useful advantages, such as robustness, reliability, as well as efficient runtime behavior.

Paul Bodesheim, Alexander Freytag, Erik Rodner, Joachim Denzler:
Local Novelty Detection in Multi-class Recognition Problems.
IEEE Winter Conference on Applications of Computer Vision (WACV).
Pages 813-820.
2015.
[bibtex]
[pdf]
[web]
[doi]
[supplementary]
[abstract]
In this paper, we propose using local learning for multiclass novelty detection, a framework that we call local novelty detection. Estimating the novelty of a new sample is an extremely challenging task due to the large variability of known object categories. The features used to judge on the novelty are often very specific for the object in the image and therefore we argue that individual novelty models for each test sample are important. Similar to human experts, it seems intuitive to first look for the most related images thus filtering out unrelated data. Afterwards, the system focuses on discovering similarities and differences to those images only. Therefore, we claim that it is beneficial to solely consider training images most similar to a test sample when deciding about its novelty. Following the principle of local learning, for each test sample a local novelty detection model is learned and evaluated. Our local novelty score turns out to be a valuable indicator for deciding whether the sample belongs to a known category from the training set or to a new, unseen one. With our local novelty detection approach, we achieve state-of-the-art performance in multi-class novelty detection on two popular visual object recognition datasets, Caltech-256 and Image Net. We further show that our framework: (i) can be successfully applied to unknown face detection using the Labeled-Faces-in-the-Wild dataset and (ii) outperforms recent work on attribute-based unfamiliar class detection in fine-grained recognition of bird species on the challenging CUB-200-2011 dataset.
Thomas Wenzel, Steffen Brueggert, Joachim Denzler:
Additional Traffic Sign Detection: A Comparative Study.
IEEE International Conference on Intelligent Transportation Systems (ITSC).
Pages 794-799.
2015.
[bibtex]
[pdf]
[doi]
[abstract]
Automated driving is a long term goal that currently generates a lot of interest and effort in the scientific community and the industry. A crucial step towards it is being able to read traffic signs along the roads. Unfortunately, state-of-the-art traffic sign detectors currently ignore the existence of additional traffic signs. Yet being able to recognize these is a requirement for the task of automated driving and automated map data updates, because they further determine the meaning or validity of main signs. In this paper we aim at the detection of these additional signs, a first step towards their recognition. We will have a careful look at suitable evaluation measures and then use these to compare our proposed MSER-based approach to a selection of five differing types of detectors from the literature. We achieved a substantial improvement of the state of the art with 90% successful detections with full sign content detection on a challenging dataset, while significantly reducing the number of false positives. We will present our database, which contains high-resolution images of German traffic signs suitable for optical character recognition. We rely on hand-labelled main signs to emphasize the focus on additional sign detection. Our results were confirmed on a validation set containing European additional signs.

Alexander Freytag, Erik Rodner, Joachim Denzler:
Selecting Influential Examples: Active Learning with Expected Model Output Changes.
European Conference on Computer Vision (ECCV).
Pages 562-577.
2014.
[bibtex]
[pdf]
[presentation]
[supplementary]
[abstract]
In this paper, we introduce a new general strategy for active learning. The key idea of our approach is to measure the expected change of model outputs, a concept that generalizes previous methods based on expected model change and incorporates the underlying data distribution. For each example of an unlabeled set, the expected change of model predictions is calculated and marginalized over the unknown label. This results in a score for each unlabeled example that can be used for active learning with a broad range of models and learning algorithms. In particular, we show how to derive very efficient active learning methods for Gaussian process regression, which implement this general strategy, and link them to previous methods. We analyze our algorithms and compare them to a broad range of previous active learning strategies in experiments showing that they outperform state-of-the-art on well-established benchmark datasets in the area of visual object recognition.

Alexander Freytag, Erik Rodner, Trevor Darrell, Joachim Denzler:
Exemplar-specific Patch Features for Fine-grained Recognition.
DAGM German Conference on Pattern Recognition (DAGM-GCPR).
Pages 144-156.
2014.
[bibtex]
[pdf]
[code]
[supplementary]
[abstract]
In this paper, we present a new approach for fine-grained recognition or subordinate categorization, tasks where an algorithm needs to reliably differentiate between visually similar categories, e.g. different bird species. While previous approaches aim at learning a single generic representation and models with increasing complexity, we propose an orthogonal approach that learns patch representations specifically tailored to every single test exemplar. Since we query a constant number of images similar to a given test image, we obtain very compact features and avoid large-scale training with all classes and examples. Our learned mid-level features are build on shape and color detectors estimated from discovered patches reflecting small highly discriminative structures in the queried images. We evaluate our approach for fine-grained recognition on the CUB-2011 birds dataset and show that high recognition rates can be obtained by model combination.

Alexander Freytag, Johannes Rühle, Paul Bodesheim, Erik Rodner, Joachim Denzler:
Seeing through bag-of-visual-word glasses: towards understanding quantization effects in feature extraction methods.
2014.
Technical Report TR-FSU-INF-CV-2014-01
[bibtex]
[pdf]
[code]
[abstract]
The bag-of-visual-word (BoW) model is one of the most common concepts for image categorization and feature extraction. Although our community developed powerful BoW approaches for visual recognition and it serves as a great ad-hoc solution, unfortunately, there are several drawbacks that most researchers might be not aware of. In this paper, we aim at seeing behind the curtains and point to some of the negative aspects of these approaches which go usually unnoticed: (i) although BoW approaches are often motivated by relating clusters to meaningful object parts, this relation does not hold in practice with low-dimensional features such as HOG, and standard clustering method, (ii) clusters can be chosen randomly without loss in performance, (iii) BoW is often only collecting background statistics, and (iv) cluster assignments are not robust to small spatial shifts. Furthermore, we show the effect of BoW quantization and the related loss of visual information by a simple inversion method called HoggleBoW.
Ali Al-Raziqi, Mahesh Venkata Krishna, Joachim Denzler:
Detection of Object Interactions in Video Sequences.
Open German-Russian Workshop on Pattern Recognition and Image Understanding (OGRW).
Pages 156-161.
2014.
[bibtex]
[pdf]
[web]
[abstract]
In this paper, we propose a novel framework for unsupervised detection of object interactions in video sequences based on dynamic features. The goal of our system is to process videos in an unsupervised manner using Hierarchical Bayesian Topic Models, specifically the Hierarchical Dirichlet Processes (HDP). We investigate how low-level features such as optical flow combined with Hierarchical Dirichlet Process (HDP) can help to recognize meaningful interactions between objects in the scene, for example, in videos of animal activity recordings, kicking ball, standing, moving around etc. The underlying hypothesis that we validate is that interaction in such scenarios are heavily characterized by their 2D spatio-temporal features. Various experiments have been performed on the challenging JAR-AIBO dataset and first promising results are reported.
Björn Barz, Erik Rodner, Joachim Denzler:
ARTOS -- Adaptive Real-Time Object Detection System.
arXiv preprint arXiv:1407.2721.
2014.
[bibtex]
[pdf]
[web]
[code]
[abstract]
ARTOS is all about creating, tuning, and applying object detection models with just a few clicks. In particular, ARTOS facilitates learning of models for visual object detection by eliminating the burden of having to collect and annotate a large set of positive and negative samples manually and in addition it implements a fast learning technique to reduce the time needed for the learning step. A clean and friendly GUI guides the user through the process of model creation, adaptation of learned models to different domains using in-situ images, and object detection on both offline images and images from a video stream. A library written in C++ provides the main functionality of ARTOS with a C-style procedural interface, so that it can be easily integrated with any other project.

C. Beckstein, S. Böcker, M. Bogdan, H. Bruelheide H. M. Bücker, Joachim Denzler, P. Dittrich, I. Grosse, A. Hinneburg, B. König-Ries, F. Löffler, M. Marz, M. Müller-Hannemann, M. Winter, W. Zimmermann:
Explorative Analysis of Heterogeneous, Unstructured, and Uncertain Data: A Computer Science Perspective on Biodiversity Research.
International Conference on Data Management Technologies and Applications (DATA).
Pages 251-257.
2014.
[bibtex]
[abstract]
We outline a blueprint for the development of new computer science approaches for the management and analysis of big data problems for biodiversity science. Such problems are characterized by a combination of different data sources each of which owns at least one of the typical characteristics of big data (volume, variety, velocity, or veracity). For these problems, we envision a solution that covers different aspects of integrating data sources and algorithms for their analysis on one of the following three layers: At the data layer, there are various data archives of heterogeneous, unstructured, and uncertain data. At the functional layer, the data are analyzed for each archive individually. At the meta-layer, multiple functional archives are combined for complex analysis.

Christoph Göring, Erik Rodner, Alexander Freytag, Joachim Denzler:
Nonparametric Part Transfer for Fine-grained Recognition.
IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
Pages 2489-2496.
2014.
[bibtex]
[pdf]
[web]
[code]
[presentation]
[abstract]
In the following paper, we present an approach for fine-grained recognition based on a new part detection method. In particular, we propose a nonparametric label transfer technique which transfers part constellations from objects with similar global shapes. The possibility for transferring part annotations to unseen images allows for coping with a high degree of pose and view variations in scenarios where traditional detection models (such as deformable part models) fail. Our approach is especially valuable for fine-grained recognition scenarios where intraclass variations are extremely high, and precisely localized features need to be extracted. Furthermore, we show the importance of carefully designed visual extraction strategies, such as combination of complementary feature types and iterative image segmentation, and the resulting impact on the recognition performance. In experiments, our simple yet powerful approach achieves 35.9% and 57.8% accuracy on the CUB-2010 and 2011 bird datasets, which is the current best performance for these benchmarks.

Daniel Haase, Erik Rodner, Joachim Denzler:
Instance-weighted Transfer Learning of Active Appearance Models.
IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
Pages 1426-1433.
2014.
[bibtex]
[pdf]
[abstract]
There has been a lot of work on face modeling, analysis, and landmark detection, with Active Appearance Models being one of the most successful techniques. A major drawback of these models is the large number of detailed annotated training examples needed for learning. Therefore, we present a transfer learning method that is able to learn from related training data using an instance-weighted transfer technique. Our method is derived using a generalization of importance sampling and in contrast to previous work we explicitly try to tackle the transfer already during learning instead of adapting the fitting process. In our studied application of face landmark detection, we efficiently transfer facial expressions from other human individuals and are thus able to learn a precise face Active Appearance Model only from neutral faces of a single individual. Our approach is evaluated on two common face datasets and outperforms previous transfer methods.

Daniel Haase, John A. Nyakatura, Joachim Denzler:
Comparative Large-Scale Evaluation of Human and Active Appearance Model Based Tracking Performance of Anatomical Landmarks in X-ray Locomotion Sequences.
Pattern Recognition and Image Analysis. Advances in Mathematical Theory and Applications (PRIA).
24 (1) :
pp. 86-92.
2014.
[bibtex]
[web]
[abstract]
The detailed understanding of animal locomotion is an important part of biology, motion science and robotics. To analyze the motion, high-speed x-ray sequences of walking animals are recorded. The biological evaluation is based on anatomical key points in the images, and the goal is to find these landmarks automatically. Unfortunately, low contrast and occlusions in the images drastically complicate this task. As recently shown, Active Appearance Models (AAMs) can be successfully applied to this problem. However, obtaining reliable quantitative results is a tedious task, as the human error is unknown. In this work, we present the results of a large scale study which allows us to quantify both the tracking performance of humans as well as AAMs. Furthermore, we show that the AAM-based approach provides results which are comparable to those of human experts.

Johannes Rühle, Maxim Arbitmann, Joachim Denzler:
Vulnerability Classification of Generic Object Hypotheses using a Visual Words Approach.
FISITA World Automotive Congress (FISITA).
Pages 1-5.
2014.
F2014-AST-045
[bibtex]
[abstract]
We present a method based on image processing to evaluate the vulnerability of objects detected in front of a vehicle by means of a stereo camera. The evaluation is part of the current cooperate research project UR:BAN SVT, which is introduced and described in this paper. The project's main objective is to further increase road safety for vulnerable road users. The detection of potentially vulnerable real world objects is performed by a car build-in stereo camera that outputs object hypotheses as medium-level object representations. Given these generic object hypotheses, our method classifies an object's vulnerability that states the expected damage of a car collision from the object's perspective. This information about obstacle hypotheses enables a better static scene understanding and thereby can be used to plan actions for accident prevention and mitigation in emergency situations. Our approach focuses on employing a model-free classification pipeline using bags-of-visual words extracted in a completely unsupervised manner. The results show that the bag-of-visual-words approach is well-suited for evaluating the vulnerability of object hypotheses.

Mahesh Venkata Krishna, Joachim Denzler:
A Combination of Generative and Discriminative Models for Fast Unsupervised Activity Recognition from Traffic Scene Videos.
IEEE Winter Conference on Applications of Computer Vision (WACV).
Pages 640-645.
2014.
[bibtex]
[pdf]
[web]
[abstract]
Recent approaches in traffic and crowd scene analysis make extensive use of non-parametric hierarchical Bayesian models for intelligent clustering of features into activities. Although this has yielded impressive results, it requires the use of time consuming Bayesian inference during both training and classification. Therefore, we seek to limit Bayesian inference to the training stage, where unsupervised clustering is performed to extract semantically meaningful activities from the scene. In the testing stage, we use discriminative classifiers, taking advantage of their relative simplicity and fast inference. Experiments on publicly available data-sets show that our approach is comparable in classification accuracy to state-of-the-art methods and provides a significant speed-up in the testing phase.
Mahesh Venkata Krishna, Joachim Denzler:
A Hierarchical Bayesian Approach for Unsupervised Cell Phenotype Clustering.
DAGM German Conference on Pattern Recognition (DAGM-GCPR).
Pages 69-80.
2014.
[bibtex]
[pdf]
[abstract]
We propose a hierarchical Bayesian model - the wordless Hierarchical Dirichlet Processes-Hidden Markov Model (wHDP-HMM), to tackle the problem of unsupervised cell phenotype clustering during the mitosis stages. Our model combines the unsupervised clustering capabilities of the HDP model with the temporal modeling aspect of the HMM. Furthermore, to model cell phenotypes effectively, our model uses a variant of the HDP, giving preference to morphology over co-occurrence. This is then used to model individual cell phenotype time series and cluster them according to the stage of mitosis they are in. We evaluate our method using two publicly available time-lapse microscopy video data-sets and demonstrate that the performance of our approach is generally better than the state-of-the-art.

Mahesh Venkata Krishna, Paul Bodesheim, Marco Körner, Joachim Denzler:
Temporal Video Segmentation by Event Detection: A Novelty Detection Approach.
Pattern Recognition and Image Analysis. Advances in Mathematical Theory and Applications (PRIA).
24 (2) :
pp. 243-255.
2014.
[bibtex]
[pdf]
[web]
[doi]
[abstract]
Temporal segmentation of videos into meaningful image sequences containing some particular activities is an interesting problem in computer vision. We present a novel algorithm to achieve this semantic video segmentation. The segmentation task is accomplished through event detection in a frame-by-frame processing setup. We propose using one-class classification (OCC) techniques to detect events that indicate a new segment, since they have been proved to be successful in object classification and they allow for unsupervised event detection in a natural way. Various OCC schemes have been tested and compared, and additionally, an approach based on the temporal self-similarity maps (TSSMs) is also presented. The testing was done on a challenging publicly available thermal video dataset. The results are promising and show the suitability of our approaches for the task of temporal video segmentation.

Manuel Amthor, Daniel Haase, Joachim Denzler:
Robust Pictorial Structures for X-ray Animal Skeleton Tracking.
International Conference on Computer Vision Theory and Applications (VISAPP).
Pages 351-359.
2014.
[bibtex]
[pdf]
[abstract]
The detailed understanding of animals in locomotion is a relevant field of research in biology, biomechanics and robotics. To examine the locomotor system of birds in vivo and in a surgically non-invasive manner, high-speed X-ray acquisition is the state of the art. For a biological evaluation, it is crucial to locate relevant anatomical structures of the locomotor system. There is an urgent need for automating this task, as vast amounts of data exist and a manual annotation is extremely time-consuming. We present a biologically motivated skeleton model tracking framework based on a pictorial structure approach which is extended by robust sub-template matching. This combination makes it possible to deal with severe self-occlusions and challenging ambiguities. As opposed to model-driven methods which require a substantial amount of labeled training samples, our approach is entirely data-driven and can easily handle unseen cases. Thus, it is well suited for large scale biological applications at a minimum of manual interaction. We validate the performance of our approach based on 24 real-world X-ray locomotion datasets, and achieve results which are comparable to established methods while clearly outperforming more general approaches.

Marcel Simon, Erik Rodner, Joachim Denzler:
Part Detector Discovery in Deep Convolutional Neural Networks.
Asian Conference on Computer Vision (ACCV).
Pages 162-177.
2014.
[bibtex]
[pdf]
[code]
[abstract]
Current fine-grained classification approaches often rely on a robust localization of object parts to extract localized feature representations suitable for discrimination. However, part localization is a challenging task due to the large variation of appearance and pose. In this paper, we show how pre-trained convolutional neural networks can be used for robust and efficient object part discovery and localization without the necessity to actually train the network on the current dataset. Our approach called part detector discovery (PDD) is based on analyzing the gradient maps of the network outputs and finding activation centers spatially related to annotated semantic parts or bounding boxes. This allows us not just to obtain excellent performance on the CUB200-2011 dataset, but in contrast to previous approaches also to perform detection and bird classification jointly without requiring a given bounding box annotation during testing and ground-truth parts during training.
Sven Sickert, Erik Rodner, Joachim Denzler:
Semantic Volume Segmentation with Iterative Context Integration.
Open German-Russian Workshop on Pattern Recognition and Image Understanding (OGRW).
Pages 220-225.
2014.
[bibtex]
[pdf]
[web]
[abstract]
Automatic recognition of biological structures like membranes or synapses is important to analyze organic processes and to understand their functional behavior. To achieve this, volumetric images taken by electron microscopy or computed tomography have to be segmented into meaningful regions. We are extending iterative context forests which were developed for 2D image data for image stack segmentation. In particular, our method s able to learn high order dependencies and import contextual information, which often can not be learned by conventional Markov random field approaches usually used for this task. Our method is tested for very different and challenging medical and biological segmentation tasks.
Alexander Freytag, Erik Rodner, Paul Bodesheim, Joachim Denzler:
Labeling examples that matter: Relevance-Based Active Learning with Gaussian Processes.
DAGM German Conference on Pattern Recognition (DAGM-GCPR).
Pages 282-291.
2013.
[bibtex]
[pdf]
[web]
[doi]
[code]
[supplementary]
[abstract]
Active learning is an essential tool to reduce manual annotation costs in the presence of large amounts of unsupervised data. In this paper, we introduce new active learning methods based on measuring the impact of a new example on the current model. This is done by deriving model changes of Gaussian process models in closed form. Furthermore, we study typical pitfalls in active learning and show that our methods automatically balance between the exploitation and the exploration trade-off. Experiments are performed with established benchmark datasets for visual object recognition and show that our new active learning techniques are able to outperform state-of-the-art methods.

Andreas Breitbarth, Peter Kühmstedt, Gunther Notni, Joachim Denzler:
Lighting estimation in fringe images during motion compensation for 3D measurements.
Videometrics, Range Imaging, and Applications XII; and Automated Visual Inspection.
Pages 87910P:1-9.
2013.
[bibtex]
[pdf]
[web]
[abstract]
Fringe projection is an established method to measure the 3D structure of macroscopic objects. To receive both a high accuracy and robustness a certain number of images with pairwise different projection pattern is necessary. Over this sequence it is necessary that each 3D object point corresponds to the same image point at every time. This situation is no longer given for moving measurement objects. One possibility to solve this problem is to restore the static situation. Therefore, the acquired camera images have to be realigned and secondly the degree of fringe shift hast to be estimated. Furthermore, there exists another variable: change in lighting. These variances cannot be compensated, but it has to be approximately determined and integrated into the calculation process of 3D data. The possibility to obtain an accurate measurement is not being given because due to the condition that each arbitrary interferogram comprised three unknowns: additive and multiplicative intensity distortion and the phase distribution. The changes in lighting are described by the first two parameters and have to be determined for each camera pixel and each image. So, there is a trade-off problem: Two variables, but only one equation. We propose a method to estimate these lighting changes for each camera pixel with respect to their neighbors at each point in time. The size of local neighborhoods in the presented algorithms is chosen adaptively in respect to the gradients of object structure because for accurate 3D measurements you need both: sharp edges and on the other side smoothness in regions with very low contrast in intensities or wide fringe periods. To speed up the estimation of lighting values, not all pixel of the neighborhood were taken into account. Depending on the direction of projected fringes, either axially parallel or diagonal adjacent pixels are used. Taken together, our method results in a motion compensated dense 3D point cloud without any artifacts.
Mahesh Venkata Krishna, Marco Körner, Joachim Denzler:
Hierarchical Dirichlet Processes for unsupervised online multi-view action perception using Temporal Self-Similarity features.
Seventh International Conference on Distributed Smart Cameras (ICDSC).
Pages 1-6.
2013.
[bibtex]
[pdf]
[web]
[doi]
[abstract]
In various real-world applications of distributed and multi-view vision systems, ability to learn unseen actions in an online fashion is paramount, as most of the actions are not known or sufficient training data is not available at design time. We propose a novel approach which combines the unsupervised learning capabilities of Hierarchical Dirichlet Processes (HDP) with Temporal Self-Similarity Maps (SSM) representations, which have been shown to be suitable for aggregating multi-view information without further model knowledge. Furthermore, the HDP model, being almost completely data-driven, provides us with a system that works almost ``out-of-the-box''. Various experiments performed on the extensive JAR-Aibo dataset show promising results, with clustering accuracies up to 60\% for a 56-class problem.

Mahesh Venkata Krishna, Paul Bodesheim, Joachim Denzler:
Video Segmentation by Event Detection: A Novel One-class Classification Approach.
4th International Workshop on Image Mining. Theory and Applications (IMTA-4).
2013.
[bibtex]
[pdf]
[abstract]
Segmenting videos into meaningful image sequences of some particular activities is an interesting problem in computer vision. In this paper, a novelalgorithm is presented to achieve this semantic video segmentation. The goal is to make the system work unsupervised and generic in terms of application scenar-ios. The segmentation task is accomplished through event detection in a frame-by-frame processing setup. For event detection, we use a one-class classificationapproach based on Gaussian processes, which has been proved to be successful in object classification. The algorithm is tested on videos from a publicly avail-able change detection database and the results clearly show the suitability of our approach for the task of video segmentation.

Paul Bodesheim, Alexander Freytag, Erik Rodner, Joachim Denzler:
Approximations of Gaussian Process Uncertainties for Visual Recognition Problems.
Scandinavian Conference on Image Analysis (SCIA).
Pages 182-194.
2013.
[bibtex]
[pdf]
[web]
[doi]
[abstract]
Gaussian processes offer the advantage of calculating the classification uncertainty in terms of predictive variance associated with the classification result. This is especially useful to select informative samples in active learning and to spot samples of previously unseen classes known as novelty detection. However, the Gaussian process framework suffers from high computational complexity leading to computation times too large for practical applications. Hence, we propose an approximation of the Gaussian process predictive variance leading to rigorous speedups. The complexity of both learning and testing the classification model regarding computational time and memory demand decreases by one order with respect to the number of training samples involved. The benefits of our approximations are verified in experimental evaluations for novelty detection and active learning of visual object categories on the datasets C-Pascal of Pascal VOC 2008, Caltech-256, and ImageNet.

Paul Bodesheim, Alexander Freytag, Erik Rodner, Michael Kemmler, Joachim Denzler:
Kernel Null Space Methods for Novelty Detection.
IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
Pages 3374-3381.
2013.
[bibtex]
[pdf]
[web]
[doi]
[code]
[presentation]
[abstract]
Detecting samples from previously unknown classes is a crucial task in object recognition, especially when dealing with real-world applications where the closed-world assumption does not hold. We present how to apply a null space method for novelty detection, which maps all training samples of one class to a single point. Beside the possibility of modeling a single class, we are able to treat multiple known classes jointly and to detect novelties for a set of classes with a single model. In contrast to modeling the support of each known class individually, our approach makes use of a projection in a joint subspace where training samples of all known classes have zero intra-class variance. This subspace is called the null space of the training data. To decide about novelty of a test sample, our null space approach allows for solely relying on a distance measure instead of performing density estimation directly. Therefore, we derive a simple yet powerful method for multi-class novelty detection, an important problem not studied sufficiently so far. Our novelty detection approach is assessed in comprehensive multi-class experiments using the publicly available datasets Caltech-256 and ImageNet. The analysis reveals that our null space approach is perfectly suited for multi-class novelty detection since it outperforms all other methods.
Tamara Melmer, Seyed Ali Amirshahi, Michael Koch, Joachim Denzler, Christoph Redies:
From regular text to artistic writing and artworks: Fourier statistics of images with low and high aesthetic appeal.
Frontiers in Human Neuroscience.
7 (00106) :
2013.
[bibtex]
[abstract]
The spatial characteristics of letters and their influence on readability and letter identification have been intensely studied during the last decades. There have been few studies, however, on statistical image properties that reflect more global aspects of text, for example properties that may relate to its aesthetic appeal. It has been shown that natural scenes and a large variety of visual artworks possess a scale-invariant Fourier power spectrum that falls off linearly with increasing frequency in log-log plots. We asked whether images of text share this property. As expected, the Fourier spectrum of images of regular typed or handwritten text is highly anisotropic, i.e. the spectral image properties in vertical, horizontal and oblique orientations differ. Moreover, the spatial frequency spectra of text images are not scale invariant in any direction. The decline is shallower in the low-frequency part of the spectrum for text than for aesthetic artworks, whereas, in the high-frequency part, it is steeper. These results indicate that, in general, images of regular text contain less global structure (low spatial frequencies) relative to fine detail (high spatial frequencies) than images of aesthetics artworks. Moreover, we studied images of text with artistic claim (ornate print and calligraphy) and ornamental art. For some measures, these images assume average values intermediate between regular text and aesthetic artworks. Finally, to answer the question of whether the statistical properties measured by us are universal amongst humans or are subject to intercultural differences, we compared images from three different cultural backgrounds (Western, East Asian and Arabic). Results for different categories (regular text, aesthetic writing, ornamental art and fine art) were similar across cultures.

Alexander Freytag, Erik Rodner, Paul Bodesheim, Joachim Denzler:
Beyond Classification - Large-scale Gaussian Process Inference and Uncertainty Prediction.
Big Data Meets Computer Vision: First International Workshop on Large Scale Visual Recognition and Retrieval (NIPS-WS).
2012.
This workshop article is a short version of our ACCV 2012 paper.
[bibtex]
[pdf]
[abstract]
Due to the massive (labeled) data available on the web, a tremendous interest in large-scale machine learning methods has emerged in the last years. Whereas, most of the work done in this new area of research focused on fast and efficient classification algorithms, we show in this paper how other aspects of learning can also be covered using massive datasets. The paper briefly presents techniques allowing for utilizing the full posterior obtained from Gaussian process regression (predictive mean and variance) with tens of thousands of data points and without relying on sparse approximation approaches. Experiments are done for active learning and one-class classification showing the benefits in large-scale settings.

Alexander Freytag, Erik Rodner, Paul Bodesheim, Joachim Denzler:
Rapid Uncertainty Computation with Gaussian Processes and Histogram Intersection Kernels.
Asian Conference on Computer Vision (ACCV).
Pages 511-524.
2012.
Best Paper Honorable Mention Award
[bibtex]
[pdf]
[web]
[doi]
[presentation]
[abstract]
An important advantage of Gaussian processes is the ability to directly estimate classification uncertainties in a Bayesian manner. In this paper, we develop techniques that allow for estimating these uncertainties with a runtime linear or even constant with respect to the number of training examples. Our approach makes use of all training data without any sparse approximation technique while needing only a linear amount of memory. To incorporate new information over time, we further derive online learning methods leading to significant speed-ups and allowing for hyperparameter optimization on-the-fly. We conduct several experiments on public image datasets for the tasks of one-class classification and active learning, where computing the uncertainty is an essential task. The experimental results highlight that we are able to compute classification uncertainties within microseconds even for large-scale datasets with tens of thousands of training examples.

Erik Rodner, Alexander Freytag, Paul Bodesheim, Joachim Denzler:
Large-Scale Gaussian Process Classification with Flexible Adaptive Histogram Kernels.
European Conference on Computer Vision (ECCV).
Pages 85-98.
2012.
[bibtex]
[pdf]
[web]
[doi]
[supplementary]
[abstract]
We present how to perform exact large-scale multi-class Gaussian process classification with parameterized histogram intersection kernels. In contrast to previous approaches, we use a full Bayesian model without any sparse approximation techniques, which allows for learning in sub-quadratic and classification in constant time. To handle the additional model flexibility induced by parameterized kernels, our approach is able to optimize the parameters with large-scale training data. A key ingredient of this optimization is a new efficient upper bound of the negative Gaussian process log-likelihood. Experiments with image categorization tasks exhibit high performance gains with flexible kernels as well as learning within a few minutes and classification in microseconds for databases, where exact Gaussian process inference was not possible before.

Manuel Amthor, Daniel Haase, Joachim Denzler:
Fast and Robust Landmark Tracking in X-ray Locomotion Sequences Containing Severe Occlusions.
International Workshop on Vision, Modelling, and Visualization (VMV).
Pages 15-22.
2012.
[bibtex]
[abstract]
Recent advances in the understanding of animal locomotion have proven it to be a key element of many fields in biology, motion science, and robotics. For the analysis of walking animals, high-speed x-ray videography is employed. For a biological evaluation of these x-ray sequences, anatomical landmarks have to be located in each frame. However, due to the motion of the animals, severe occlusions complicate this task and standard tracking methods can not be applied. We present a robust tracking approach which is based on the idea of dividing a template into sub-templates to overcome occlusions. The difference to other sub-template approaches is that we allow soft decisions for the fusion of the single hypotheses, which greatly benefits tracking stability. Also, we show how anatomical knowledge can be included into the tracking process to further improve the performance. Experiments on real datasets show that our method achieves results superior to those of existing robust approaches.
Paul Bodesheim, Erik Rodner, Alexander Freytag, Joachim Denzler:
Divergence-Based One-Class Classification Using Gaussian Processes.
British Machine Vision Conference (BMVC).
Pages 50.1-50.11.
2012.
[bibtex]
[pdf]
[web]
[doi]
[presentation]
[abstract]
We present an information theoretic framework for one-class classification, which allows for deriving several new novelty scores. With these scores, we are able to rank samples according to their novelty and to detect outliers not belonging to a learnt data distribution. The key idea of our approach is to measure the impact of a test sample on the previously learnt model. This is carried out in a probabilistic manner using Jensen-Shannon divergence and reclassification results derived from the Gaussian process regression framework. Our method is evaluated using well-known machine learning datasets as well as large-scale image categorisation experiments showing its ability to achieve state-of-the-art performance.
Alexander Lütz, Erik Rodner, Joachim Denzler:
Efficient Multi-Class Incremental Learning Using Gaussian Processes.
Open German-Russian Workshop on Pattern Recognition and Image Understanding (OGRW).
Pages 182-185.
2011.
[bibtex]
[pdf]
[abstract]
One of the main assumptions in machine learning is that sufficient training data is available in advance and batch learning can be applied. However, because of the dynamics in a lot of applications, this assumption will break down in almost all cases over time. Therefore, classifiers have to be able to adapt themselves when new training data from existing or new classes becomes available, training data is changed or should be even removed. In this paper, we present a method allowing efficient incremental learning of a Gaussian process classifier. Experimental results show the benefits in terms of needed computation times compared to building the classifier from the scratch.

Daniel Haase, Joachim Denzler:
Anatomical Landmark Tracking for the Analysis of Animal Locomotion in X-ray Videos Using Active Appearance Models.
Scandinavian Conference on Image Analysis (SCIA).
Pages 604-615.
2011.
[bibtex]
[pdf]
[abstract]
X-ray videography is one of the most important techniques for the locomotion analysis of animals in biology, motion science and robotics. Unfortunately, the evaluation of vast amounts of acquired data is a tedious and time-consuming task. Until today, the anatomical landmarks of interest have to be located manually in hundreds of images for each image sequence. Therefore, an automatization of this task is highly desirable. The main difficulties for the automated tracking of these landmarks are the numerous occlusions due to the movement of the animal and the low contrast in the x-ray images. For this reason, standard tracking approaches fail in this setting. To overcome this limitation, we analyze the application of Active Appearance Models for this task. Based on real data, we show that these models are capable of effectively dealing with occurring occlusions and low contrast and can provide sound tracking results.

Daniel Haase, John A. Nyakatura, Joachim Denzler:
Multi-view Active Appearance Models for the X-ray Based Analysis of Avian Bipedal Locomotion.
Symposium of the German Association for Pattern Recognition (DAGM).
Pages 11-20.
2011.
[bibtex]
[pdf]
[abstract]
Many fields of research in biology, motion science and robotics depend on the understanding of animal locomotion. Therefore, numerous experiments are performed using high-speed biplanar x-ray acquisition systems which record sequences of walking animals. Until now, the evaluation of these sequences is a very time-consuming task, as human experts have to manually annotate anatomical landmarks in the images. Therefore, an automation of this task at a minimum level of user interaction is worthwhile. However, many difficulties in the data�such as x-ray occlusions or anatomical ambiguities�drastically complicate this problem and require the use of global models. Active Appearance Models (AAMs) are known to be capable of dealing with occlusions, but have problems with ambiguities. We therefore analyze the application of multi-view AAMs in the scenario stated above and show that they can effectively handle uncertainties which can not be dealt with using single-view models. Furthermore, preliminary studies on the tracking performance of human experts indicate that the errors of multi-view AAMs are in the same order of magnitude as in the case of manual tracking.

Esther-Sabrina Wacker, Joachim Denzler:
Combining structure and appearance for anomaly detection in wire ropes.
International Conference on Computer Analysis of Images and Patterns (CAIP).
Pages 163-170.
2011.
[bibtex]
[pdf]
[abstract]
We present a new approach for anomaly detection in the context of visual surface inspection. In contrast to existing, purely appearance-based approaches, we explicitly integrate information about the object geometry. The method is tested using the example of wire rope inspection as this is a very challenging problem. A perfectly regular 3d model of the rope is aligned with a sequence of 2d rope images to establish a direct connection between object geometry and observed rope appearance. The surface appearance can be physically explained by the rendering equation.Without a need for knowledge about the illumination setting or the reflectance properties of the material we are able to sample the rendering equation. This results in a probabilistic appearance model. The density serves as description for normal surface variations and allows a robust localization of rope surface defects. We evaluate our approach on real-world data from real ropeways. The accuracy of our approach is comparable to that of a human expert and outperforms all other existing approaches. It has an accuracy of 95% and a low false-alarm-rate of 1.5%, whereupon no single defect is missed.

Daniel Haase, Esther-Sabrina Wacker, Ernst Günter Schukat-Talamazzini, Joachim Denzler:
Analysis of Structural Dependencies for the Automatic Visual Inspection of Wire Ropes.
International Workshop on Vision, Modelling, and Visualization (VMV).
Pages 49-56.
2010.
[bibtex]
[pdf]
[abstract]
Automatic visual inspection is an arising field of research. Especially in security relevant applications, an automation of the inspection process would be a great benefit. For wire ropes, a first step is the acquisition of the curved surface with several cameras located all around the rope. Because most of the visible defects in such a rope are very inconspicuous, an automatic defect detection is a very challenging problem. As in general there is a lack of defective training data, most of the presented ideas for automatic rope inspection are embedded in a one-class classification framework. However, none of these methods makes use of the context information which results from the fact that all camera views image the same rope. In contrast to an individual analysis of each camera view, this work proposes the simultaneous analysis of all available camera views with the help of a vector autoregressive model. Moreover, various dependency analysis methods are used to give consideration to the regular rope structure and to deal with the high dimensionality of the problem. These dependencies are then used as constraints for the vector autoregressive model, which results in a sparse but powerful detection system. The proposed method is evaluated by using real wire rope data and the conducted experiments show that our approach clearly outperforms all previously presented methods.

Esther-Sabrina Platzer, Herbert Süße, Josef Nägele, Karl-Heinz Wehking, Joachim Denzler:
On the Suitability of Different Features for Anomaly Detection in Wire Ropes.
Computer Vision, Imaging and Computer Graphics: Theory and Applications.
Pages 296-308.
2010.
[bibtex]
[pdf]
[abstract]
Automatic visual inspection of wire ropes is an important but challenging task, as anomalies in the rope are usually unobtrusive. Certainly, a reliable anomaly detection is essential to assure the safety of the ropes. A one-class classification approach for the automatic detection of anomalies in wire ropes is presented. Furthermore, the performance of different well-established features from the field of textural defect detection are compared with respect to this task. The faultless rope structure is thereby modeled by a Gaussian mixture model and outliers are regarded as anomaly. To prove the practical applicability, a careful evaluation of the presented approach is performed on real-life rope data. In doing so, a special interest was put on the robustness of the model with respect to unintentional outliers in the training and on its generalization ability given further data from an identically constructed rope. The results prove good recognition rates accompanied by a high generalization ability and robustness to outliers in the training set.

Esther-Sabrina Wacker, Joachim Denzler:
An Analysis-by-Synthesis Approach to Rope Condition Monitoring.
International Symposium on Visual Computing (ISVC).
Pages 459-468.
2010.
[bibtex]
[pdf]
[abstract]
A regular rope quality inspection is compulsory for wire ropes in security-relevant applications. Principal procedures of such quality checks are the visual inspection for surface defect detection, the magnetic inspection for a localization of broken wires and the measurement of the rope diameter. However, until today it is hardly possible for the human inspector to measure other important rope characteristics as the lay length of wires and strands over time. To close this gap, we present a model-based approach for rope parameter estimation. The usage of a theoretically correct and regular 3d rope, embedded in an analysis-by synthesis framework, allows a purely image-based monitoring of important rope parameters. Beyond that, also a quantification of the degree of abnormality becomes possible. Our evaluation on real-world and synthetic reference data demonstrates that the approach allows a measurement of the individual lay lengths of wires and strands up to an accuracy more precise than 1mm.
Michael Koch, Joachim Denzler, Christoph Redies:
1/f^2 Characteristics and Isotropy in the Fourier Power Spectra of Visual Art, Cartoons, Comics, Mangas, and Different Categories of Photographs.
PLoS ONE.
5 (8) :
pp. e12268.
2010.
[bibtex]
[abstract]
Art images and natural scenes have in common that their radially averaged (1D) Fourier spectral power falls according to a power-law with increasing spatial frequency (1/f<sup>2</sup> characteristics), which implies that the power spectra have scale-invariant properties. In the present study, we show that other categories of man-made images, cartoons and graphic novels (comics and mangas), have similar properties. Further on, we extend our investigations to 2D power spectra. In order to determine whether the Fourier power spectra of man-made images differed from those of other categories of images (photographs of natural scenes, objects, faces and plants and scientific illustrations), we analyzed their 2D power spectra by principal component analysis. Results indicated that the first fifteen principal components allowed a partial separation of the different image categories. The differences between the image categories were studied in more detail by analyzing whether the mean power and the slope of the power gradients from low to high spatial frequencies varied across orientations in the power spectra. Mean power was generally higher in cardinal orientations both in real-world photographs and artworks, with no systematic difference between the two types of images. However, the slope of the power gradients showed a lower degree of mean variability across spectral orientations (i.e., more isotropy) in art images, cartoons and graphic novels than in photographs of comparable subject matters. Taken together, these results indicate that art images, cartoons and graphic novels possess relatively uniform 1/f<sup>2</sup> characteristics across all orientations. In conclusion, the man-made stimuli studied, which were presumably produced to evoke pleasant and/or enjoyable visual perception in human observers, form a subset of all images and share statistical properties in their Fourier power spectra. Whether these properties are necessary or sufficient to induce aesthetic perception remains to be investigated.

Esther-Sabrina Platzer, Josef Nägele, Karl-Heinz Wehking, Joachim Denzler:
HMM-based Defect Localization in Wire Ropes - A new Approach to Unusual Subsequence Recognition.
Symposium of the German Association for Pattern Recognition (DAGM).
Pages 442-451.
2009.
[bibtex]
[pdf]
[abstract]
Automatic visual inspection has become an important application of pattern recognition, as it supports the human in this demanding and often dangerous work. Nevertheless, often missing abnormal or defective samples prohibit a supervised learning of defect models. For this reason, techniques known as one-class classification and novelty- or unusual event detection have arisen in the past years. This paper presents a new strategy to employ Hidden Markov models for defect localization in wire ropes. It is shown, that the Viterbi scores can be used as indicator for unusual subsequences. This prevents a partition of the signal into sufficient small signal windows at cost of the temporal context. Our results outperform recent time-invariant one-class classification approaches and depict a great advance for an automatic visual inspection of wire ropes.
Michael Koch, Joachim Denzler, Christoph Redies:
Principal component analysis of fourier transforms discriminates visual art from other image categories.
ECVP Abstract Supplement.
Pages 49.
2009.
[bibtex]
[abstract]
On average, natural scenes show a unique property in the Fourier domain--a roughly 1/f2 power spectrum, to which processing in the human visual system is optimally adapted. Recent studies reported similar properties in visual art of different styles and epochs. Here, we compared various datasets of photographs (natural scenes, objects, faces) and man-made images (art, cartoons, comics, scientific illustrations). Each dataset contained at least 150 images (1800 images in total). Results showed that, like art and natural scenes, cartoons and comics possess roughly 1/f2 power spectra. Principal component analysis of the 2-D power spectra revealed statistical differences between the image categories that were verified pairwise by significance testing. The resulting frequency-domain eigenspace achieved a good separation of the diverse categories. Principal component analysis carried out separately for each category showed that the first components of the art categories (graphic art, portraits and paintings) were similar, despite large differences in subject matters and artistic techniques. The power spectra of art images can be fitted well to a model that assumes 1/f2 characteristics and isotropy. In conclusion, art images display properties in the Fourier domain that allow to distinguish them from other image categories.

Erik Rodner, Herbert Süße, Wolfgang Ortmann, Joachim Denzler:
Difference of Boxes Filters Revisited: Shadow Suppression and Efficient Character Segmentation.
IAPR Workshop on Document Analysis Systems.
Pages 263-269.
2008.
[bibtex]
[pdf]
[presentation]
[abstract]
A robust segmentation is the most important part of an automatic character recognition system (e.g. document pro- cessing, license plate recognition etc.). In our contribution we present an efficient segmentation framework using a pre- processing step for shadow suppression combined with a local thresholding technique. The method is based on a combination of difference of boxes filters and a new ternary segmentation, which are both simple low-level image oper- ations. We also draw parallels to a recently published work on a ganglion cell model and show that our approach is theoret- ically more substantiated as well as more robust and more efficient in practice. Systematic evaluation of noisy input data as well as results on a large dataset of license plate images 1 show the robustness and efficiency of our proposed method. Our results can be applied easily to any optical char- acter recognition system resulting in an impressive gain of robustness against nonlinear illumination.
Esther-Sabrina Platzer, Frank Deinzer, Dietrich Paulus, Joachim Denzler:
3D Blood Flow Reconstruction from 2D Angiograms.
Bildverarbeitung für die Medizin 2008 - Algorithmen, Systeme, Anwendungen.
Pages 288-292.
2008.
[bibtex]
[pdf]
[abstract]
A method for 3-d blood flow reconstruction is presented. Given a 3-d volume of a vessel tree and a 2-d sequence of angiograms, the propagation information can be back-projected into the 3-d vessel volume. In case of overlapping vessel segments in the 2-d projections, ambiguous back-projection results are obtained. We introduce a probabilistic blood flow model for solving these ambiguities. Based on the last estimated state and known system dynamics the next state is predicted, and predictions are judged by the back-projected information. The discrete realization is done with a particle filter. Experiments prove the efficiency of our method.
Esther-Sabrina Platzer, Joachim Denzler, Herbert Süße, Josef Nägele, Karl-Heinz Wehking:
Challenging Anomaly Detection in Wire Ropes Using Linear Prediction Combined with One-class Classification.
International Fall Workshop on Vision, Modelling, and Visualization (VMV).
Pages 343-352.
2008.
[bibtex]
[pdf]
[abstract]
Automatic visual inspection has gathered a high importance in many fields of industrial applications. Especially in security relevant applications visual inspection is obligatory. Unfortunately, this task currently bears also a risk for the human inspector, as in the case of visual rope inspection. The huge and heavy rope is mounted in great height, or it is directly connected with running machines. Furthermore, the defects and anomalies are so inconspicuous, that even for a human expert this is a very demanding task. For this reason, we present an approach for the automatic detection of defects or anomalies in wire ropes. Features, which incorporate context-information from the preceding rope region, are extracted with help of linear prediction. These features are then used to learn the faultless and normal structure of the rope with help of a one-class classification approach. Two different learning strategies, the K-means clustering and a Gaussian mixture model, are used and compared. The evaluation is done on real rope data from a ropeway. Our first results considering this demanding task show that it is possible to exclude more than 90 percent of the rope as faultless.

Martin Rapus, Stefan Munder, Gregory Baratoff, Joachim Denzler:
Pedestrian Recognition Using Combined Low-Resolution Depth and Intensity Images.
IEEE Intelligent Vehicles Symposium.
Pages 632-636.
2008.
[bibtex]
[pdf]
[abstract]
We present a novel system for pedestrian recognition through depth and intensity measurements. A 3D-Camera is used as main sensor, which provides depth and intensity measurements with a resolution of 64x8 pixels and a depth range of 0-20 meters. The first step consists of extracting the ground plane from the depth image by an adaptive flat world assumption. An AdaBoost head-shoulder detector is then used to generate hypotheses about possible pedestrian positions. In the last step every hypothesis is classified with AdaBoost or a SVM as pedestrian or non-pedestrian. We evaluated a number of different features known from the literature. The best result was achieved by Fourier descriptors in combination with the edges of the intensity image and an AdaBoost classifier, which resulted in a recognition rate of 83.75 percent.
Olaf Kähler, Erik Rodner, Joachim Denzler:
On Fusion of Range and Intensity Information Using Graph-Cut for Planar Patch Segmentation.
International Journal of Intelligent Systems Technologies and Applications.
5 (3/4) :
pp. 365-373.
2008.
[bibtex]
[pdf]
[abstract]
Planar patch detection aims at simplifying data from 3-D imaging sensors to a more compact scene description. We propose a fusion of intensity and depth information using Graph-Cut methods for this problem. Different known algorithms are additionally evaluated on lowresolution high-framerate image sequences and used as an initialization for the Graph-Cut approach. In experiments we show a significant improvement of the detected patch boundaries after the refinement with our method.
Olaf Kähler, Joachim Denzler:
Implicit Feedback between Reconstruction and Tracking in a Combined Optimization Approach.
Symposium of the German Association for Pattern Recognition (DAGM).
Pages 274-283.
2008.
[bibtex]
[abstract]
In this work, we present a combined approach to tracking and reconstruction. An implicit feedback of 3d information to the tracking process is achieved by optimizing a single error function, instead of two separate steps. No assumptions about the error distribution of the tracker are needed in the reconstruction step either. This results in higher reconstruction accuracy and improved tracking robustness in our experimental evaluations. The approach is suited for online reconstruction and has a close to real-time performance on current computing hardware.
Olaf Kähler, Joachim Denzler:
Robust Real-Time SFM in a Combined Formulation of Tracking and Reconstruction.
International Fall Workshop Vision, Modelling, and Visualization (VMV).
Pages 283-292.
2008.
[bibtex]
[abstract]
Recently it was observed, that a combined formulation of tracking and reconstruction increases the robustness and accuracy of both these steps in structure-from-motion problems [9]. However, the benefits come at the cost of a higher computational complexity. In this work, we present strategies for an efficient implementation of such a combined approach. We identify the time consuming steps in the system and analyze opportunities for simplifying and parallelizing the original problem. An evaluation of the overall system is presented and we show, that frame rates of 5 fps and beyond are achieved on current hardware, without significant losses in robustness and accuracy.
Christoph Redies, Jan Hänisch, Marko Blickhan, Joachim Denzler:
Artists portray human faces with the Fourier statistics of complex natural scenes.
Network: Computation in Neural Systems.
18 (3) :
pp. 235-248.
2007.
[bibtex]
[pdf]
[web]
[abstract]
When artists portray human faces, they generally endow their portraits with properties that render the faces esthetically more pleasing. To obtain insight into the changes introduced by artists, we compared Fourier power spectra in photographs of faces and in portraits by artists. Our analysis was restricted to a large set of monochrome or lightly colored portraits from various Western cultures and revealed a paradoxical result. Although face photographs are not scale-invariant, artists draw human faces with statistical properties that deviate from the face photographs and approximate the scale-invariant, fractal-like properties of complex natural scenes. This result cannot be explained by systematic differences in the complexity of patterns surrounding the faces or by reproduction artifacts. In particular, a moderate change in gamma gradation has little influence on the results. Moreover, the scale-invariant rendering of faces in artists’ portraits was found to be independent of cultural variables, such as century of origin or artistic techniques. We suggest that artists have implicit knowledge of image statistics and prefer natural scene statistics (or some other rules associated with them) in their creations. Fractal-like statistics have been demonstrated previously in other forms of visual art and may be a general attribute of esthetic visual stimuli.
Ferid Bajramovic, Joachim Denzler:
Self-calibration with Partially Known Rotations.
Symposium of the German Association for Pattern Recognition (DAGM).
Pages 1-10.
2007.
[bibtex]
[pdf]
[abstract]
Self-calibration methods allow estimating the intrinsic camera parameters without using a known calibration object. However, such methods are very sensitive to noise, even in the simple special case of a purely rotating camera. Suitable pan-tilt-units can be used to perform pure camera rotations. In this case, we can get partial knowledge of the rotations, e.g. by rotating twice about the same axis. We present extended self-calibration algorithms which use such knowledge. In systematic simulations, we show that our new algorithms are less sensitive to noise. Experiments on real data result in a systematic error caused by non-ideal hardware. However, our algorithms can reduce the systematic error. In the case of complete rotation knowledge, it can even be greatly reduced.
Olaf Kähler, Erik Rodner, Joachim Denzler:
On Fusion of Range and Intensity Information Using Graph-Cut for Planar Patch Segmentation.
Proceedings Dynamic 3D Imaging Workshop.
Pages 113-121.
2007.
also appeared in International Journal of Intelligent Systems Technologies and Applications, Vol. 5, No. 3/4, pp.365-373
[bibtex]
[abstract]
Planar patch detection aims at simplifying data from 3-D imaging sensors to a more compact scene description. We propose a fusion of intensity and depth information using Graph-Cut methods for this problem. Different known algorithms are additionally evaluated on lowresolution high-framerate image sequences and used as an initialization for the Graph-Cut approach. In experiments we show a significant improvement of the detected patch boundaries after the refinement with our method.
Olaf Kähler, Joachim Denzler:
Detecting Coplanar Feature Points in Handheld Image Sequences.
International Conference on Computer Vision Theory and Applications (VISAPP).
Pages 447-452.
2007.
[bibtex]
[pdf]
[abstract]
3D reconstruction applications can benefit greatly from knowledge about coplanar feature points. Extracting this knowledge from images alone is a difficult task, however. The typical approach to this problem is to search for homographies in a set of point correspondences using the RANSAC algorithm. In this work we focus on two open issues with a blind random search. First, we enforce the detected planes to represent physically present scene planes. Second, we propose methods to identify cases, in which a homography does not imply coplanarity of feature points. Experiments are performed to show applicability of the presented plane detection algorithms to handheld image sequences.
Olaf Kähler, Joachim Denzler:
Rigid Motion Constraints for Tracking Planar Objects.
Symposium of the German Association for Pattern Recognition (DAGM).
Pages 102-111.
2007.
[bibtex]
[abstract]
Typical tracking algorithms exploit temporal coherence, in the sense of expecting only small object motions. Even without exact knowledge of the scene, additional spatial coherence can be exploited by expecting only a rigid 3d motion. Feature tracking will benefit from knowing about this rigidity of the scene, especially if individual features cannot be tracked by themselves due to occlusions or illumination changes. We present and compare different approaches of dealing with the spatial coherence in the context of tracking planar scenes. We also show the benefits in scenes with occlusions and changes in illumination, even without models of these distortions.

Ferid Bajramovic, Frank Mattern, Nicholas Butko, Joachim Denzler:
A Comparison of Nearest Neighbor Search Algorithms for Generic Object Recognition.
Advanced Concepts for Intelligent Vision Systems.
Pages 1186-1197.
2006.
[bibtex]
[pdf]
[abstract]
The nearest neighbor (NN) classifier is well suited for generic object recognition. However, it requires storing the complete training data, and classification time is linear in the amount of data. There are several approaches to improve runtime and/or memory requirements of nearest neighbor methods: Thinning methods select and store only part of the training data for the classifier. Efficient query structures reduce query times. In this paper, we present an experimental comparison and analysis of such methods using the ETH-80 database. We evaluate the following algorithms. Thinning: condensed nearest neighbor, reduced nearest neighbor, Baram's algorithm, the Baram-RNN hybrid algorithm, Gabriel and GSASH thinning. Query structures: kd-tree and approximate nearest neighbor. For the first four thinning algorithms, we also present an extension to k-NN which allows tuning the trade-off between data reduction and classifier degradation. The experiments show that most of the above methods are well suited for generic object recognition.
Olaf Kähler, Joachim Denzler:
Detection of Planar Patches in Handheld Image Sequences.
Proceedings Photogrammetric Computer Vision 2006.
Pages 37-42.
2006.
[bibtex]
[pdf]
[abstract]
Coplanarity of points can be exploited in many ways for 3D reconstruction. Automatic detection of coplanarity is not a simple task however. We present methods to detect physically present 3D planes in scenes imaged with a handheld camera. Such planes induce homographies, which provides a necessary, but not a sufficient criterion to detect them. Especially in handheld image sequences degenerate cases are abundant, where the whole image underlies the same homography. We provide methods to verify, that a homography does carry information about coplanarity and the 3D scene structure. This allows deciding, whether planes can be detected from the images or not. Different methods for both known and unknown intrinsic camera parameters are compared experimentally.
Benjamin Deutsch, Christoph Gräßl, Ferid Bajramovic, Joachim Denzler:
A Comparative Evaluation of Template and Histogram Based 2D Tracking Algorithms.
Symposium of the German Association for Pattern Recognition (DAGM).
Pages 269-276.
2005.
[bibtex]
[pdf]
[abstract]
In this paper, we compare and evaluate five contemporary, data-driven real-time 2D object tracking methods: the region tracker by Hager et al., the Hyperplane tracker, the CONDENSATION tracker, and the Mean Shift and Trust Region trackers. The first two are classical template based methods, while the latter three are from the more recently proposed class of histogram based trackers. All trackers are evaluated for the task of pure translation tracking, as well as tracking translation plus scaling. For the evaluation, we use a publically available, labeled data set consisting of surveillance videos of humans in public spaces. This data set demonstrates occlusions, changes in object appearance, and scaling.

Ferid Bajramovic, Christoph Gräßl, Joachim Denzler:
Efficient Combination of Histograms for Real-Time Tracking Using Mean-Shift and Trust-Region Optimization.
Symposium of the German Association for Pattern Recognition (DAGM).
Pages 254-261.
2005.
[bibtex]
[pdf]
[abstract]
Histogram based real-time object tracking methods, like the Mean-Shift tracker of Comaniciu/Meer or the Trust-Region tracker of Liu/Chen, have been presented recently. The main advantage is that a suited histogram allows for very fast and accurate tracking of a moving object even in the case of partial occlusions and for a moving camera. The problem is which histogram shall be used in which situation. In this paper we extend the framework of histogram based tracking. As a consequence we are able to formulate a tracker that uses a weighted combination of histograms of different features. We compare our approach with two already proposed histogram based trackers for different histograms on large test sequences available to the public. The algorithms run in real-time on standard PC hardware.
Torsten Rohlfing, Daniel B. Russakoff, Joachim Denzler, Calvin R. Maurer:
Progressive Attenuation Fields: Fast 2D-3D Image Registration Without Precomputation.
International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI).
Pages 631-638.
2004.
[bibtex]
[web]
[doi]
[abstract]
This paper introduces the progressive attenuation field (PAF), a method to speed up computation of digitally reconstructed radiograph (DRR) images during intensity-based 2D-3D registration. Unlike traditional attenuation fields, a PAF is built on the fly as the registration proceeds. It does not require any precomputation time, nor does it make any prior assumptions of the patient pose that would limit the permissible range of patient motion. We use a cylindrical attenuation field parameterization, which is better suited for medical 2D-3D registration than the usual two-plane parameterization. The computed attenuation values are stored in a hash table for time-efficient storage and access. Using a clinical gold-standard spine image dataset, we demonstrate a speedup of 2D-3D image registration by a factor of four over ray-casting DRR with no decrease of registration accuracy or robustness.

Frank Deinzer, Joachim Denzler, Heinrich Niemann:
Viewpoint Selection - Planning Optimal Sequences of Views for Object Recognition.
International Conference on Computer Analysis of Images and Patterns (CAIP).
Pages 65-73.
2003.
[bibtex]
[pdf]
[abstract]
In the past decades most object recognition systems were based on passive approaches. But in the last few years a lot of research was done in the field of active object recognition. In this context there are several unique problems to be solved, like the fusion of several views and the selection of the best next viewpoint. In this paper we present an approach to solve the problem of choosing optimal views (viewpoint selection) and the fusion of these for an optimal 3D object recognition (viewpoint fusion). We formally define the selection of additional views as an optimization problem and we show how to use reinforcement learning for viewpoint training and selection in continuous state spaces without user interaction. We also present an approach for the fusion of multiple views based on recursive density propagation. The experimental results show that our viewpoint selection is able to select a minimal number of views and perform an optimal object recognition with respect to the classification.
Rainer Deventer, Joachim Denzler, Heinrich Niemann, Oliver Kreis:
Using Test Plans for Bayesian Modeling.
Machine Learning and Data Mining in Pattern Recognition.
Pages 307-316.
2003.
[bibtex]
[pdf]
[abstract]
When modeling technical processes, the training data regularly come from test plans, to reduce the number of experiments and to save time and costs. On the other hand, this leads to unobserved combinations of the input variables. In this article it is shown, that these unobserved configurations might lead to un-trainable parameters. Afterwards a possible design criterion is introduced, which avoids this drawback. Our approach is tested to model a welding process. The results show, that hybrid Bayesian networks are able to deal with yet unobserved in- and output data.

Christopher Drexler, Frank Mattern, Joachim Denzler:
Appearance Based Generic Object Modeling and Recognition Using Probabilistic Principal Component Analysis.
Symposium of the German Association for Pattern Recognition (DAGM).
Pages 100-108.
2002.
isbn = 3-540-44209-X
[bibtex]
[pdf]
[abstract]
Classifying unknown objects in familiar, general categories rather than trying to classify them into a certain known, but only similar class, or rejecting them at all is an important aspect in object recognition. Especially in tasks, where it is impossible to model all possibly appearing objects in advance, generic object modeling and recognition is crucial. We present a novel approach to generic object modeling and classification based on probabilistic principal component analysis (PPCA). A data set can be separated into classes during an unsupervised learning step using the expectation-maximization algorithm. In contrast to principal component analysis the feature space is modeled in a locally linear manner. Additionally, Bayesian classification is possible thanks to the underlying probabilistic model. The approach is applied to the COIL-20/100 databases. It shows that PPCA is well suited for appearance based generic object modeling and recognition. The automatic, unsupervised generation of categories matches in most cases the categorization done by humans. Improvements are expected if the categorization is performed in a supervised fashion.

Christopher Drexler, Frank Mattern, Joachim Denzler:
Generic Hierarchic Object Models and Classification based on Probabilistic PCA.
IAPR Workshop on Machine Vision Applications.
Pages 435-438.
2002.
isbn = 4-901122-02-9
[bibtex]
[pdf]
[abstract]
Classifying unknown objects in familiar, general categories rather than trying to classify them into a certain known, but only similar class, or rejecting them at all is an important aspect in object recognition. Especially in tasks, where it is impossible to model all possibly appearing objects in advance, generic object modeling and recognition is crucial. We present a novel approach to generic object modeling and classification based on probabilistic principal component analysis (PPCA). A data set can be separated into classes during an unsupervised learning step using the expectation-maximization algorithm. In contrast to principal component analysis the feature space is modeled in a locally linear manner. Additionally, Bayesian classification is possible thanks to the underlying probabilistic model. The approach is applied to the COIL-20/100 databases. It shows that PPCA is well suited for appearance based generic object modeling and recognition. The automatic, unsupervised generation of categories matches in most cases the categorization done by humans. Improvements are expected if the categorization is performed in a supervised fashion.

Matthias Zobel, Joachim Denzler, Heinrich Niemann:
Binocular 3-D Object Tracking with Varying Focal Lengths.
IASTED International Conference on Signal Processing, Pattern Recognition, and Application.
Pages 325-330.
2002.
[bibtex]
[pdf]
[abstract]
In this paper we discuss some practical facets of active camera control during 3-D object tracking. The basis of our investigation is an active binocular camera system looking onto a scene to track a moving object in 3-D. Tracking is done in a data driven manner using an extented version of the region based method that was proposed earlier by Hager and Belhumeur. Triangulation of the extracted objects in the two image planes lead to an estimation of the 3-D position of the moving object. To keep the moving object in the center of the image the tilt and vergence axis of the binocular camera system is controlled. The important question for such an experimental setup is which parameters do influence the quality of the final 3-D estimation. The main effects we are concentrating on is the accuracy of the 2-D localization in the image plane depending on the focal length of the camera. Also the consequences of errors in the synchronization between image acquisition and motor control of the camera system are shortly discussed. All considerations are verified in real-time experiments.
Matthias Zobel, Joachim Denzler, Heinrich Niemann:
Entropy Based Camera Control for Visual Object Tracking.
International Conference on Image Processing (ICIP).
Pages 901-904.
2002.
[bibtex]
[pdf]
[abstract]
Due to shorter life cycles and more complex production processes the automatic generation of models for control purposes is of great importance. Even though Bayesian networks have proven their usefulness in machine learning and pattern recognition and the close relationship between Dynamic Bayesian networks and Kalman Filters respectively difference equations they have not been applied to problems in the area of automatic control. In our work we deduce the structure of a Dynamic Bayesian networks using the state space description and difference equations. Both models are trained by the EM algorithm and used for control purposes. The experiments show that both models performs well, but the training process of the model based on difference equations is much more stable.
Rainer Deventer, Joachim Denzler, Heinrich Niemann:
Using Non-Markov models for the control of Dynamic Systems.
Engineering of Intelligent Systems (EIS).
Pages 70 (complete pa.
2002.
[bibtex]
[pdf]
[abstract]
Due to shorter life cycles and more complex production processes the automatic generation of models for control purposes is of great importance. Even though Bayesian networks have proven their usefulness in machine learning and pattern recognition and the close relationship between Dynamic Bayesian networks and Kalman Filters respectively difference equations they have not been applied to problems in the area of automatic control. In our work we deduce the structure of a Dynamic Bayesian networks using the state space description and difference equations. Both models are trained by the EM algorithm and used for control purposes. The experiments show that both models performs well, but the training process of the model based on difference equations is much more stable.

Matthias Zobel, Arnd Gebhard, Dietrich Paulus, Joachim Denzler, Heinrich Niemann:
Robust Facial Feature Localization by Coupled Features.
IEEE International Conference on Automatic Face and Gesture Recognition (FG).
Pages 2-7.
2000.
[bibtex]
[pdf]
[abstract]
In this paper, we consider the problem of robust localization of faces and some of their facial features. The task arises e.g. in the medical field of visual analysis of facial paresis. We detect faces and facial features by means of appropriate DCT coefficients that we obtain by neatly using the coding capabilities of a JPEG hardware compressor. Beside an anthropometric localization approach we focus on how spatial coupling of the facial features can be used to improve robustness of the localization. Because the presented approach is embedded in a completely probabilistic framework, it is not restricted to facial features, it can be generalized to multipart objects of any kind. Therefore the notion of a "coupled structure" is introduced. Finally, the approach is applied to the problem of localizing facial features in DCT-coded images and results from our experiments are shown.

Rainer Deventer, Joachim Denzler, Heinrich Niemann:
Control of Dynamic Systems Using Bayesian Networks.
IBERAMIA/SBIA Workshops (Atibaia, São Paulo, Brazil).
Pages 33-39.
2000.
[bibtex]
[pdf]
[abstract]
Bayesian networks for the static as well as for the dynamic case have gained an enormous interest in the research community of artificial intelligence, machine learning and pattern recognition. Although the parallels between dynamic Bayesian networks and Kalman filters are well known since many years, Bayesian networks have not been applied to problems in the area of adaptive control of dynamic systems. In our work we exploit the well know similarities between Bayesian networks and Kalman filters to model and control linear dynamic systems using dynamic Bayesian networks. We show, how the model is used to calculate appropriate input signals for the dynamic system to achieve a required output signal. First the desired output value is entered as additional evidence. Then marginalization results in the most likely values of the input nodes. The experiments show that with our approach the desired value is reached in reasonable time and with great accuracy. Additionally, oscillating systems can be handled. The benefits of the proposed approach are the model based control strategy and the possibility to learn the structure and probabilities of the Bayesian network from examples.

Ralf Schug, Matthias Zobel, Joachim Denzler, Heinrich Niemann:
Sichtbasierte Personeneskortierung mittels einer autonomen mobilen Plattform.
Robotik 2000: Leistungsstand - Anwendungen - Visionen - Trends.
Pages 459-464.
2000.
[bibtex]
[pdf]
[abstract]
In diesem Artikel wird ein System vorgestellt, das einer autonomen mobilen Plattform die Lokalisierung und Eskortierung einer Person mit annähernd konstantem Abstand erlaubt. Dabei wird ausschließlich visuelle Information verarbeitet. Personen werden durch die Kontur des Kopf- und Schulterbereichs modelliert. Nach Einführung eines Maßes für die Bewertung derartiger Konturen können Personen auf relativ einfache Weise lokalisiert werden. Durch die zusätzliche Verwendung von Hautfarbeninformation und einem lokalen Optimieren der Konturhypothesen wird die Lokalisierung verbessert. Aufbauend auf den Lokalisierungsergebnissen erfolgt die dynamische Personenverfolgung mittels des so genannten CONDENSATION-Algorithmus. Abhängig von der geschätzten 3-D Personenposition wird schließlich die Plattformbewegung gesteuert. In this article, we describe a system that enables an autonomous mobile platform to localize and escort a person while keeping approximatley a constant distance. In the system, only visual information is used. We model a person by the contour of its head and shoulders. After the introduction of a criterion for measuring the goodness of a contour, persons can be localized in a relatively easy way. By incorporating information about skin color and by a local optimization step, the localization can be further improved. Based on the localization results, the task of dynamic person tracking is done by means of the so called CONDENSATION algorithm. Dependent on the resulting estimation of the 3-D position of the person, the mobile platform is steered to keep track of the moving person.

Benno Heigl, Reinhard Koch, Marc Pollefeys, Joachim Denzler, Luc Van Gool:
Plenoptic Modeling and Rendering from Image Sequences Taken by a Hand-Held Camera.
Mustererkennung 1999.
Pages 94-101.
1999.
[bibtex]
[pdf]
[abstract]
In this contribution we focus on plenoptic scene modeling and rendering from long image sequences taken with a hand-held camera. The image sequence is calibrated with a structure-from-motion approach that considers the special viewing geometry of plenoptic scenes. By applying a stereo matching technique, dense depth maps are recovered locally for each viewpoint. View-dependent rendering can be accomplished by mapping all images onto a common plane of mean geometry and weighting them in dependence on the actual position of a virtual camera. To improve accuracy, approximating planes are defined locally in a hierarchical refinement process. Their pose is calculated from the local depth maps associated with each view without requiring a consistent global representation of scene geometry. Extensive experiments with ground truth data and hand-held sequences confirm performance and accuracy of our approach.

Christopher Drexler, Carmen Frank, Joachim Denzler, Heinrich Niemann:
Probabilistisch modellierte Blicksteuerung zur Selbstlokalisation anhand natürlicher Landmarken.
Autonome Mobile Systeme.
Pages 221-230.
1999.
[bibtex]
[pdf]
[abstract]
Die sichere Selbstlokalisation autonomer Roboter bildet die Grundlage für deren Einsatz in natürlichen Umgebungen. Um dies in sich ständig verändernden Einsatzgebieten zu gewährleisten, wird ein aktiver Ansatz vorgestellt, der aufgrund von Farbmerkmalen, die aus den Sensordaten einer CCD-Kamera extrahiert werden, Umgebungskarten trainiert und während der Lokalisationsphase eine probabilistisch modellierte Positions- und Blickrichtungssteuerung verwendet. Zum Einsatz kommen Markov Entscheidungsprozesse, mit deren Hilfe Bewegungsfolgen so gewählt werden, dass die Wahrscheinlichkeit für die richtige Lokalisation anhand der im nächsten Schritt extrahierten Daten maximiert wird. Dabei wird nach einer unsicheren Standortbestimmung diejenige Position angefahren, welche die meiste Information zur Entscheidung über den korrekten Standpunkt beiträgt. Das Verfahren ist daher auch tolerant gegenüber neuen, falsch detektierten und verschwundenen Merkmalen. Anhand von Experimenten in einer realen Flurumgebung wird die Leistungsfähigkeit dieses aktiven Ansatzes mit passiven Methoden zur Selbstlokalisation verglichen.

Ulrike Ahlrichs, Joachim Denzler, Ralf Kompe, Heinrich Niemann:
Sprachgesteuerte Fovealisierung und Vergenz.
Aktives Sehen in biologischen und technischen Systemen.
Pages 52-59.
1996.
[bibtex]
[pdf]
[abstract]
Von der Ausrüstung von Robotern mit visuellen Fähigkeiten verspricht man sich, diese in die Lage zu versetzen, komplexe Aufgaben zu verrichten. Damit wächst gleichzeitig auch die Forderung nach einer flexiblen Bedienungsschnittstelle. Natürliche Sprache kann dabei eine wichtige Hilfestellung bieten. In diesem Beitrag stellen wir ein System vor, in dem gesprochen-sprachliche Anweisungen oder Anfragen an ein Stereokamerasystem gerichtet werden können. Durch diese sprachlichen Äußerungen werden sowohl die vom Kamerasystem auszuführenden Aufgaben festgelegt als auch die betroffenen Objekte beschrieben. Um die für das Kamerasystem wesentliche Information aus der Äußerung zu erschließen, wird diese nach Abbildung auf die optimale Wortkette durch einen Worterkenner mit Hilfe von semantischen Klassifikationsbäumen interpretiert. Die vom Kamerasystem zu lösenden Aufgaben umfassen die Lokalisation oder formatfüllende Darstellung (Fovealisierung) der beschriebenen Objekte sowie die Interpretation von Lageverhältnissen zwischen jeweils zwei Objekten. Für die Objektlokalisation wird ein auf Histogrammen basierender Ansatz verwendet. Die Fovealisierung eines Objekts wird über Zoombewegungen erreicht, während die Interpretation von Lageverhältnissen auf der Beurteilung des Vergenzwinkels beruht.

Joachim Denzler, Heinrich Niemann:
Combination of Simple Vision Modules for Robust Real-Time Motion Tracking.
European Transactions on Telecommunications.
5 (3) :
pp. 275-286.
1995.
[bibtex]
[pdf]
[abstract]
In this paper we describe a real time object tracking system consisting of three modules (motion detection, object tracking, robot control), each working with a moderate accuracy, implemented in parallel on a workstation cluster, and therefore operating fast without any specialized hardware. The robustness and quality of the system is achieved by a combination of these vision modules with an additional attention module which recognizes errors during the tracking. For object tracking in image sequences we apply the method of active contour models (snakes) which can be used for contour description and extraction as well. We show how the snake is initialized automatically by the motion detection module, explain the tracking module, and demonstrate the detection of errors during the tracking by the attention module. Experiments show that this approach allows a robust real-time object tracking over long image sequences. Using a formal error measurement presented in this paper it will be shown that the moving object is in the center of the image in 90 percent of all images.

Joachim Denzler, Heinrich Niemann:
Evaluating the Performance of Active Contour Models for Real-Time Object Tracking.
Asian Conference on Computer Vision (ACCV).
Pages II/341-II/345.
1995.
[bibtex]
[pdf]
[abstract]
In the past six years many algorithms and models for active contours (snakes) have been presented. Some of the work has been applied to static image analysis, some other to image sequence processing. Despite of the fact that snakes can be used for object tracking, no comparative study of the performance for real-time object tracking is known up to now. In this paper we compare several active contour models presented earlier in the literature for object tracking: the "Greedy" algorithm, the dynamic programming approach, and the first work of Kass, based on the variational calculus. We discuss and compare the various active contour models with respect to the quality of contour extraction, the computation time and robustness. All evaluation is done using sequences, grabbed during closed-loop real-time experiments.

Joachim Denzler, Dietrich Paulus:
Active Motion Detection and Object Tracking.
International Conference on Image Processing (ICIP).
Pages 635-639.
1994.
[bibtex]
[pdf]
[abstract]
In this paper we describe a two stage active vision system for tracking of a moving object which is detected in an overview image of the scene; a close-up view is then taken by changing the frame grabber's parameters and by a positional change of the camera mounted on a robot's hand. With a combination of several simple and fast working vision modules, a robust system for object tracking is constructed. The main principle is the use of two stages for object tracking: one for the detection of motion and one for the tracking itself. Errors in both stages can be detected in real time; then, the system switches back from the tracking to the motion detection stage. Standard UNIX interprocess communication mechanism are used for the communication between control and vision modules. Object-oriented programming hides hardware details.

Joachim Denzler, Heinrich Niemann:
A Two Stage Real-Time Object Tracking System.
1994.
[bibtex]
[pdf]
[abstract]
Active contour models (snakes) can be used for contour description and extraction, as well as for object tracking in image sequences. Two unsolved problems for real time object tracking are the problem of an automatic initialization of the snake on the object and the proof of robustness of this object tracking method. In this paper we describe a two stage real time object tracking system. In the first stage, the moving object is detected and the active contour is initialized. In the second stage, the object is tracked by active contour models. The parameters of the camera and the frame grabbing device are continuously updated in such a way, that the moving object will always be kept in the center of the image. We show how features can be extracted out of the snake tracking the object which are used for detection of errors in the tracking stage. In this case the system switches back to the first stage for object localization. We illustrate through examples that a robust tracking over long image sequences in real time is possible within this two stage system. For experimental evaluation of the tracking result, we present a formal error measure. Using this measure, the moving object is correctly in the center of the image in up to 95 percent of all images. Keywords: active contour models, tracking, real-time, active vision

Joachim Denzler, R. Beß, Joachim Hornegger, Heinrich Niemann, Dietrich Paulus:
Learning, Tracking and Recognition of 3D-Objects.
International Conference on Intelligent Robots and Systems.
Pages 89-96.
1994.
adress: München
[bibtex]
[pdf]
[abstract]
In this contribution we describe steps towards the implementation of an active robot vision system. In a sequence of images taken by a camera mounted on the hand of a robot, we detect, track, and estimate the position and orientation (pose) of a three-dimensional moving object. The extraction of the region of interest is done automatically by a motion tracking step. For learning 3-D objects using two-dimensional views and estimating the object's pose, a uniform statistical method is presented which is based on the Expectation-Maximization-Algorithm (EM-Algorithm). An explicit matching between features of several views is not necessary. The acquisition of the training sequence required for the statistical learning process needs the correlation between the image of an object and its pose; this is performed automatically by the robot. The robot's camera parameters are determined by a hand/eye-calibration and a subsequent computation of the camera position using the robot position. During the motion estimation stage the moving object is computed using active, elastic contours (snakes). We introduce a new approach for online initializing the snake on the first images of the given sequence, and show that the method of snakes is suited for real time motion tracking.
Dietrich Paulus, Joachim Denzler:
Möglichkeiten und Grenzen aktiven Sehens mit passiven Sensoren.
Autonome Mobile Systeme 1993.
Pages 275-287.
1993.
[bibtex]
[abstract]
Dieser Beitrag beschreibt einen Versuchsaufbau aus stationären und beweglichen Kameras zur Ermittlung von 3D Information für die Steuerung eines Roboters. Schwerpunkt bildet die Modellierung der Zoom-Kameras mit dem Zweck des fovealisierten Sehens. Aktives Sehen wird durch motorische Veränderung der Brennweite erreicht.
Joachim Denzler, Ralf Kompe, Andreas Kießling, Heinrich Niemann, Elmar Nöth:
Going Back to the Source: Inverse Filtering of the Speech Signal with ANNs.
EUROSPEECH.
Pages 111-114.
1993.
[bibtex]
[pdf]
[abstract]
In this paper we present a new method transforming speech signals to voice source signals (VSS) using artificial neural networks (ANN). We will point out that the ANN mapping of speech signals into source signals is quite accurate, and most of the irregularities in the speech signal will lead to an irregularity in the source signal, produced by the ANN (ANN-VSS). We will show that the mapping of the ANN is robust with respect to untrained speakers, different recording conditions and facilities, and different vocabularies. We will also present preliminary results which show that from the ANN source signal pitch periods can be determined accurately. Keywords: ANN, inverse filtering.