Tristan Piater, Björn Barz, Alexander Freytag:
Prompt-Tuning SAM: From Generalist to Specialist with Only 2,048 Parameters and 16 Training Images.
IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPR-WS).
Pages 4688-4698.
2025.
[bibtex]
[doi]
[abstract]
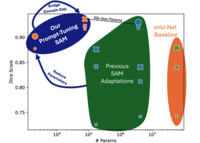
The Segment Anything Model (SAM) is widely used for segmenting a diverse range of objects in natural images from simple user prompts like points or bounding boxes. However, SAM's performance decreases substantially when applied to non-natural domains like microscopic imaging. Furthermore, due to SAM's interactive design, it requires a precise prompt for each image and object, which is un-feasible in many automated biomedical applications. Previous solutions adapt SAM by training millions of parameters via fine-tuning large parts of the model or of adapter layers. In contrast, we show that as little as 2,048 additional parameters are sufficient for turning SAM into a usecase specialist for a certain downstream task. Our novel PTSAM (prompt-tuned SAM) method uses prompt-tuning, a parameter-efficient fine-tuning technique, to adapt SAM for a specific task. We validate the performance of our approach on multiple microscopic and one medical dataset. Our results show that prompt-tuning only SAM's mask decoder already leads to a performance on-par with state-of-the-art techniques while requiring roughly 2,000\texttimes less trainable parameters. For addressing domain gaps, we find that additionally prompt-tuning SAM's image encoder is beneficial, further improving segmentation accuracy by up to 18\% over state-of-the-art results. Since PTSAM can be reliably trained with as little as 16 annotated images, we find it particularly helpful for applications with limited training data and domain shifts.

Björn Barz, Joachim Denzler:
Weakly-Supervised Localization of Multiple Objects in Images using Cosine Loss.
International Conference on Computer Vision Theory and Applications (VISAPP).
Pages 287-296.
2022.
[bibtex]
[doi]
[abstract]
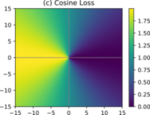
Can we learn to localize objects in images from just image-level class labels? Previous research has shown that this ability can be added to convolutional neural networks (CNNs) trained for image classification post hoc without additional cost or effort using so-called class activation maps (CAMs). However, while CAMs can localize a particular known class in the image quite accurately, they cannot detect and localize instances of multiple different classes in a single image. This limitation is a consequence of the missing comparability of prediction scores between classes, which results from training with the cross-entropy loss after a softmax activation. We find that CNNs trained with the cosine loss instead of cross-entropy do not exhibit this limitation and propose a variation of CAMs termed Dense Class Maps (DCMs) that fuse predictions for multiple classes into a coarse semantic segmentation of the scene. Even though the network has only been trained for single-label classification at the image level, DCMs allow for detecting the presence of multiple objects in an image and locating them. Our approach outperforms CAMs on the MS COCO object detection dataset by a relative increase of 27% in mean average precision.

Lorenzo Brigato, Björn Barz, Luca Iocchi, Joachim Denzler:
Image Classification with Small Datasets: Overview and Benchmark.
IEEE Access.
10 :
pp. 49233-49250.
2022.
[bibtex]
[pdf]
[web]
[doi]
[abstract]
Image classification with small datasets has been an active research area in the recent past. However, as research in this scope is still in its infancy, two key ingredients are missing for ensuring reliable and truthful progress: a systematic and extensive overview of the state of the art, and a common benchmark to allow for objective comparisons between published methods. This article addresses both issues. First, we systematically organize and connect past studies to consolidate a community that is currently fragmented and scattered. Second, we propose a common benchmark that allows for an objective comparison of approaches. It consists of five datasets spanning various domains (e.g., natural images, medical imagery, satellite data) and data types (RGB, grayscale, multispectral). We use this benchmark to re-evaluate the standard cross-entropy baseline and ten existing methods published between 2017 and 2021 at renowned venues. Surprisingly, we find that thorough hyper-parameter tuning on held-out validation data results in a highly competitive baseline and highlights a stunted growth of performance over the years. Indeed, only a single specialized method dating back to 2019 clearly wins our benchmark and outperforms the baseline classifier.

Bernd Gruner, Matthias Körschens, Björn Barz, Joachim Denzler:
Domain Adaptation and Active Learning for Fine-Grained Recognition in the Field of Biodiversity.
Findings of the CVPR Workshop on Continual Learning in Computer Vision (CLVision).
2021.
[bibtex]
[abstract]
Deep-learning methods offer unsurpassed recognition performance in a wide range of domains, including fine-grained recognition tasks. However, in most problem areas there are insufficient annotated training samples. Therefore, the topic of transfer learning respectively domain adaptation is particularly important. In this work, we investigate to what extent unsupervised domain adaptation can be used for fine-grained recognition in a biodiversity context to learn a real-world classifier based on idealized training data, e.g. preserved butterflies and plants. Moreover, we investigate the influence of different normalization layers, such as Group Normalization in combination with Weight Standardization, on the classifier. We discovered that domain adaptation works very well for fine-grained recognition and that the normalization methods have a great influence on the results. Using domain adaptation and Transferable Normalization, the accuracy of the classifier could be increased by up to 12.35 % compared to the baseline. Furthermore, the domain adaptation system is combined with an active learning component to improve the results. We compare different active learning strategies with each other. Surprisingly, we found that more sophisticated strategies provide better results than the random selection baseline for only one of the two datasets. In this case, the distance and diversity strategy performed best. Finally, we present a problem analysis of the datasets.

Björn Barz, Joachim Denzler:
Content-based Image Retrieval and the Semantic Gap in the Deep Learning Era.
ICPR Workshop on Content-Based Image Retrieval (CBIR2020).
Pages 245-260.
2021.
[bibtex]
[pdf]
[doi]
[abstract]
Content-based image retrieval has seen astonishing progress over the past decade, especially for the task of retrieving images of the same object that is depicted in the query image. This scenario is called instance or object retrieval and requires matching fine-grained visual patterns between images. Semantics, however, do not play a crucial role. This brings rise to the question: Do the recent advances in instance retrieval transfer to more generic image retrieval scenarios? To answer this question, we first provide a brief overview of the most relevant milestones of instance retrieval. We then apply them to a semantic image retrieval task and find that they perform inferior to much less sophisticated and more generic methods in a setting that requires image understanding. Following this, we review existing approaches to closing this so-called semantic gap by integrating prior world knowledge. We conclude that the key problem for the further advancement of semantic image retrieval lies in the lack of a standardized task definition and an appropriate benchmark dataset.

Björn Barz, Joachim Denzler:
WikiChurches: A Fine-Grained Dataset of Architectural Styles with Real-World Challenges.
NeurIPS 2021 Track on Datasets and Benchmarks.
2021.
[bibtex]
[pdf]
[presentation]
[abstract]
We introduce a novel dataset for architectural style classification, consisting of 9,485 images of church buildings. Both images and style labels were sourced from Wikipedia. The dataset can serve as a benchmark for various research fields, as it combines numerous real-world challenges: fine-grained distinctions between classes based on subtle visual features, a comparatively small sample size, a highly imbalanced class distribution, a high variance of viewpoints, and a hierarchical organization of labels, where only some images are labeled at the most precise level. In addition, we provide 631 bounding box annotations of characteristic visual features for 139 churches from four major categories. These annotations can, for example, be useful for research on fine-grained classification, where additional expert knowledge about distinctive object parts is often available. Images and annotations are available at: https://doi.org/10.5281/zenodo.5166986

Björn Barz, Kai Schröter, Ann-Christin Kra, Joachim Denzler:
Finding Relevant Flood Images on Twitter using Content-based Filters.
ICPR Workshop on Machine Learning Advances Environmental Science (MAES).
Pages 5-14.
2021.
[bibtex]
[pdf]
[web]
[doi]
[abstract]
The analysis of natural disasters such as floods in a timely manner often suffers from limited data due to coarsely distributed sensors or sensor failures. At the same time, a plethora of information is buried in an abundance of images of the event posted on social media platforms such as Twitter. These images could be used to document and rapidly assess the situation and derive proxy-data not available from sensors, e.g., the degree of water pollution. However, not all images posted online are suitable or informative enough for this purpose. Therefore, we propose an automatic filtering approach using machine learning techniques for finding Twitter images that are relevant for one of the following information objectives: assessing the flooded area, the inundation depth, and the degree of water pollution. Instead of relying on textual information present in the tweet, the filter analyzes the image contents directly. We evaluate the performance of two different approaches and various features on a case-study of two major flooding events. Our image-based filter is able to enhance the quality of the results substantially compared with a keyword-based filter, improving the mean average precision from 23% to 53% on average.

Clemens-Alexander Brust, Björn Barz, Joachim Denzler:
Self-Supervised Learning from Semantically Imprecise Data.
arXiv preprint arXiv:2104.10901.
2021.
[bibtex]
[pdf]
[abstract]
Learning from imprecise labels such as "animal" or "bird", but making precise predictions like "snow bunting" at test time is an important capability when expertly labeled training data is scarce. Contributions by volunteers or results of web crawling lack precision in this manner, but are still valuable. And crucially, these weakly labeled examples are available in larger quantities for lower cost than high-quality bespoke training data. CHILLAX, a recently proposed method to tackle this task, leverages a hierarchical classifier to learn from imprecise labels. However, it has two major limitations. First, it is not capable of learning from effectively unlabeled examples at the root of the hierarchy, e.g. "object". Second, an extrapolation of annotations to precise labels is only performed at test time, where confident extrapolations could be already used as training data. In this work, we extend CHILLAX with a self-supervised scheme using constrained extrapolation to generate pseudo-labels. This addresses the second concern, which in turn solves the first problem, enabling an even weaker supervision requirement than CHILLAX. We evaluate our approach empirically and show that our method allows for a consistent accuracy improvement of 0.84 to 1.19 percent points over CHILLAX and is suitable as a drop-in replacement without any negative consequences such as longer training times.

Felix Schneider, Phillip Brandes, Björn Barz, Sophie Marshall, Joachim Denzler:
Data-Driven Detection of General Chiasmi Using Lexical and Semantic Features.
SIGHUM Workshop on Computational Linguistics for Cultural Heritage, Social Sciences, Humanities and Literature.
Pages 96-100.
2021.
[bibtex]
[web]
[doi]
[abstract]
Automatic detection of stylistic devices is an important tool for literary studies, e.g., for stylometric analysis or argument mining. A particularly striking device is the rhetorical figure called chiasmus, which involves the inversion of semantically or syntactically related words. Existing works focus on a special case of chiasmi that involve identical words in an A B B A pattern, so-called antimetaboles. In contrast, we propose an approach targeting the more general and challenging case A B B’ A’, where the words A, A’ and B, B’ constituting the chiasmus do not need to be identical but just related in meaning. To this end, we generalize the established candidate phrase mining strategy from antimetaboles to general chiasmi and propose novel features based on word embeddings and lemmata for capturing both semantic and syntactic information. These features serve as input for a logistic regression classifier, which learns to distinguish between rhetorical chiasmi and coincidental chiastic word orders without special meaning. We evaluate our approach on two datasets consisting of classical German dramas, four texts with annotated chiasmi and 500 unannotated texts. Compared to previous methods for chiasmus detection, our novel features improve the average precision from 17% to 28% and the precision among the top 100 results from 13% to 35%.

Lorenzo Brigato, Björn Barz, Luca Iocchi, Joachim Denzler:
Tune It or Don't Use It: Benchmarking Data-Efficient Image Classification.
ICCV Workshop on Visual Inductive Priors for Data-Efficient Deep Learning.
2021.
[bibtex]
[pdf]
[abstract]
Data-efficient image classification using deep neural networks in settings, where only small amounts of labeled data are available, has been an active research area in the recent past. However, an objective comparison between published methods is difficult, since existing works use different datasets for evaluation and often compare against untuned baselines with default hyper-parameters. We design a benchmark for data-efficient image classification consisting of six diverse datasets spanning various domains (e.g., natural images, medical imagery, satellite data) and data types (RGB, grayscale, multispectral). Using this benchmark, we re-evaluate the standard cross-entropy baseline and eight methods for data-efficient deep learning published between 2017 and 2021 at renowned venues. For a fair and realistic comparison, we carefully tune the hyper-parameters of all methods on each dataset. Surprisingly, we find that tuning learning rate, weight decay, and batch size on a separate validation split results in a highly competitive baseline, which outperforms all but one specialized method and performs competitively to the remaining one.

Violeta Teodora Trifunov, Maha Shadaydeh, Björn Barz, Joachim Denzler:
Anomaly Attribution of Multivariate Time Series using Counterfactual Reasoning.
IEEE International Conference on Machine Learning and Applications (ICMLA).
Pages 166-172.
2021.
[bibtex]
[pdf]
[web]
[doi]
[abstract]
There are numerous methods for detecting anomalies in time series, but that is only the first step to understanding them. We strive to exceed this by explaining those anomalies. Thus we develop a novel attribution scheme for multivariate time series relying on counterfactual reasoning. We aim to answer the counterfactual question of would the anomalous event have occurred if the subset of the involved variables had been more similarly distributed to the data outside of the anomalous interval. Specifically, we detect anomalous intervals using the Maximally Divergent Interval (MDI) algorithm, replace a subset of variables with their in-distribution values within the detected interval and observe if the interval has become less anomalous, by re-scoring it with MDI. We evaluate our method on multivariate temporal and spatio-temporal data and confirm the accuracy of our anomaly attribution of multiple well-understood extreme climate events such as heatwaves and hurricanes.
Björn Barz, Joachim Denzler:
Deep Learning on Small Datasets without Pre-Training using Cosine Loss.
IEEE Winter Conference on Applications of Computer Vision (WACV).
Pages 1360-1369.
2020.
[bibtex]
[pdf]
[doi]
[code]
[abstract]
Two things seem to be indisputable in the contemporary deep learning discourse: 1. The categorical cross-entropy loss after softmax activation is the method of choice for classification. 2. Training a CNN classifier from scratch on small datasets does not work well. In contrast to this, we show that the cosine loss function provides substantially better performance than cross-entropy on datasets with only a handful of samples per class. For example, the accuracy achieved on the CUB-200-2011 dataset without pre-training is by 30% higher than with the cross-entropy loss. Further experiments on other popular datasets confirm our findings. Moreover, we demonstrate that integrating prior knowledge in the form of class hierarchies is straightforward with the cosine loss and improves classification performance further.

Björn Barz, Joachim Denzler:
Do We Train on Test Data? Purging CIFAR of Near-Duplicates.
Journal of Imaging.
6 (6) :
2020.
[bibtex]
[pdf]
[web]
[doi]
[abstract]
We find that 3.3% and 10% of the images from the CIFAR-10 and CIFAR-100 test sets, respectively, have duplicates in the training set. This may incur a bias on the comparison of image recognition techniques with respect to their generalization capability on these heavily benchmarked datasets. To eliminate this bias, we provide the "fair CIFAR" (ciFAIR) dataset, where we replaced all duplicates in the test sets with new images sampled from the same domain. The training set remains unchanged, in order not to invalidate pre-trained models. We then re-evaluate the classification performance of various popular state-of-the-art CNN architectures on these new test sets to investigate whether recent research has overfitted to memorizing data instead of learning abstract concepts. We find a significant drop in classification accuracy of between 9% and 14% relative to the original performance on the duplicate-free test set. The ciFAIR dataset and pre-trained models are available at https://cvjena.github.io/cifair/, where we also maintain a leaderboard.

Clemens-Alexander Brust, Björn Barz, Joachim Denzler:
Making Every Label Count: Handling Semantic Imprecision by Integrating Domain Knowledge.
International Conference on Pattern Recognition (ICPR).
2020.
[bibtex]
[pdf]
[doi]
[abstract]
Noisy data, crawled from the web or supplied by volunteers such as Mechanical Turkers or citizen scientists, is considered an alternative to professionally labeled data. There has been research focused on mitigating the effects of label noise. It is typically modeled as inaccuracy, where the correct label is replaced by an incorrect label from the same set. We consider an additional dimension of label noise: imprecision. For example, a non-breeding snow bunting is labeled as a bird. This label is correct, but not as precise as the task requires. Standard softmax classifiers cannot learn from such a weak label because they consider all classes mutually exclusive, which non-breeding snow bunting and bird are not. We propose CHILLAX (Class Hierarchies for Imprecise Label Learning and Annotation eXtrapolation), a method based on hierarchical classification, to fully utilize labels of any precision. Experiments on noisy variants of NABirds and ILSVRC2012 show that our method outperforms strong baselines by as much as 16.4 percentage points, and the current state of the art by up to 3.9 percentage points.

Björn Barz, Erik Rodner, Yanira Guanche Garcia, Joachim Denzler:
Detecting Regions of Maximal Divergence for Spatio-Temporal Anomaly Detection.
IEEE Transactions on Pattern Analysis and Machine Intelligence.
41 (5) :
pp. 1088-1101.
2019.
(Pre-print published in 2018.)
[bibtex]
[pdf]
[web]
[doi]
[code]
[abstract]
Automatic detection of anomalies in space- and time-varying measurements is an important tool in several fields, e.g., fraud detection, climate analysis, or healthcare monitoring. We present an algorithm for detecting anomalous regions in multivariate spatio-temporal time-series, which allows for spotting the interesting parts in large amounts of data, including video and text data. In opposition to existing techniques for detecting isolated anomalous data points, we propose the "Maximally Divergent Intervals" (MDI) framework for unsupervised detection of coherent spatial regions and time intervals characterized by a high Kullback-Leibler divergence compared with all other data given. In this regard, we define an unbiased Kullback-Leibler divergence that allows for ranking regions of different size and show how to enable the algorithm to run on large-scale data sets in reasonable time using an interval proposal technique. Experiments on both synthetic and real data from various domains, such as climate analysis, video surveillance, and text forensics, demonstrate that our method is widely applicable and a valuable tool for finding interesting events in different types of data.
Björn Barz, Joachim Denzler:
Hierarchy-based Image Embeddings for Semantic Image Retrieval.
IEEE Winter Conference on Applications of Computer Vision (WACV).
Pages 638-647.
2019.
Best Paper Award
[bibtex]
[pdf]
[web]
[doi]
[code]
[presentation]
[supplementary]
[abstract]
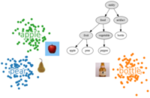
Deep neural networks trained for classification have been found to learn powerful image representations, which are also often used for other tasks such as comparing images w.r.t. their visual similarity. However, visual similarity does not imply semantic similarity. In order to learn semantically discriminative features, we propose to map images onto class embeddings whose pair-wise dot products correspond to a measure of semantic similarity between classes. Such an embedding does not only improve image retrieval results, but could also facilitate integrating semantics for other tasks, e.g., novelty detection or few-shot learning. We introduce a deterministic algorithm for computing the class centroids directly based on prior world-knowledge encoded in a hierarchy of classes such as WordNet. Experiments on CIFAR-100, NABirds, and ImageNet show that our learned semantic image embeddings improve the semantic consistency of image retrieval results by a large margin.

Björn Barz, Prerana Mukherjee, Brejesh Lall, Elham Vahdati:
Diverse Perspectives on the Relationship between Artificial Intelligence and Pattern Recognition.
Frontiers in Pattern Recognition and Artificial Intelligence.
Pages 23-34.
2019.
[bibtex]
[web]
[doi]
[abstract]
The International Conference on Artificial Intelligence and Pattern Recognition (ICPRAI 2018) brought together scholars to celebrate works on artificial intelligence and pattern recognition. In acknowledgment that two terms are closely related and are sometimes used interchangeably, a Competition was set up as part of the conference whereby attendees were invited to submit a response to the following question: What is the relation between Artificial Intelligence and Pattern Recognition? This chapter includes the top three responses as judged by the ICPRAI 2018 Competition Committee. Barz argues that intelligence goes far beyond pattern recognition, while pattern recognition is an essential prerequisite for any intelligence, artificial or not. Mukherjee and Lall outlines the inter-related concepts in AI and PR and various potential use-cases. Lastly, Elham provides her perspective, which includes seeing pattern recognition as a starting point or a principle of discovery of artificial intelligence developments.
Björn Barz, Joachim Denzler:
Automatic Query Image Disambiguation for Content-Based Image Retrieval.
International Conference on Computer Vision Theory and Applications (VISAPP).
Pages 249-256.
2018.
[bibtex]
[pdf]
[doi]
[code]
[abstract]
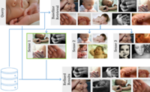
Query images presented to content-based image retrieval systems often have various different interpretations, making it difficult to identify the search objective pursued by the user. We propose a technique for overcoming this ambiguity, while keeping the amount of required user interaction at a minimum. To achieve this, the neighborhood of the query image is divided into coherent clusters from which the user may choose the relevant ones. A novel feedback integration technique is then employed to re-rank the entire database with regard to both the user feedback and the original query. We evaluate our approach on the publicly available MIRFLICKR-25K dataset, where it leads to a relative improvement of average precision by 23% over the baseline retrieval, which does not distinguish between different image senses.

Björn Barz, Joachim Denzler:
Deep Learning is not a Matter of Depth but of Good Training.
International Conference on Pattern Recognition and Artificial Intelligence (ICPRAI).
Pages 683-687.
2018.
[bibtex]
[pdf]
[abstract]
In the past few years, deep neural networks have often been claimed to provide greater representational power than shallow networks. In this work, we propose a wide, shallow, and strictly sequential network architecture without any residual connections. When trained with cyclical learning rate schedules, this simple network achieves a classification accuracy on CIFAR-100 competitive to a 10 times deeper residual network, while it can be trained 4 times faster. This provides evidence that neither depth nor residual connections are crucial for deep learning. Instead, residual connections just seem to facilitate training using plain SGD by avoiding bad local minima. We believe that our work can hence point the research community to the actual bottleneck of contemporary deep learning: the optimization algorithms.

Björn Barz, Kai Schröter, Moritz Münch, Bin Yang, Andrea Unger, Doris Dransch, Joachim Denzler:
Enhancing Flood Impact Analysis using Interactive Retrieval of Social Media Images.
Archives of Data Science, Series A.
5 (1) :
pp. A06, 21 S. online.
2018.
[bibtex]
[pdf]
[doi]
[abstract]
The analysis of natural disasters such as floods in a timely manner often suffers from limited data due to a coarse distribution of sensors or sensor failures. This limitation could be alleviated by leveraging information contained in images of the event posted on social media platforms, so-called "Volunteered Geographic Information (VGI)". To save the analyst from the need to inspect all images posted online manually, we propose to use content-based image retrieval with the possibility of relevance feedback for retrieving only relevant images of the event to be analyzed. To evaluate this approach, we introduce a new dataset of 3,710 flood images, annotated by domain experts regarding their relevance with respect to three tasks (determining the flooded area, inundation depth, water pollution). We compare several image features and relevance feedback methods on that dataset, mixed with 97,085 distractor images, and are able to improve the precision among the top 100 retrieval results from 55% with the baseline retrieval to 87% after 5 rounds of feedback.
Björn Barz, Thomas C. van Dijk, Bert Spaan, Joachim Denzler:
Putting User Reputation on the Map: Unsupervised Quality Control for Crowdsourced Historical Data.
2nd ACM SIGSPATIAL Workshop on Geospatial Humanities.
Pages 3:1-3:6.
2018.
[bibtex]
[pdf]
[doi]
[abstract]
In this paper we propose a novel method for quality assessment of crowdsourced data. It computes user reputation scores without requiring ground truth; instead, it is based on the consistency among users. In this pilot study, we perform some explorative data analysis on two real crowdsourcing projects by the New York Public Library: extracting building footprints as polygons from historical insurance atlases, and geolocating historical photographs. We show that the computed reputation scores are plausible and furthermore provide insight into user behavior.

Christoph Käding, Erik Rodner, Alexander Freytag, Oliver Mothes, Björn Barz, Joachim Denzler:
Active Learning for Regression Tasks with Expected Model Output Changes.
British Machine Vision Conference (BMVC).
2018.
[bibtex]
[pdf]
[code]
[supplementary]
[abstract]
Annotated training data is the enabler for supervised learning. While recording data at large scale is possible in some application domains, collecting reliable annotations is time-consuming, costly, and often a project's bottleneck. Active learning aims at reducing the annotation effort. While this field has been studied extensively for classification tasks, it has received less attention for regression problems although the annotation cost is often even higher. We aim at closing this gap and propose an active learning approach to enable regression applications. To address continuous outputs, we build on Gaussian process models -- an established tool to tackle even non-linear regression problems. For active learning, we extend the expected model output change (EMOC) framework to continuous label spaces and show that the involved marginalizations can be solved in closed-form. This mitigates one of the major drawbacks of the EMOC principle. We empirically analyze our approach in a variety of application scenarios. In summary, we observe that our approach can efficiently guide the annotation process and leads to better models in shorter time and at lower costs.

Matthias Körschens, Björn Barz, Joachim Denzler:
Towards Automatic Identification of Elephants in the Wild.
AI for Wildlife Conservation Workshop (AIWC).
2018.
[bibtex]
[pdf]
[abstract]
Identifying animals from a large group of possible individuals is very important for biodiversity monitoring and especially for collecting data on a small number of particularly interesting individuals, as these have to be identified first before this can be done. Identifying them can be a very time-consuming task. This is especially true, if the animals look very similar and have only a small number of distinctive features, like elephants do. In most cases the animals stay at one place only for a short period of time during which the animal needs to be identified for knowing whether it is important to collect new data on it. For this reason, a system supporting the researchers in identifying elephants to speed up this process would be of great benefit. In this paper, we present such a system for identifying elephants in the face of a large number of individuals with only few training images per individual. For that purpose, we combine object part localization, off-the-shelf CNN features, and support vector machine classification to provide field researches with proposals of possible individuals given new images of an elephant. The performance of our system is demonstrated on a dataset comprising a total of 2078 images of 276 individual elephants, where we achieve 56% top-1 test accuracy and 80% top-10 accuracy. To deal with occlusion, varying viewpoints, and different poses present in the dataset, we furthermore enable the analysts to provide the system with multiple images of the same elephant to be identified and aggregate confidence values generated by the classifier. With that, our system achieves a top-1 accuracy of 74% and a top-10 accuracy of 88% on the held-out test dataset.
Björn Barz, Yanira Guanche, Erik Rodner, Joachim Denzler:
Maximally Divergent Intervals for Extreme Weather Event Detection.
MTS/IEEE OCEANS Conference Aberdeen.
Pages 1-9.
2017.
[bibtex]
[pdf]
[doi]
[abstract]
We approach the task of detecting anomalous or extreme events in multivariate spatio-temporal climate data using an unsupervised machine learning algorithm for detection of anomalous intervals in time-series. In contrast to many existing algorithms for outlier and anomaly detection, our method does not search for point-wise anomalies, but for contiguous anomalous intervals. We demonstrate the suitability of our approach through numerous experiments on climate data, including detection of hurricanes, North Sea storms, and low-pressure fields.
Erik Rodner, Björn Barz, Yanira Guanche, Milan Flach, Miguel Mahecha, Paul Bodesheim, Markus Reichstein, Joachim Denzler:
Maximally Divergent Intervals for Anomaly Detection.
Workshop on Anomaly Detection (ICML-WS).
2016.
Best Paper Award
[bibtex]
[pdf]
[web]
[code]
[abstract]
We present new methods for batch anomaly detection in multivariate time series. Our methods are based on maximizing the Kullback-Leibler divergence between the data distribution within and outside an interval of the time series. An empirical analysis shows the benefits of our algorithms compared to methods that treat each time step independently from each other without optimizing with respect to all possible intervals.
Björn Barz, Erik Rodner, Joachim Denzler:
ARTOS -- Adaptive Real-Time Object Detection System.
arXiv preprint arXiv:1407.2721.
2014.
[bibtex]
[pdf]
[web]
[code]
[abstract]
ARTOS is all about creating, tuning, and applying object detection models with just a few clicks. In particular, ARTOS facilitates learning of models for visual object detection by eliminating the burden of having to collect and annotate a large set of positive and negative samples manually and in addition it implements a fast learning technique to reduce the time needed for the learning step. A clean and friendly GUI guides the user through the process of model creation, adaptation of learned models to different domains using in-situ images, and object detection on both offline images and images from a video stream. A library written in C++ provides the main functionality of ARTOS with a C-style procedural interface, so that it can be easily integrated with any other project.