Felix Schneider, Sven Sickert, Phillip Brandes, Sophie Marshall, Joachim Denzler:
Hard is the Task, the Samples are Few: A German Chiasmus Dataset.
Language Technology Conference: Human Language Technologies as a Challenge for Computer Science and Linguistics (LTC).
Pages 255-260.
2023.
[bibtex]
[pdf]
[doi]
[code]
[abstract]
In this work we present a novel German language dataset for the detection of the stylistic device called chiasmus collected from German dramas. The dataset includes phrases labeled as chiasmi, antimetaboles, semantically unrelated inversions, and various edge cases. The dataset was created by collecting examples from the GerDraCor dataset. We test different approaches for chiasmus detection on the samples and report an average precision of 0.74 for the best method. Additionally, we give an overview about related approaches and the current state of the research on chiasmus detection.

Felix Schneider, Phillip Brandes, Björn Barz, Sophie Marshall, Joachim Denzler:
Data-Driven Detection of General Chiasmi Using Lexical and Semantic Features.
SIGHUM Workshop on Computational Linguistics for Cultural Heritage, Social Sciences, Humanities and Literature.
Pages 96-100.
2021.
[bibtex]
[web]
[doi]
[abstract]
Automatic detection of stylistic devices is an important tool for literary studies, e.g., for stylometric analysis or argument mining. A particularly striking device is the rhetorical figure called chiasmus, which involves the inversion of semantically or syntactically related words. Existing works focus on a special case of chiasmi that involve identical words in an A B B A pattern, so-called antimetaboles. In contrast, we propose an approach targeting the more general and challenging case A B B’ A’, where the words A, A’ and B, B’ constituting the chiasmus do not need to be identical but just related in meaning. To this end, we generalize the established candidate phrase mining strategy from antimetaboles to general chiasmi and propose novel features based on word embeddings and lemmata for capturing both semantic and syntactic information. These features serve as input for a logistic regression classifier, which learns to distinguish between rhetorical chiasmi and coincidental chiastic word orders without special meaning. We evaluate our approach on two datasets consisting of classical German dramas, four texts with annotated chiasmi and 500 unannotated texts. Compared to previous methods for chiasmus detection, our novel features improve the average precision from 17% to 28% and the precision among the top 100 results from 13% to 35%.
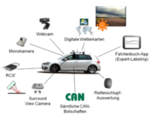
Waldemar Jarisa, Roman Henze, Ferit Kücükay, Felix Schneider, Joachim Denzler, Bernd Hartmann:
Fusionskonzept zur Reibwertschätzung auf Basis von Wetter- und Fahrbahnzustandsinformationen.
VDI-Fachtagung Reifen - Fahrwerk - Fahrbahn.
2019.
Best Paper Award
[bibtex]
[abstract]
Die Fahrsicherheit ist ein zentrales Entwicklungsziel in der Automobilindustrie, welches mit dem automatisierten Fahren vor neuen Herausforderungen steht. Um die Fahrsicherheit zu gewährleisten, bedarf es einer genauen Kenntnis der unmittelbaren Fahrumgebung. Die Fahrumgebung setzt sich dabei aus mehreren Komponenten zusammen. Neben der Straßentopologie und den Verkehrsteilnehmern kommt der Kenntnis über den Fahrbahnzustand, in Form von trockenen, nassen oder schnee- und eisbedeckten Straßen, eine große Bedeutung zu. Im Rahmen dieser Arbeit werden in Kooperation mit der Friedrich-Schiller-Universität Jena und beauftragt durch die Continental AG Fusionskonzepte zur Fahrbahnzustandsklassifikation entwickelt, welche den Fahrbahnzustand, respektive den Reibwert, innerhalb der Gruppen trocken, nass und winterlich differenzieren. Grundlage für die Modellentwicklung sind Messdaten einer Messkampagne (ca. 6455 km) auf realen Straßen bei unterschiedlichsten Straßenzuständen und Witterungsbedingungen mit einem Versuchsträger des Instituts für Fahrzeugtechnik. Dieser ist in der Lage, auf unterschiedlichen Informationsebenen, bestehend aus digitalen Wetterkarten, Umfelddaten, Kamera- und Fahrdynamikinformationen sowie optional auch Laserdaten, den Fahrbahnzustand zu klassifizieren. Dabei wird jeweils ein Klassifikationsalgorithmus auf Basis der Frontkamera- als auch der Surround-View-Kamerabilder im rechten Außenspiegel verwendet. Die aufgezeichneten Signale werden mit einander fusioniert, um einerseits die Verfügbarkeit und andererseits die Genauigkeit der Fahrbahnzustandsklassifikation zu gewährleisten. Hierzu werden die Möglichkeiten zur frühen Fusion von Kamerabildern unter Berücksichtigung von Kontextwissen, wie z. B. Luft- oder Fahrbahntemperatur mittels Deep-Learning-Ansätzen untersucht. Abschließend wird der Zusammenhang zwischen dem tatsächlichen Fahrbahnzustand und einer maximalen Kraftschlussausnutzung anhand einer repräsentativen Anzahl von ABS-Bremsungen evaluiert.