
Gideon Stein, Niklas Penzel, Tristan Piater, Joachim Denzler:
TCD-Arena: Assessing Robustness of Time Series Causal Discovery Methods Against Assumption Violations.
International Conference on Learning Representations (ICLR).
2026.
[bibtex]
[web]
[abstract]
Causal Discovery (CD) is a powerful framework for scientific inquiry. Yet, its practical adoption is hindered by a reliance on strong, often unverifiable assumptions and a lack of robust performance assessment. To address these limitations and advance empirical CD evaluation, we present TCD-Arena, a modularized and extendable testing kit to assess the robustness of time series CD algorithms against stepwise more severe assumption violations. For demonstration, we conduct an extensive empirical study comprising arround 30 million individual CD attempts and reveal nuanced robustness profiles for 33 distinct assumption violations. Further, we investigate CD ensembles and find that they can boost general robustness, which has implications for real-world applications. With this, we strive to ultimately facilitate the development of CD methods that are reliable for a diverse range of synthetic and potentially real-world data conditions.
Laines Schmalwasser, Jan Blunk, Niklas Penzel, Julia Niebling, Joachim Denzler:
On the Faithfulness of Post-Hoc Concept Bottleneck Models.
European Conference on Computer Vision (ECCV).
2026.
(accepted)
[bibtex]
[web]
[abstract]
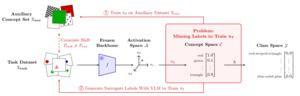
Human decision-making interprets the world through high-level concepts, such as recognizing a bird by its belly color. To bridge the gap between opaque deep learning representations and human understanding, Post-Hoc Concept Bottleneck Models (post-hoc CBMs) project latent features onto interpretable concept spaces using auxiliary datasets or vision-language models. However, relying on target task accuracy as the primary measure of post-hoc CBM success obscures whether the learned concepts are semantically meaningful or merely predictive artifacts. For example, random concept projections can achieve competitive accuracy despite being semantically meaningless. In this work, we analyze the learned projections directly and identify two failure cases: First, for concept projections learned from auxiliary data, covariate shifts can lead to unfaithful concept representations for the target task. In particular, we provide an upper bound on the error introduced by this shift. Second, systematic label noise in surrogate concept labels generated by vision-language models leads to unfaithful projections. After formalizing these failure modes, we introduce novel metrics that decouple concept faithfulness from predictive accuracy. Our empirical results across real-world and synthetic benchmarks confirm that these metrics identify unfaithful behaviors that standard accuracy-based evaluation fails to detect.
Niklas Penzel, Daniel Scheliga, Hannes Oppermann, Patrick Mäder, Jens Haueisen, Joachim Denzler, Marco Seeland:
Model utility and explainability in federated learning - A case study in healthcare using fundus oculi datasets.
Journal of Biomedical Informatics.
177 :
pp. 105010.
2026.
[bibtex]
[web]
[doi]
[abstract]
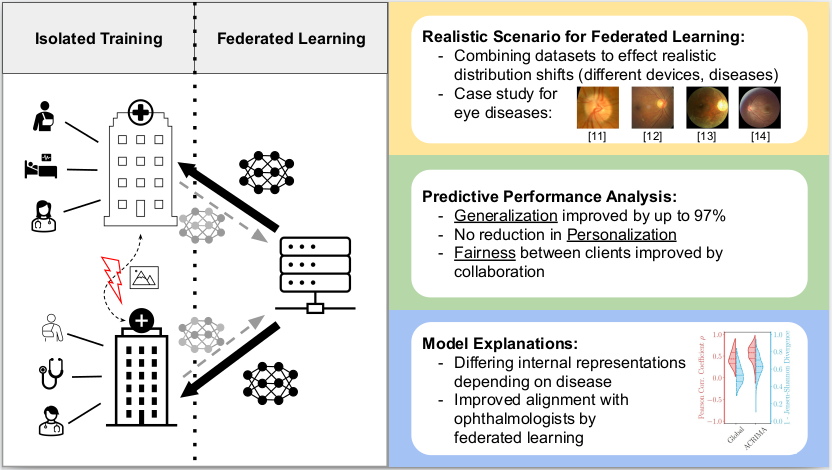
Objective: Introduce a case study for Federated Learning (FL) in healthcare, addressing challenges posed by patient privacy and limited large-scale datasets. Our goal is to assess the features learned by FL methods in a simulated, diverse setting that emphasizes realistic data heterogeneity, and to analyze the learned representations for their medical relevance using both local and global explainability techniques. Methods: Six fundus oculi datasets were combined to simulate a diverse federated learning environment, representing heterogeneous data conditions. We evaluated three established FL methods against centrally trained models, assessing both predictive performance and the learned representations. Specifically, explainability techniques were employed to examine the features learned by the models, and local explanations were evaluated against attention maps annotated by ophthalmologists. Robustness against common biases in fundus datasets was also assessed. Results: Our study found improvements in model utility (up to 9.97%) with FL methods compared to isolated training. Analysis of learned representations revealed that federated models predominantly learn the vertical cup-to-disc ratio, a crucial feature for glaucoma diagnosis, and demonstrated robustness against common biases. High agreement was observed between local explanations and ophthalmologist-annotated attention maps. Conclusion: This study demonstrates the benefits of FL systems in a healthcare scenario, providing a case study for evaluating federated systems beyond idealized benchmarks. Our findings highlight the potential of FL to not only improve model utility in privacy-sensitive medical domains but also to learn medically relevant features instead of spurious correlations.
Niklas Penzel, Gideon Stein, Joachim Denzler:
Change Penalized Tuning to Reduce Pre-trained Biases.
Computer Vision, Imaging and Computer Graphics Theory and Applications.
Pages 223-238.
2026.
[bibtex]
[web]
[doi]
[abstract]
Due to the data-centric approach of modern machine learning, biases present in the training data are frequently learned by deep models. It is often necessary to collect new data and retrain the models from scratch to remedy these issues, which can be expensive in critical areas such as medicine. We investigate whether it is possible to fix pre-trained model behavior using very few unbiased examples. We show that we can improve performance by tuning the models while penalizing parameter changes. Hence, we are keeping pre-trained knowledge while simultaneously correcting the harmful behavior. Toward this goal, we tune a zero-initialized copy of the frozen pre-trained network using strong parameter norms. Secondly, we introduce an early stopping scheme to modify baselines and reduce overfitting. Our approaches lead to improvements in four datasets common in the debiasing and domain shift literature. We especially see benefits in an iterative setting, where new samples are added continuously. Hence, we demonstrate the effectiveness of tuning while penalizing change to fix pre-trained models without retraining from scratch.
Niklas Penzel, Joachim Denzler:
Locally Explaining Prediction Behavior via Gradual Interventions and Measuring Property Gradients.
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV).
Pages 7398-7408.
2026.
[bibtex]
[web]
[doi]
[abstract]
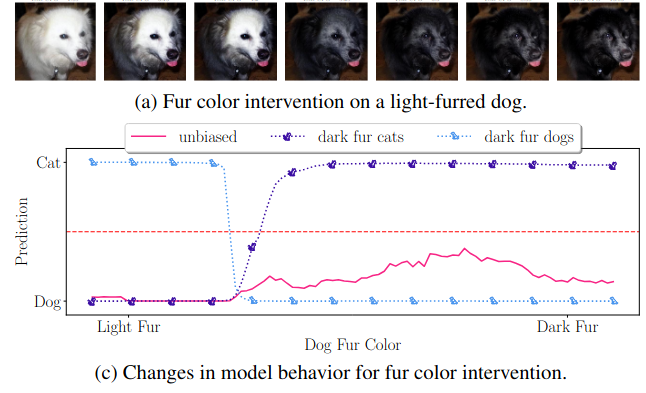
Deep learning models achieve high predictive performance but lack intrinsic interpretability, hindering our understanding of the learned prediction behavior. Existing local explainability methods focus on associations, neglecting the causal drivers of model predictions. Other approaches adopt a causal perspective but primarily provide more general global explanations. However, for specific inputs, it's unclear whether globally identified factors apply locally. To address this limitation, we introduce a novel framework for local interventional explanations by leveraging recent advances in image-to-image editing models. Our approach performs gradual interventions on semantic properties to quantify the corresponding impact on a model's predictions using a novel score, the expected property gradient magnitude. We demonstrate the effectiveness of our approach through an extensive empirical evaluation on a wide range of architectures and tasks. First, we validate it in a synthetic scenario and demonstrate its ability to locally identify biases. Afterward, we apply our approach to analyze network training dynamics, investigate medical skin lesion classifiers, and study a pre-trained CLIP model with real-life interventional data. Our results highlight the potential of interventional explanations on the property level to reveal new insights into the behavior of deep models.
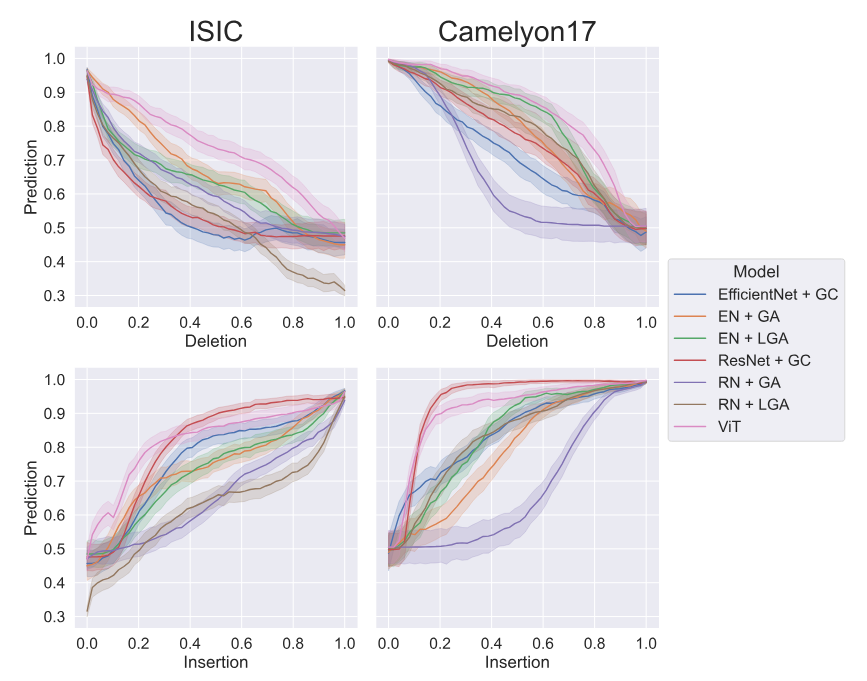
Tristan Piater, Niklas Penzel, Gideon Stein, Joachim Denzler:
Self-Attention for Medical Imaging - On the need for evaluations beyond mere benchmarking.
Computer Vision, Imaging and Computer Graphics Theory and Applications.
Pages 259-275.
2026.
[bibtex]
[web]
[doi]
[abstract]
A considerable amount of research has been dedicated to creating systems that aid medical professionals in labor-intensive early screening tasks, which, to this date, often leverage convolutional deep-learning architectures. Recently, several studies have explored the application of self-attention mechanisms in the field of computer vision. These studies frequently demonstrate empirical improvements over traditional, fully convolutional approaches across a range of datasets and tasks. To assess this trend for medical imaging, we enhance two commonly used convolutional architectures with various self-attention mechanisms and evaluate them on two distinct medical datasets. We compare these enhanced architectures with similarly sized convolutional and attention-based baselines and rigorously assess performance gains through statistical evaluation. Furthermore, we investigate how the inclusion of self-attention influences the features learned by these models by assessing global and local explanations of model behavior. Contrary to our expectations, after performing an appropriate hyperparameter search, self-attention-enhanced architectures show no significant improvements in balanced accuracy compared to the evaluated baselines. Further, we find that relevant global features like dermoscopic structures in skin lesion images are not properly learned by any architecture. Finally, by assessing local explanations, we find that the inherent interpretability of self-attention mechanisms does not provide additional insights. Out-of-the-box model-agnostic approaches can provide explanations that are similar or even more faithful to the actual model behavior. We conclude that simply integrating attention mechanisms is unlikely to lead to a consistent increase in performance compared to fully convolutional methods in medical imaging applications.

Gideon Stein, Maha Shadaydeh, Jan Blunk, Niklas Penzel, Joachim Denzler:
CausalRivers - Scaling Up Benchmarking of Causal Discovery for Real-world Time-series.
International Conference on Learning Representations (ICLR).
2025.
[bibtex]
[pdf]
[web]
[doi]
[abstract]
Causal discovery, or identifying causal relationships from observational data, is a notoriously challenging task, with numerous methods proposed to tackle it. Despite this, in-the-wild evaluation of these methods is still lacking, as works frequently rely on synthetic data evaluation and sparse real-world examples under critical theoretical assumptions. Real-world causal structures, however, are often complex, evolving over time, non-linear, and influenced by unobserved factors, making it hard to decide on a proper causal discovery strategy. To bridge this gap, we introduce CausalRivers, the largest in-the-wild causal discovery benchmarking kit for time-series data to date. CausalRivers features an extensive dataset on river discharge that covers the eastern German territory (666 measurement stations) and the state of Bavaria (494 measurement stations). It spans the years 2019 to 2023 with a 15-minute temporal resolution. Further, we provide additional data from a flood around the Elbe River, as an event with a pronounced distributional shift. Leveraging multiple sources of information and time-series meta-data, we constructed two distinct causal ground truth graphs (Bavaria and eastern Germany). These graphs can be sampled to generate thousands of subgraphs to benchmark causal discovery across diverse and challenging settings. To demonstrate the utility of CausalRivers, we evaluate several causal discovery approaches through a set of experiments to identify areas for improvement. CausalRivers has the potential to facilitate robust evaluations and comparisons of causal discovery methods. Besides this primary purpose, we also expect that this dataset will be relevant for connected areas of research, such as time-series forecasting and anomaly detection. Based on this, we hope to push benchmark-driven method development that fosters advanced techniques for causal discovery, as is the case for many other areas of machine learning.

Laines Schmalwasser, Niklas Penzel, Joachim Denzler, Julia Niebling:
FastCAV: Efficient Computation of Concept Activation Vectors for Explaining Deep Neural Networks.
International Conference on Machine Learning (ICML).
2025.
[bibtex]
[web]
[abstract]
Concepts such as objects, patterns, and shapes are how humans understand the world. Building on this intuition, concept-based explainability methods aim to study representations learned by deep neural networks in relation to human-understandable concepts. Here, Concept Activation Vectors (CAVs) are an important tool and can identify whether a model learned a concept or not. However, the computational cost and time requirements of existing CAV computation pose a significant challenge, particularly in large-scale, high-dimensional architectures. To address this limitation, we introduce \methodname, a novel approach that accelerates the extraction of CAVs by up to \maxspeedup (on average \avgspeedup). \%times. We provide a theoretical foundation for our approach and give concrete assumptions under which it is equivalent to established SVM-based methods. Our empirical results demonstrate that CAVs calculated with \methodname maintain similar performance while being more efficient and stable. In downstream applications, i.e., concept-based explanation methods, we show that \methodname can act as a replacement leading to equivalent insights. Hence, our approach enables previously infeasible investigations of deep models, which we demonstrate by tracking the evolution of concepts during model training.
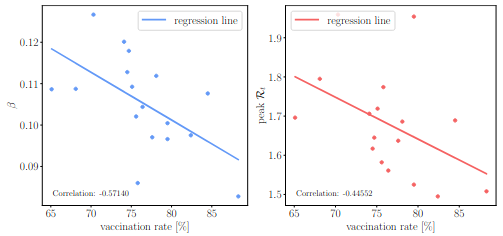
Phillip Rothenbeck, Sai Karthikeya Vemuri, Niklas Penzel, Joachim Denzler:
Modeling COVID-19 Dynamics in German States Using Physics-Informed Neural Networks.
EurIPS Workshop on Differentiable Systems and Scientific Machine Learning (EurIPS-WS).
2025.
[bibtex]
[pdf]
[doi]
[abstract]
The COVID-19 pandemic has highlighted the need for quantitative modeling and analysis to understand real-world disease dynamics. In particular, post hoc analyses using compartmental models offer valuable insights into the effectiveness of public health interventions, such as vaccination strategies and containment policies. However, such compartmental models like SIR (Susceptible-Infectious-Recovered) often face limitations in directly incorporating noisy observational data. In this work, we employ Physics-Informed Neural Networks (PINNs) to solve the inverse problem of the SIR model using infection data from the Robert Koch Institute (RKI). Our main contribution is a fine-grained, spatio-temporal analysis of COVID-19 dynamics across all German federal states over a three-year period. We estimate state-specific transmission and recovery parameters and time-varying reproduction number (R\_t) to track the pandemic progression. The results highlight strong variations in transmission behavior across regions, revealing correlations with vaccination uptake and temporal patterns associated with major pandemic phases. Our findings demonstrate the utility of PINNs in localized, long-term epidemiological modeling.

Sven Sickert, Maria Gogolev, Niklas Penzel, Tim Büchner, Joachim Denzler:
Modifying Generative Distributions in Latent Diffusion Models to Improve Alignment with Desired Properties.
International Conference on Machine Vision and Applications (MVA).
Pages 1-6.
2025.
[bibtex]
[doi]
[presentation]
[abstract]
Models like DALL-E and Stable Diffusion substantially improved image generation. While visually convincing, they still exhibit distinct differences compared to real-world images and desired image distributions. Previous studies already identified issues at a spectral level. We also find discrepancies in terms of style authenticity and aesthetics. Based on these insights we investigate three distinct strategies to modify such models and enhance their alignment for selected image distributions of artworks. First, prompt optimization can be done without updating the model, but has limited efficacy. Fine-tuning the U-Net component can enhance denoising capabilities, leading to improved image quality. Finally, modifying the image decoder can help correct spectral misalignments. Our experiments on the ArtEmis dataset using three complementary measures show that high-frequency artifacts remain challenging, but alignment can usually be improved by at least 10\%.

Niklas Penzel, Gideon Stein, Joachim Denzler:
Reducing Bias in Pre-trained Models by Tuning while Penalizing Change.
International Conference on Computer Vision Theory and Applications (VISAPP).
Pages 90-101.
2024.
[bibtex]
[web]
[doi]
[abstract]
Deep models trained on large amounts of data often incorporate implicit biases present during training time. If later such a bias is discovered during inference or deployment, it is often necessary to acquire new data and retrain the model. This behavior is especially problematic in critical areas such as autonomous driving or medical decision-making. In these scenarios, new data is often expensive and hard to come by. In this work, we present a method based on change penalization that takes a pre-trained model and adapts the weights to mitigate a previously detected bias. We achieve this by tuning a zero-initialized copy of a frozen pre-trained network. Our method needs very few, in extreme cases only a single, examples that contradict the bias to increase performance. Additionally, we propose an early stopping criterion to modify baselines and reduce overfitting. We evaluate our approach on a well-known bias in skin lesion classification and three other datasets from the domain shift literature. We find that our approach works especially well with very few images. Simple fine-tuning combined with our early stopping also leads to performance benefits for a larger number of tuning samples.

Tim Büchner, Niklas Penzel, Orlando Guntinas-Lichius, Joachim Denzler:
Facing Asymmetry - Uncovering the Causal Link between Facial Symmetry and Expression Classifiers using Synthetic Interventions.
Asian Conference on Computer Vision (ACCV).
2024.
[bibtex]
[pdf]
[web]
[doi]
[abstract]
Understanding expressions is vital for deciphering human behavior, and nowadays, end-to-end trained black box models achieve high performance. Due to the black-box nature of these models, it is unclear how they behave when applied out-of-distribution. Specifically, these models show decreased performance for unilateral facial palsy patients. We hypothesize that one crucial factor guiding the internal decision rules is facial symmetry. In this work, we use insights from causal reasoning to investigate the hypothesis. After deriving a structural causal model, we develop a synthetic interventional framework. This approach allows us to analyze how facial symmetry impacts a network's output behavior while keeping other factors fixed. All 17 investigated expression classifiers significantly lower their output activations for reduced symmetry. This result is congruent with observed behavior on real-world data from healthy subjects and facial palsy patients. As such, our investigation serves as a case study for identifying causal factors that influence the behavior of black-box models.

Tim Büchner, Niklas Penzel, Orlando Guntinas-Lichius, Joachim Denzler:
The Power of Properties: Uncovering the Influential Factors in Emotion Classification.
International Conference on Pattern Recognition and Artificial Intelligence (ICPRAI).
2024.
[bibtex]
[pdf]
[web]
[doi]
[abstract]
Facial expression-based human emotion recognition is a critical research area in psychology and medicine. State-of-the-art classification performance is only reached by end-to-end trained neural networks. Nevertheless, such black-box models lack transparency in their decisionmaking processes, prompting efforts to ascertain the rules that underlie classifiers' decisions. Analyzing single inputs alone fails to expose systematic learned biases. These biases can be characterized as facial properties summarizing abstract information like age or medical conditions. Therefore, understanding a model's prediction behaviorrequires an analysis rooted in causality along such selected properties. We demonstrate that up to 91.25\% of classifier output behavior changes are statistically significant concerning basic properties. Among those are age, gender, and facial symmetry. Furthermore, the medical usage of surface electromyography significantly influences emotion prediction. We introduce a workflow to evaluate explicit properties and their impact. These insights might help medical professionals select and apply classifiers regarding their specialized data and properties.

Tristan Piater, Niklas Penzel, Gideon Stein, Joachim Denzler:
When Medical Imaging Met Self-Attention: A Love Story That Didn't Quite Work Out.
International Conference on Computer Vision Theory and Applications (VISAPP).
Pages 149-158.
2024.
[bibtex]
[web]
[doi]
[abstract]
A substantial body of research has focused on developing systems that assist medical professionals during labor-intensive early screening processes, many based on convolutional deep-learning architectures. Recently, multiple studies explored the application of so-called self-attention mechanisms in the vision domain. These studies often report empirical improvements over fully convolutional approaches on various datasets and tasks. To evaluate this trend for medical imaging, we extend two widely adopted convolutional architectures with different self-attention variants on two different medical datasets. With this, we aim to specifically evaluate the possible advantages of additional self-attention. We compare our models with similarly sized convolutional and attention-based baselines and evaluate performance gains statistically. Additionally, we investigate how including such layers changes the features learned by these models during the training. Following a hyperparameter search, and contrary to our expectations, we observe no significant improvement in balanced accuracy over fully convolutional models. We also find that important features, such as dermoscopic structures in skin lesion images, are still not learned by employing self-attention. Finally, analyzing local explanations, we confirm biased feature usage. We conclude that merely incorporating attention is insufficient to surpass the performance of existing fully convolutional methods.

Jan Blunk, Niklas Penzel, Paul Bodesheim, Joachim Denzler:
Beyond Debiasing: Actively Steering Feature Selection via Loss Regularization.
DAGM German Conference on Pattern Recognition (DAGM-GCPR).
Pages 394-408.
2023.
[bibtex]
[pdf]
[doi]
[abstract]
It is common for domain experts like physicians in medical studies to examine features for their reliability with respect to a specific domain task. When introducing machine learning, a common expectation is that machine learning models use the same features as human experts to solve a task but that is not always the case. Moreover, datasets often contain features that are known from domain knowledge to generalize badly to the real world, referred to as biases. Current debiasing methods only remove such influences. To additionally integrate the domain knowledge about well-established features into the training of a model, their relevance should be increased. We present a method that permits the manipulation of the relevance of features by actively steering the model's feature selection during the training process. That is, it allows both the discouragement of biases and encouragement of well-established features to incorporate domain knowledge about the feature reliability. We model our objectives for actively steering the feature selection process as a constrained optimization problem, which we implement via a loss regularization that is based on batch-wise feature attributions. We evaluate our approach on a novel synthetic regression dataset and a computer vision dataset. We observe that it successfully steers the features a model selects during the training process. This is a strong indicator that our method can be used to integrate domain knowledge about well-established features into a model.

Niklas Penzel, Jana Kierdorf, Ribana Roscher, Joachim Denzler:
Analyzing the Behavior of Cauliflower Harvest-Readiness Models by Investigating Feature Relevances.
ICCV Workshop on Computer Vision in Plant Phenotyping and Agriculture (CVPPA).
Pages 572-581.
2023.
[bibtex]
[pdf]
[abstract]
The performance of a machine learning model is characterized by its ability to accurately represent the input-output relationship and its behavior on unseen data. A prerequisite for high performance is that causal relationships of features with the model outcome are correctly represented. This work analyses the causal relationships by investigating the relevance of features in machine learning models using conditional independence tests. For this, an attribution method based on Pearl's causality framework is employed.Our presented approach analyzes two data-driven models designed for the harvest-readiness prediction of cauliflower plants: one base model and one model where the decision process is adjusted based on local explanations. Additionally, we propose a visualization technique inspired by Partial Dependence Plots to gain further insights into the model behavior. The experiments presented in this paper find that both models learn task-relevant features during fine-tuning when compared to the ImageNet pre-trained weights. However, both models differ in their feature relevance, specifically in whether they utilize the image recording date. The experiments further show that our approach is able to reveal that the adjusted model is able to reduce the trends for the observed biases. Furthermore, the adjusted model maintains the desired behavior for the semantically meaningful feature of cauliflower head diameter, predicting higher harvest-readiness scores for higher feature realizations, which is consistent with existing domain knowledge. The proposed investigation approach can be applied to other domain-specific tasks to aid practitioners in evaluating model choices.

Niklas Penzel, Joachim Denzler:
Interpreting Art by Leveraging Pre-Trained Models.
International Conference on Machine Vision and Applications (MVA).
Pages 1-6.
2023.
[bibtex]
[doi]
[abstract]
In many domains, so-called foundation models were recently proposed. These models are trained on immense amounts of data resulting in impressive performances on various downstream tasks and benchmarks. Later works focus on leveraging this pre-trained knowledge by combining these models. To reduce data and compute requirements, we utilize and combine foundation models in two ways. First, we use language and vision models to extract and generate a challenging language vision task in the form of artwork interpretation pairs. Second, we combine and fine-tune CLIP as well as GPT-2 to reduce compute requirements for training interpretation models. We perform a qualitative and quantitative analysis of our data and conclude that generating artwork leads to improvements in visual-text alignment and, therefore, to more proficient interpretation models. Our approach addresses how to leverage and combine pre-trained models to tackle tasks where existing data is scarce or difficult to obtain.

Niklas Penzel, Christian Reimers, Paul Bodesheim, Joachim Denzler:
Investigating Neural Network Training on a Feature Level using Conditional Independence.
ECCV Workshop on Causality in Vision (ECCV-WS).
Pages 383-399.
2022.
[bibtex]
[pdf]
[doi]
[abstract]
There are still open questions about how the learned representations of deep models change during the training process. Understanding this process could aid in validating the training. Towards this goal, previous works analyze the training in the mutual information plane. We use a different approach and base our analysis on a method built on Reichenbach’s common cause principle. Using this method, we test whether the model utilizes information contained in human-defined features. Given such a set of features, we investigate how the relative feature usage changes throughout the training process. We analyze mul- tiple networks training on different tasks, including melanoma classifica- tion as a real-world application. We find that over the training, models concentrate on features containing information relevant to the task. This concentration is a form of representation compression. Crucially, we also find that the selected features can differ between training from-scratch and finetuning a pre-trained network.

Christian Reimers, Niklas Penzel, Paul Bodesheim, Jakob Runge, Joachim Denzler:
Conditional Dependence Tests Reveal the Usage of ABCD Rule Features and Bias Variables in Automatic Skin Lesion Classification.
CVPR ISIC Skin Image Analysis Workshop (CVPR-WS).
Pages 1810-1819.
2021.
[bibtex]
[pdf]
[web]
[abstract]
Skin cancer is the most common form of cancer, and melanoma is the leading cause of cancer related deaths. To improve the chances of survival, early detection of melanoma is crucial. Automated systems for classifying skin lesions can assist with initial analysis. However, if we expect people to entrust their well-being to an automatic classification algorithm, it is important to ensure that the algorithm makes medically sound decisions. We investigate this question by testing whether two state-of-the-art models use the features defined in the dermoscopic ABCD rule or whether they rely on biases. We use a method that frames supervised learning as a structural causal model, thus reducing the question whether a feature is used to a conditional dependence test. We show that this conditional dependence method yields meaningful results on data from the ISIC archive. Furthermore, we find that the selected models incorporate asymmetry, border and dermoscopic structures in their decisions but not color. Finally, we show that the same classifiers also use bias features such as the patient's age, skin color or the existence of colorful patches.

Niklas Penzel, Christian Reimers, Clemens-Alexander Brust, Joachim Denzler:
Investigating the Consistency of Uncertainty Sampling in Deep Active Learning.
DAGM German Conference on Pattern Recognition (DAGM-GCPR).
Pages 159-173.
2021.
[bibtex]
[pdf]
[web]
[doi]
[abstract]
Uncertainty sampling is a widely used active learning strategy to select unlabeled examples for annotation. However, previous work hints at weaknesses of uncertainty sampling when combined with deep learning, where the amount of data is even more significant. To investigate these problems, we analyze the properties of the latent statistical estimators of uncertainty sampling in simple scenarios. We prove that uncertainty sampling converges towards some decision boundary. Additionally, we show that it can be inconsistent, leading to incorrect estimates of the optimal latent boundary. The inconsistency depends on the latent class distribution, more specifically on the class overlap. Further, we empirically analyze the variance of the decision boundary and find that the performance of uncertainty sampling is also connected to the class regions overlap. We argue that our findings could be the first step towards explaining the poor performance of uncertainty sampling combined with deep models.
