Niklas Penzel, Daniel Scheliga, Hannes Oppermann, Patrick Mäder, Jens Haueisen, Joachim Denzler, Marco Seeland:
Model utility and explainability in federated learning - A case study in healthcare using fundus oculi datasets.
Journal of Biomedical Informatics.
177 :
pp. 105010.
2026.
[bibtex]
[web]
[doi]
[abstract]
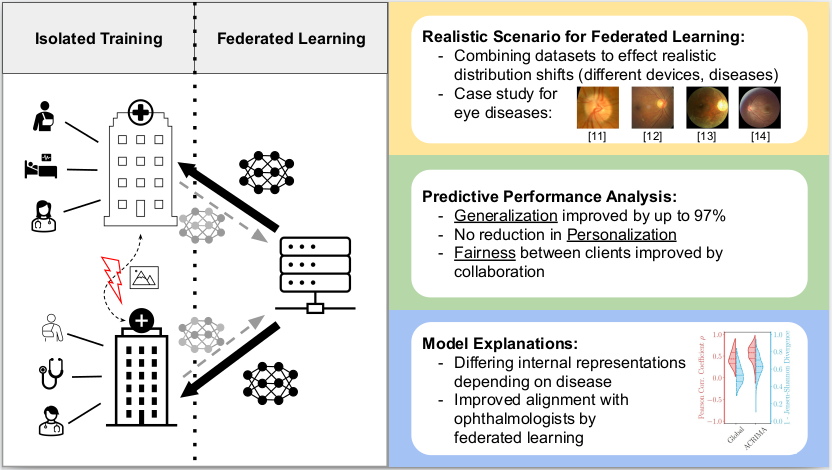
Objective: Introduce a case study for Federated Learning (FL) in healthcare, addressing challenges posed by patient privacy and limited large-scale datasets. Our goal is to assess the features learned by FL methods in a simulated, diverse setting that emphasizes realistic data heterogeneity, and to analyze the learned representations for their medical relevance using both local and global explainability techniques. Methods: Six fundus oculi datasets were combined to simulate a diverse federated learning environment, representing heterogeneous data conditions. We evaluated three established FL methods against centrally trained models, assessing both predictive performance and the learned representations. Specifically, explainability techniques were employed to examine the features learned by the models, and local explanations were evaluated against attention maps annotated by ophthalmologists. Robustness against common biases in fundus datasets was also assessed. Results: Our study found improvements in model utility (up to 9.97%) with FL methods compared to isolated training. Analysis of learned representations revealed that federated models predominantly learn the vertical cup-to-disc ratio, a crucial feature for glaucoma diagnosis, and demonstrated robustness against common biases. High agreement was observed between local explanations and ophthalmologist-annotated attention maps. Conclusion: This study demonstrates the benefits of FL systems in a healthcare scenario, providing a case study for evaluating federated systems beyond idealized benchmarks. Our findings highlight the potential of FL to not only improve model utility in privacy-sensitive medical domains but also to learn medically relevant features instead of spurious correlations.
Niklas Penzel, Joachim Denzler:
Locally Explaining Prediction Behavior via Gradual Interventions and Measuring Property Gradients.
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV).
Pages 7398-7408.
2026.
[bibtex]
[web]
[doi]
[abstract]
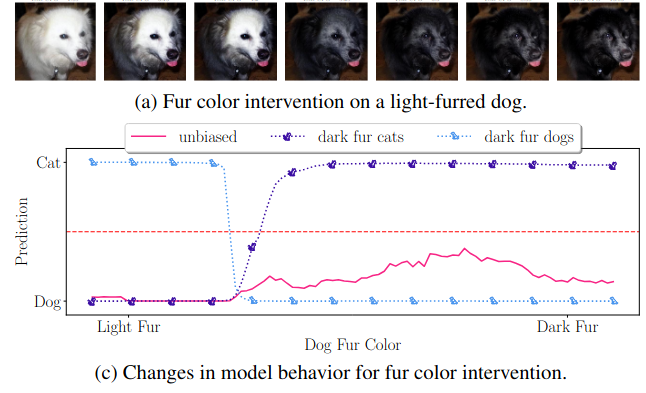
Deep learning models achieve high predictive performance but lack intrinsic interpretability, hindering our understanding of the learned prediction behavior. Existing local explainability methods focus on associations, neglecting the causal drivers of model predictions. Other approaches adopt a causal perspective but primarily provide more general global explanations. However, for specific inputs, it's unclear whether globally identified factors apply locally. To address this limitation, we introduce a novel framework for local interventional explanations by leveraging recent advances in image-to-image editing models. Our approach performs gradual interventions on semantic properties to quantify the corresponding impact on a model's predictions using a novel score, the expected property gradient magnitude. We demonstrate the effectiveness of our approach through an extensive empirical evaluation on a wide range of architectures and tasks. First, we validate it in a synthetic scenario and demonstrate its ability to locally identify biases. Afterward, we apply our approach to analyze network training dynamics, investigate medical skin lesion classifiers, and study a pre-trained CLIP model with real-life interventional data. Our results highlight the potential of interventional explanations on the property level to reveal new insights into the behavior of deep models.

Jan Blunk, Paul Bodesheim, Joachim Denzler:
Adaptive Model Selection for Expanded Post Hoc Debiasing and Mitigating Varying Degrees of Spurious Correlations.
International Conference in Computer Analysis of Images and Patterns (CAIP).
Pages 101-111.
2025.
[bibtex]
[web]
[doi]
[abstract]
Deep neural networks are prone to shortcut bias,where models rely on features that are statistically associated with the target label but lack causal relevance, leading to poor generalization under distribution shifts. To add ress this, debiasing methods aim to improve robustness by reducing reliance on these spurious features. Unfortunately, existing approaches typically assume unbiased test distributions, an idealized scenario that rarely holds in practice. As a result, they often underperform on the original biased distribution when compared with standard empirical risk minimization (ERM) models. We propose a novel Adaptive Model SELection approach for expanding post hoc debiasing called AMSEL, which maintains strong performance across test distributions with varying strength of spurious correlation. Using the fixed feature extractor of the biased model, AMSEL trains a family of lightweight classifier heads on simulated distributions ranging from the original biased data to a fully balanced version. At test time, it estimates the degree of spurious correlation in the test data and selects the most suitable classifier. We validate AMSEL on CelebA and ChestX-ray14, demonstrating that it matches the performance of debiased models under unbiased conditions while preserving the accuracy of the original biased model when spurious correlations are prevalent. AMSEL thus offers an adaptive solution to mitigate the impact of spurious correlations when their strength is either unknown or varies across application environments. Code and models are publicly available at https://github.com/debiasing/AMSEL.

Niklas Penzel, Gideon Stein, Joachim Denzler:
Reducing Bias in Pre-trained Models by Tuning while Penalizing Change.
International Conference on Computer Vision Theory and Applications (VISAPP).
Pages 90-101.
2024.
[bibtex]
[web]
[doi]
[abstract]
Deep models trained on large amounts of data often incorporate implicit biases present during training time. If later such a bias is discovered during inference or deployment, it is often necessary to acquire new data and retrain the model. This behavior is especially problematic in critical areas such as autonomous driving or medical decision-making. In these scenarios, new data is often expensive and hard to come by. In this work, we present a method based on change penalization that takes a pre-trained model and adapts the weights to mitigate a previously detected bias. We achieve this by tuning a zero-initialized copy of a frozen pre-trained network. Our method needs very few, in extreme cases only a single, examples that contradict the bias to increase performance. Additionally, we propose an early stopping criterion to modify baselines and reduce overfitting. We evaluate our approach on a well-known bias in skin lesion classification and three other datasets from the domain shift literature. We find that our approach works especially well with very few images. Simple fine-tuning combined with our early stopping also leads to performance benefits for a larger number of tuning samples.

Tim Büchner, Niklas Penzel, Orlando Guntinas-Lichius, Joachim Denzler:
Facing Asymmetry - Uncovering the Causal Link between Facial Symmetry and Expression Classifiers using Synthetic Interventions.
Asian Conference on Computer Vision (ACCV).
2024.
[bibtex]
[pdf]
[web]
[doi]
[abstract]
Understanding expressions is vital for deciphering human behavior, and nowadays, end-to-end trained black box models achieve high performance. Due to the black-box nature of these models, it is unclear how they behave when applied out-of-distribution. Specifically, these models show decreased performance for unilateral facial palsy patients. We hypothesize that one crucial factor guiding the internal decision rules is facial symmetry. In this work, we use insights from causal reasoning to investigate the hypothesis. After deriving a structural causal model, we develop a synthetic interventional framework. This approach allows us to analyze how facial symmetry impacts a network's output behavior while keeping other factors fixed. All 17 investigated expression classifiers significantly lower their output activations for reduced symmetry. This result is congruent with observed behavior on real-world data from healthy subjects and facial palsy patients. As such, our investigation serves as a case study for identifying causal factors that influence the behavior of black-box models.

Tim Büchner, Niklas Penzel, Orlando Guntinas-Lichius, Joachim Denzler:
The Power of Properties: Uncovering the Influential Factors in Emotion Classification.
International Conference on Pattern Recognition and Artificial Intelligence (ICPRAI).
2024.
[bibtex]
[pdf]
[web]
[doi]
[abstract]
Facial expression-based human emotion recognition is a critical research area in psychology and medicine. State-of-the-art classification performance is only reached by end-to-end trained neural networks. Nevertheless, such black-box models lack transparency in their decisionmaking processes, prompting efforts to ascertain the rules that underlie classifiers' decisions. Analyzing single inputs alone fails to expose systematic learned biases. These biases can be characterized as facial properties summarizing abstract information like age or medical conditions. Therefore, understanding a model's prediction behaviorrequires an analysis rooted in causality along such selected properties. We demonstrate that up to 91.25\% of classifier output behavior changes are statistically significant concerning basic properties. Among those are age, gender, and facial symmetry. Furthermore, the medical usage of surface electromyography significantly influences emotion prediction. We introduce a workflow to evaluate explicit properties and their impact. These insights might help medical professionals select and apply classifiers regarding their specialized data and properties.

Niklas Penzel, Jana Kierdorf, Ribana Roscher, Joachim Denzler:
Analyzing the Behavior of Cauliflower Harvest-Readiness Models by Investigating Feature Relevances.
ICCV Workshop on Computer Vision in Plant Phenotyping and Agriculture (CVPPA).
Pages 572-581.
2023.
[bibtex]
[pdf]
[abstract]
The performance of a machine learning model is characterized by its ability to accurately represent the input-output relationship and its behavior on unseen data. A prerequisite for high performance is that causal relationships of features with the model outcome are correctly represented. This work analyses the causal relationships by investigating the relevance of features in machine learning models using conditional independence tests. For this, an attribution method based on Pearl's causality framework is employed.Our presented approach analyzes two data-driven models designed for the harvest-readiness prediction of cauliflower plants: one base model and one model where the decision process is adjusted based on local explanations. Additionally, we propose a visualization technique inspired by Partial Dependence Plots to gain further insights into the model behavior. The experiments presented in this paper find that both models learn task-relevant features during fine-tuning when compared to the ImageNet pre-trained weights. However, both models differ in their feature relevance, specifically in whether they utilize the image recording date. The experiments further show that our approach is able to reveal that the adjusted model is able to reduce the trends for the observed biases. Furthermore, the adjusted model maintains the desired behavior for the semantically meaningful feature of cauliflower head diameter, predicting higher harvest-readiness scores for higher feature realizations, which is consistent with existing domain knowledge. The proposed investigation approach can be applied to other domain-specific tasks to aid practitioners in evaluating model choices.

Niklas Penzel, Christian Reimers, Paul Bodesheim, Joachim Denzler:
Investigating Neural Network Training on a Feature Level using Conditional Independence.
ECCV Workshop on Causality in Vision (ECCV-WS).
Pages 383-399.
2022.
[bibtex]
[pdf]
[doi]
[abstract]
There are still open questions about how the learned representations of deep models change during the training process. Understanding this process could aid in validating the training. Towards this goal, previous works analyze the training in the mutual information plane. We use a different approach and base our analysis on a method built on Reichenbach’s common cause principle. Using this method, we test whether the model utilizes information contained in human-defined features. Given such a set of features, we investigate how the relative feature usage changes throughout the training process. We analyze mul- tiple networks training on different tasks, including melanoma classifica- tion as a real-world application. We find that over the training, models concentrate on features containing information relevant to the task. This concentration is a form of representation compression. Crucially, we also find that the selected features can differ between training from-scratch and finetuning a pre-trained network.

Christian Reimers, Niklas Penzel, Paul Bodesheim, Jakob Runge, Joachim Denzler:
Conditional Dependence Tests Reveal the Usage of ABCD Rule Features and Bias Variables in Automatic Skin Lesion Classification.
CVPR ISIC Skin Image Analysis Workshop (CVPR-WS).
Pages 1810-1819.
2021.
[bibtex]
[pdf]
[web]
[abstract]
Skin cancer is the most common form of cancer, and melanoma is the leading cause of cancer related deaths. To improve the chances of survival, early detection of melanoma is crucial. Automated systems for classifying skin lesions can assist with initial analysis. However, if we expect people to entrust their well-being to an automatic classification algorithm, it is important to ensure that the algorithm makes medically sound decisions. We investigate this question by testing whether two state-of-the-art models use the features defined in the dermoscopic ABCD rule or whether they rely on biases. We use a method that frames supervised learning as a structural causal model, thus reducing the question whether a feature is used to a conditional dependence test. We show that this conditional dependence method yields meaningful results on data from the ISIC archive. Furthermore, we find that the selected models incorporate asymmetry, border and dermoscopic structures in their decisions but not color. Finally, we show that the same classifiers also use bias features such as the patient's age, skin color or the existence of colorful patches.

Christian Reimers, Paul Bodesheim, Jakob Runge, Joachim Denzler:
Conditional Adversarial Debiasing: Towards Learning Unbiased Classifiers from Biased Data.
DAGM German Conference on Pattern Recognition (DAGM-GCPR).
Pages 48-62.
2021.
[bibtex]
[pdf]
[doi]
[abstract]
Bias in classifiers is a severe issue of modern deep learning methods, especially for their application in safety- and security-critical areas. Often, the bias of a classifier is a direct consequence of a bias in the training set, frequently caused by the co-occurrence of relevant features and irrelevant ones. To mitigate this issue, we require learning algorithms that prevent the propagation of known bias from the dataset into the classifier. We present a novel adversarial debiasing method, which addresses a feature of which we know that it is spuriously connected to the labels of training images but statistically independent of the labels for test images. The debiasing stops the classifier from falsly identifying this irrelevant feature as important. Irrelevant features co-occur with important features in a wide range of bias-related problems for many computer vision tasks, such as automatic skin cancer detection or driver assistance. We argue by a mathematical proof that our approach is superior to existing techniques for the abovementioned bias. Our experiments show that our approach performs better than the state-of-the-art on a well-known benchmark dataset with real-world images of cats and dogs.

Niklas Penzel, Christian Reimers, Clemens-Alexander Brust, Joachim Denzler:
Investigating the Consistency of Uncertainty Sampling in Deep Active Learning.
DAGM German Conference on Pattern Recognition (DAGM-GCPR).
Pages 159-173.
2021.
[bibtex]
[pdf]
[web]
[doi]
[abstract]
Uncertainty sampling is a widely used active learning strategy to select unlabeled examples for annotation. However, previous work hints at weaknesses of uncertainty sampling when combined with deep learning, where the amount of data is even more significant. To investigate these problems, we analyze the properties of the latent statistical estimators of uncertainty sampling in simple scenarios. We prove that uncertainty sampling converges towards some decision boundary. Additionally, we show that it can be inconsistent, leading to incorrect estimates of the optimal latent boundary. The inconsistency depends on the latent class distribution, more specifically on the class overlap. Further, we empirically analyze the variance of the decision boundary and find that the performance of uncertainty sampling is also connected to the class regions overlap. We argue that our findings could be the first step towards explaining the poor performance of uncertainty sampling combined with deep models.

Christian Reimers, Jakob Runge, Joachim Denzler:
Determining the Relevance of Features for Deep Neural Networks.
European Conference on Computer Vision.
Pages 330-346.
2020.
[bibtex]
[abstract]
Deep neural networks are tremendously successful in many applications, but end-to-end trained networks often result in hard to un- derstand black-box classifiers or predictors. In this work, we present a novel method to identify whether a specific feature is relevant to a clas- sifier’s decision or not. This relevance is determined at the level of the learned mapping, instead of for a single example. The approach does neither need retraining of the network nor information on intermedi- ate results or gradients. The key idea of our approach builds upon con- cepts from causal inference. We interpret machine learning in a struc- tural causal model and use Reichenbach’s common cause principle to infer whether a feature is relevant. We demonstrate empirically that the method is able to successfully evaluate the relevance of given features on three real-life data sets, namely MS COCO, CUB200 and HAM10000.

Christian Reimers, Jakob Runge, Joachim Denzler:
Using Causal Inference to Globally Understand Black Box Predictors Beyond Saliency Maps.
International Workshop on Climate Informatics (CI).
2019.
[bibtex]
[pdf]
[doi]
[abstract]
State-of-the-art machine learning methods, especially deep neural networks, have reached impressive results in many prediction and classification tasks. Rising complexity and automatic feature selection make the resulting learned models hard to interpret and turns them into black boxes. Advances into feature visualization have mitigated this problem but some shortcomings still exist. For example, methods only work locally, meaning they only explain the behavior for single inputs, and they only identify important parts of the input. In this work, we propose a method that is also able to decide whether a feature calculated from the input to an estimator is globally useful. Since the question about explanatory power is a causal one, we frame this approach with causal inference methods.