ELPephants
This webpage contains datasets and supplementary information for the following paper:
M. Körschens and J. Denzler. ELPephants: A Fine-Grained Dataset for Elephant Re-Identification. IEEE International Conference on Computer Vision (ICCV) Workshops. 2019.
You may also refer to our previous paper presenting a system to re-identify elephants using this dataset.
M. Körschens, B. Barz, and J. Denzler. Towards Automatic Identification of Elephants in the Wild. AI for Wildlife Conservation Workshop of IJCAI. 2018.
Description




This elephant dataset was provided by researchers from the Elephant Listening Project (ELP) at the Cornell University Ithaca, who are conducting research on forest elephants visiting the Dzanga bai clearing in the Dzanga-Ndoki National Park in the Central African Republic. It was devised for re-identification of elephants that have been documented before. The images have been taken over a range of about 15 years.
To get a download link for the dataset, please write an e-mail to Daniela Hedwig at dh646(at)cornell(dot)edu stating your name, institution, and acknowledgement of the license terms. For administrative questions or potential cooperations, please contact Joachim Denzler at joachim(dot)denzler(at)uni-jena(dot)de.
Statistics of the datasets
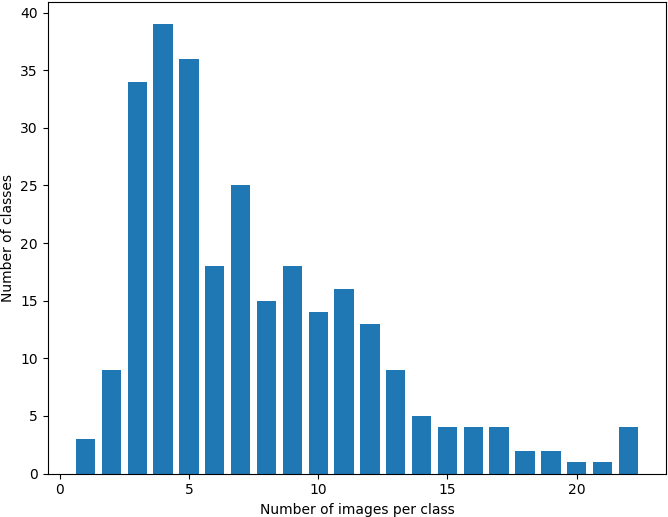
The dataset comprises 2078 images with 276 elephant individuals, i.e. classes. The distribution of the images over the classes is very unequal, as can be seen in the diagram below. We can see that there are many classes with only 3-5 images. The minimum number of images per class is one and the maximum 22. Thus, the dataset is very imbalanced. As the defining features for elephants are very subtle, this dataset can be viewed as a fine-grained classification dataset.It should also be noted that there is a small number of duplicate images in the dataset (~30). This dataset has no overlap with any other computer vision image datasets.
Use of dataset
Files
The dataset is divided into a training and a validation part. For this we did a 75%/25% stratified split, resulting in 1573 training and 505 validation images. Classes with >1 image have at least 1 image in the validation set, classes with only 1 image are only contained in the training set.
Images
The image names consist of an elephant ID separated by an underscore by the rest of the name, e.g. ’15_4th Tuskless VI_Apr2003.jpg’. Usually the ID is an integer, but as we corrected some wrong labels by adding 00 to the ID to designate a different ID for a different elephant, where the actual ID is unknown, parsing these IDs as integers will result in errors. For this, please use either the provided class mapping in the file ‘class_mapping.txt’ from the original IDs to an integer value starting at 0, or create your own mapping.
train.txt and val.txt
These files share the same structure: two columns, separated by a tabulator character (‘\ŧ’), the first of which designates the original ID of the elephant, and the second the name of the image belonging to the class label.
class_mapping.txt
This file consists of two columns, which are separated by a tabulator character (‘\t’), whereas the first column designates the original ID of the elephant and the second column contains the new mapped 0-indexed integer value, which can be used for encoding the classes.
Acknowledgements
We would like to thank the members of the Elephant Listening Project, especially Peter Wrege, for providing us with this dataset and allowing us to make it available to the scientific community. Additionally, we would like to thank Andrea Turkalo and Daniela Hedwig for acquiring the images in this dataset during their work in the Kongo.
License
This dataset is only to be used for non-commercial research purposes. Please find the full license text below.
License Agreement:
-------------------------------------------------------------------------------
Usage of the dataset implies the agreement to the following license terms:
1. This dataset is only to be used for research purposes.
2. Redistribution in any form as well as commercial use is strictly forbidden without explicit agreement of the copyright holders. In case of redistribution, appropriate credit to the copyright holders must be given and this License Agreement must be provided.